PriorityQueue介绍
在平时的编程工作中似乎很少碰到PriorityQueue(优先队列) ,故很多人一开始看到优先队列的时候还会有点迷惑。优先队列本质上就是一个最小堆。前面一篇文章介绍了堆排序和堆的性质。而堆又是什么呢?它是一个数组,不过满足一个特殊的性质。我们以一种完全二叉树的视角去看这个数组,并用二叉树的上下级关系来映射到数组上面。如果是最大堆,则二叉树的顶点是保存的最大值,最小堆则保存的最小值。
下面是一个典型的优先队列的结构图:
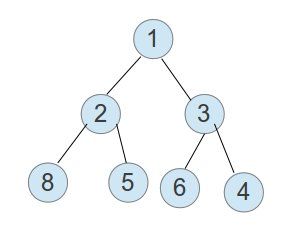
它的每个父节点都比两个子节点要小,但是整个数组又不是完全顺序的。
有了前面的这些铺垫,我们再来看它的整体结构和各种调整过程。
建堆
PriorityQueue内部的数组声明如下:
private transient Object[] queue;
private static final int DEFAULT_INITIAL_CAPACITY = 11;它默认的长度为11. 建堆的过程中需要添加新的元素,
PriorityQueue的建堆过程和最大堆的建堆过程基本上一样的,从有子节点的最靠后元素开始往前,每次都调用siftDown方法来调整。这个过程也叫做heapify。
private void heapify() {
for (int i = (size >>> 1) - 1; i >= 0; i--)
siftDown(i, (E) queue[i]);
}
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
private void siftDownComparable(int k, E x) {
Comparable key = (Comparable)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
((Comparable) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}
private void siftDownUsingComparator(int k, E x) {
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = x;
}
siftDown的过程如下图所示:
因为一开始要建堆的时候,里面的元素是杂乱无章的,所以调整前可能的结构如下:

假设我们siftDown的元素是9,则它先和它的左右子节点进行比较,然后和最小的子节点交换位置:
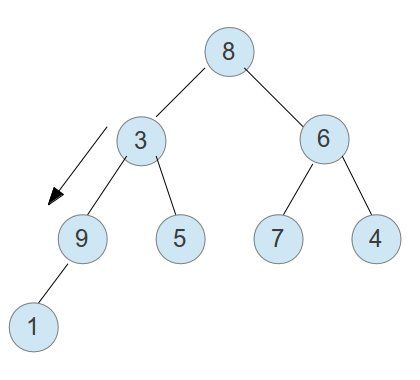
经过一次交换之后,发现它还有子节点,而且子节点比它小,所以需要继续交换。

按照这个思路来理解,前面的过程就很明了了。
扩展
堆里面的数组长度不是固定不变的,如果不断往里面添加新元素的时候,也会面临数组空间不够的情形,所以也需要对数组长度进行扩展。这个扩展方法的源头就是由插入元素引起的。
数组长度扩展的方法如下:
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}这部分代码和ArrayList的内部实现代码基本相同,都是先找到合适的数组长度,然后将元素从旧的数组拷贝到新的数组。
而添加新元素的过程如下:
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}每次添加新的元素进来实际上是在数组的最后面增加。在增加这个元素的时候就有了判断数组长度和调整的一系列动作。等这些动作调整完之后就要进行siftUp方法调整。这样做是为了保证堆原来的性质。
siftUp的过程可以用如下图来描述:

假设我们在后面添加了元素3,那么我们就要将这个元素和它的父节点比较,如果它比它的父节点小,则要交换他们的顺序。这样一直重复到它大于等于它的父节点或者到根节点。
经过调整之后,则变成符合条件的最小堆:‘

它的详细实现代码如下:
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
private void siftUpComparable(int k, E x) {
Comparable key = (Comparable) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}注意事项:
我们看前面的调整方法不管是siftUp还是siftDown都用了两个方法,一个是用的comparator,还有一个是用的默认比较结果。这样做的目的是考虑到我们要比较的元素不仅仅是数字等类型,也有可能是被定义了可比较的数据类型。对于自定义的数据类型,他们的大小比较定义需要实现comparator接口。至于使用comparator接口的意义背后的思想,可以参照我的这一篇博文。
总结
PriorityQueue本质上就是堆排序里面建的最小堆。最小堆满足的一个基本性质是堆顶端的元素是所有元素里最小的那个。如果我们将顶端的元素去掉之后,为了保持堆的性质,需要进行调整。对堆的操作和调整主要包含三个方面,增加新的元素,删除顶端元素和建堆时保证堆性质的操作。前面讨论堆排序的文章已经有了一个详细的介绍。这里主要结合jdk的类库实现,看看一个用于实际生产环境的优先队列实现。 另外,PriorityQueue在一些经典算法中也有得到应用,相当于是它们实现的基础。
参考材料
http://shmilyaw-hotmail-com.iteye.com/blog/1775868