关于Java多线程的一些常考知识点
前言
Java多线程也是面试中经常会提起到的一个点。面试官会问:实现多线程的两种方式以及区别,死锁发生的4个条件以及如何避免发生死锁,死锁和活锁的区别,常见的线程池以及区别,怎么理解有界队列与无界队列,多线程生产者消费者模型,怎么设计一个线程池,线程池的大致实现,ReetrantLock和Synchronized和ReadWriteLock的源码和区别、具体业务场景分析等等。

生产者消费者模型
其实生产者消费者模型挺像观察者模式的,对于该模型我们应该明确以下4点:
* 当生产者生产出产品时,应该通知消费者去消费。
* 当消费者消费完产品,应该通知生产者去生产。
* 当产品的库存满了的时候,生产者不应该再去生产,而是通知消费者去消费。
* 当产品的库存为0的时候,消费者不应该去消费,而是通知生产者去生产。
wait()和notify()实现
- 定义生产者。
public class Producter implements Runnable {
private Storage resource;
public Producter(Storage resource) {
super();
this.resource = resource;
}
@Override
public void run() {
while (true) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
resource.produce();
}
}
}- 定义消费者。
public class Consumer implements Runnable {
private Storage resource;
public Consumer(Storage resource) {
super();
this.resource = resource;
}
@Override
public void run() {
while (true) {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
resource.cosume();
}
}
}
- 定义
Storage仓库。
public class Storage {
private int MAX_SIZE = 20;
private int count = 0;
public synchronized void cosume() {
while (count == 0) {
try {
System.out.println("【消费者】库存已经为空了,暂时不能进行消费任务!");
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
count--;
System.out.println("【消费者】" + Thread.currentThread().getName() + "消费产品, 库存:" + count);
this.notify();
}
public synchronized void produce() {
while (count >= MAX_SIZE) {
try {
System.out.println("【生产者】库存已经满了,暂时不能进行生产任务!");
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
count++;
System.out.println("【生产者】" + Thread.currentThread().getName() + "生产产品, 库存" + count);
this.notify();
}
}
- 测试demo
public class ProducterCosumerXDemo {
public static void main(String[] args) {
Storage storage = new Storage();
ExecutorService service = Executors.newCachedThreadPool();
for (int i = 0; i < 5; i++) {
service.submit(new Producter(storage));
}
for (int i = 0; i < 5; i++) {
service.submit(new Consumer(storage));
}
service.shutdown();
}
}


我们这里创建了5个生产者,5个消费者。生产者生产的速度比消费者消费的速度要快,从图中很明显看到生产者率先生产出20个产品,已是库存极大值,往后不能再去生产了,然后通知消费者去消费。
用BlockingQueue实现
BlockingQueue是一个阻塞队列,也是面试官常喜欢问的一个点。BlockingQueue是线程安全的,内部可以自动调用wait(),notify()方法。在多线程环境下,我们可以使用BlockingQueue去完成数据的共享,同时可以兼顾到效率和线程安全。
如果生产者生产商品的速度远大于消费者消费的速度,并且生产的商品累积到一定的数量,已经超过了BlockingQueue的最大容量,那么生产者就会被阻塞。那为什么时候撤销生产者的阻塞呢?只有消费者开始消费累积的商品,且累积的商品数量小于BlockingQueue的最大容量,才能撤销生产者的阻塞。
如果库存为0的话,消费者自动被阻塞。只有生产者生产出商品,才会撤销消费者的阻塞。
- 定义
Storage仓库
public class Storage {
private BlockingQueue queues = new LinkedBlockingQueue(10);
public void push(Product p) throws InterruptedException {
queues.put(p);
}
public Product pop() throws InterruptedException {
return queues.take();
}
} - 定义
Product商品
public class Product {
private int id;
public static int MAX = 20;
public Product(int id) {
super();
this.id = id;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}- 定义生产者
public class Producer implements Runnable {
private String name;
private Storage storage = null;
public Producer(String name, Storage storage) {
this.name = name;
this.storage = storage;
}
@Override
public void run() {
int i = 0;
try {
while (true) {
System.out.println(name + "已经生产一个: id为" + i + "的商品");
System.out.println("===========================");
Product product = new Product(i++);
storage.push(product);
Thread.sleep(100);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}- 定义消费者
public class Consumer implements Runnable {
private String name;
private Storage storage = null;
public Consumer(String name, Storage s) {
this.name = name;
this.storage = s;
}
@Override
public void run() {
try {
while (true) {
Product product = storage.pop();
System.out.println(name + "已经消费一个: id为" + product.getId() + "的商品");
System.out.println("===========================");
Thread.sleep(500);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}- 测试demo
public class ProducterConsumerDemo {
public static void main(String[] args) {
Storage storage = new Storage();
ExecutorService service = Executors.newCachedThreadPool();
Producer p0 = new Producer("腾讯", storage);
Consumer c0 = new Consumer("cmazxiaoma", storage);
service.submit(p0);
service.submit(c0);
service.shutdown();
}
}
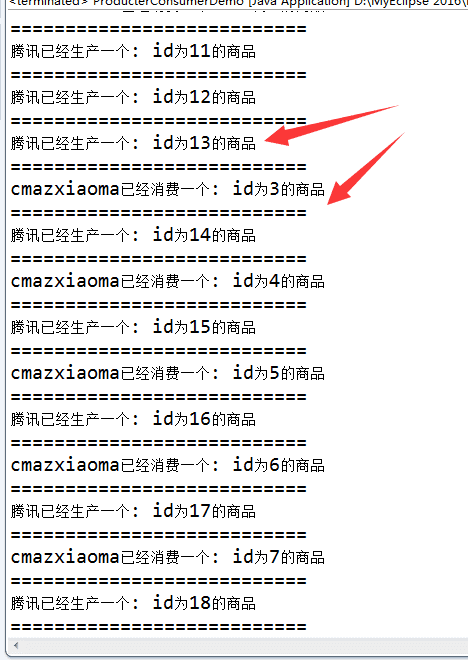
我们可以清晰看到在"腾讯已经生产一个:id为13的商品"之前,生产者是随便的生产,消费者是随便的消费,生产者的速度远远大于消费者的速度。然而在"腾讯已经生产一个:id为13的商品"之后,累积的商品数量已经要到达BlockingQueue的最大容量10了。此时生产者已经被阻塞了,已经不能再生产了,只有当消费者开始产品时,才能唤醒生产者。所以之后的打印内容就很有规律了:腾讯一生产商品,cmazxiaoma就开始消费。
从这个例子中,我们可以看到BlockingQueue通过平衡生产者和消费者的处理能力,因此提高了整体处理数据的速度。
死锁和活锁
死锁:两个或者多个线程相互等待对方释放锁,则会出现循环等待的现象,也就是死锁。
Java虚拟机没有有效的措施去解决死锁情况,所以在多线程编程中应该采用措施去避免死锁的出现。活锁:任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试 -> 失败 -> 尝试 -> 失败。活锁和死锁的区别在于,处于活锁的实体在不断的改变状态。而处于死锁的实体表现为等待,活锁有可能自行解开,死锁则不能。
死锁产生的原因以及四个必要条件
产生死锁的原因:
- 系统资源不足。
- 资源分配不当。
- 进程运行推进的顺序不合适。
发生死锁的必要条件:
互斥条件: 一个资源只能被一个进程占用,直到被该进程释放。
请求和保持条件:一个进程因请求被占用资源而发生阻塞时,对已获得的资源保持不放。
不可剥夺条件:任何一个资源在没被该进程释放之前,任何其他进程都无法对它进行剥夺占用。
循环等待条件:当发生死锁时,所等待的进程必定会发生环路,造成永久阻塞。
防止死锁的一些方法:
破除互斥等待:一般无法做到。
破除请求和保持:一次性获取所有的资源。
破除循环等待:按顺序获取资源。
破除无法剥夺的等待:加入超时机制。
手写死锁的demo
public class DeadLockDemo {
public static String obj1 = "obj1";
public static String obj2 = "obj2";
public static void main(String[] args) {
Thread a = new Thread(new LockThread1());
Thread b = new Thread(new LockThread2());
a.start();
b.start();
}
}
class LockThread1 implements Runnable {
@Override
public void run() {
System.out.println("lockThread1 running");
while (true) {
synchronized (DeadLockDemo.obj1) {
System.out.println("lockThrea1 lock obj1");
try {
Thread.sleep(3000);
synchronized (DeadLockDemo.obj2) {
System.out.println("lockThrea1 lock obj2");
}
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
class LockThread2 implements Runnable {
@Override
public void run() {
System.out.println("lockThread2 running");
while (true) {
synchronized (DeadLockDemo.obj2) {
System.out.println("lockThrea2 lock obj2");
try {
Thread.sleep(3000);
synchronized (DeadLockDemo.obj1) {
System.out.println("lockThrea2 lock obj1");
}
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
很明显,发生了死锁现象,美滋滋。
线程池
首先来说线程的好处。
重用存在的线程,减少对象创建,消亡的开销,性能佳。
可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免阻塞。
提供定时定期执行,单线程,并发数控制等功能。
我们来看看
ThreadPoolExecutor的构造器。
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters and default thread factory.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:
* {@code corePoolSize < 0}
* {@code keepAliveTime < 0}
* {@code maximumPoolSize <= 0}
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
} 通过阅读注释,我们可以知道参数的含义:
* corePoolSize:核心池的大小,默认情况下,在创建线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程来执行任务,在线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列中。
maximumPoolSize:线程池最大的线程数。keepAliveTime:表示线程没有任务执行时,最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize。unit:参数keepAliveTime的时间单位。workQueue:一个阻塞队列,用来存储等待执行的任务。有ArrayBlockingQueue,LinkedBlockingQueue,SynchronousQueue。threadFactory:线程工厂,主要用来创建线程。handler:表示当拒绝处理任务时的策略。我们可以在ThreadPoolExecutor类中,看到4种拒绝策略。AbortPolicy,拒绝处理任务时会抛出一个RejectedExecutionException异常。
/**
* A handler for rejected tasks that throws a
* {@code RejectedExecutionException}.
*/
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}DiscardPolicy,拒绝处理任务时默认丢弃该任务。
/**
* A handler for rejected tasks that silently discards the
* rejected task.
*/
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}DiscardOldestPolicy,去处理拒绝的任务,丢弃最旧的未处理的任务,然后重新执行该任务。除非执行者被关闭,在这种情况下,任务会被丢弃。
/**
* A handler for rejected tasks that discards the oldest unhandled
* request and then retries {@code execute}, unless the executor
* is shut down, in which case the task is discarded.
*/
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardOldestPolicy} for the given executor.
*/
public DiscardOldestPolicy() { }
/**
* Obtains and ignores the next task that the executor
* would otherwise execute, if one is immediately available,
* and then retries execution of task r, unless the executor
* is shut down, in which case task r is instead discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
}CallerRunsPolicy,拒绝的任务由调用线程去处理,除非执行者被关闭,那么拒绝的任务直接丢弃。
/**
* A handler for rejected tasks that runs the rejected task
* directly in the calling thread of the {@code execute} method,
* unless the executor has been shut down, in which case the task
* is discarded.
*/
public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() { }
/**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}- Java通过
Executors提供了4种线程池,分别为:
newCachedThreadPool:创建一个可缓存线程池,里面有我们需要的线程。但是当线程池里面的线程可用的时候,我们可以重用它们。当我们需要执行生命周期很短的任务时,我们将重复使用之前构造的线程处理任务,这样线程池通常能提高性能。如果没有现成的线程可使用,会创建一个新的线程并添加到线程池中。如果有线程在60s中未使用,我们会终结它并把它从缓存中删除。因此一个闲置时间足够长的线程池,将不会消耗任何资源。如果我们需要自定义超时参数,我们可以通过ThreadPoolExecutor进行构建线程池。
/**
* Creates a thread pool that creates new threads as needed, but
* will reuse previously constructed threads when they are
* available. These pools will typically improve the performance
* of programs that execute many short-lived asynchronous tasks.
* Calls to {@code execute} will reuse previously constructed
* threads if available. If no existing thread is available, a new
* thread will be created and added to the pool. Threads that have
* not been used for sixty seconds are terminated and removed from
* the cache. Thus, a pool that remains idle for long enough will
* not consume any resources. Note that pools with similar
* properties but different details (for example, timeout parameters)
* may be created using {@link ThreadPoolExecutor} constructors.
*
* @return the newly created thread pool
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
} newFixedThreadPool:定长线程池,可控制并发数,超出指定数量的线程将在队列中等待。创建一个线程池,重用固定的数量的线程池,使用的是共享的无界队列。在任何时候,至多nThreads线程被激活的处理事务。当所有的线程处于繁忙的状态下,有其他的任务被提交过来,它们会在队列中等待,直到有可用的线程为止。如果任何线程在执行期间由于失败而终止,在shutdown之前,如果有需要的话,将会有新的线程去取代它并执行后续任务。线程池中的存在会一直存在除非明确的进行shutdown。
/**
* Creates a thread pool that reuses a fixed number of threads
* operating off a shared unbounded queue. At any point, at most
* {@code nThreads} threads will be active processing tasks.
* If additional tasks are submitted when all threads are active,
* they will wait in the queue until a thread is available.
* If any thread terminates due to a failure during execution
* prior to shutdown, a new one will take its place if needed to
* execute subsequent tasks. The threads in the pool will exist
* until it is explicitly {@link ExecutorService#shutdown shutdown}.
*
* @param nThreads the number of threads in the pool
* @return the newly created thread pool
* @throws IllegalArgumentException if {@code nThreads <= 0}
*/
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
} newScheduledThreadPool:创建一个线程池,可以调度命令在给定的延迟后运行,或定时执行。其corePoolSize参数是保留在线程池中的线程数量,即使它们闲置。
/**
* Creates a thread pool that can schedule commands to run after a
* given delay, or to execute periodically.
* @param corePoolSize the number of threads to keep in the pool,
* even if they are idle
* @return a newly created scheduled thread pool
* @throws IllegalArgumentException if {@code corePoolSize < 0}
*/
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
/**
* Creates a new {@code ScheduledThreadPoolExecutor} with the
* given core pool size.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @throws IllegalArgumentException if {@code corePoolSize < 0}
*/
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
newSingleThreadExecutor:创建一个使用单线程执行无界队列的Executor。(如果这个单线程在关闭之前的执行期由于失败而终止,如果需要执行后续任务的话,那么新的线程会取代它)可以保证任务保持按顺序进行,并且在任何给定时间不会超过一个任务处于活跃状态。它返回的executor不同于newFixedThreadPool返回的executor。newFixedThreadPool返回的executor保证不需要重新配置,即可使用其他的线程。
/**
* Creates an Executor that uses a single worker thread operating
* off an unbounded queue. (Note however that if this single
* thread terminates due to a failure during execution prior to
* shutdown, a new one will take its place if needed to execute
* subsequent tasks.) Tasks are guaranteed to execute
* sequentially, and no more than one task will be active at any
* given time. Unlike the otherwise equivalent
* {@code newFixedThreadPool(1)} the returned executor is
* guaranteed not to be reconfigurable to use additional threads.
*
* @return the newly created single-threaded Executor
*/
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
} 怎么理解无界队列和有界队列
ArrayBlockingQueue就是一个有界队列,而LinkedBlockingQueue、SynchronousQueue则是无界队列。
SynchronousQueue:它是无界的,是一种无缓冲的等待队列,但是由于该Queue本身的特性,在某次添加元素后必须等待其他线程取走才能继续添加。有2种模式,一个是公平模式,采用的是公平锁,并配合一个FIFO队列(Queue)来管理多余的生产者和消费者。另一个是非公平模式,采用的是非公平锁,并配合一个LIFO(Stack)来管理多余的生产者和消费者,这也是SynchronousQueue默认的模式。后一者模式,如果生产者和消费者的处理速度有差距的话,很容易出现饥渴情况进而导致有些数据得不到处理。(公平锁:加锁前检查是否有排队的线程,优先排队等待的线程,先到先得。 非公平锁:加锁时不考虑排队等待问题,直接尝试获取锁,获取不到自动到队尾等待)LinkedBlockingQueue:它是一个无界的,是一个无界缓存的等待队列。LinkedBlockingQueue之所以能高效的处理并发数据,正因为消费者和生产者分别采用了独立的锁来控制数据的同步,这也意味着在高并发的情况下,生产者和消费者可以并行的操作队列中的数据,以此来提高整个队列的并发性能。
/**
* Tail of linked list.
* Invariant: last.next == null
*/
private transient Node last;
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
private final Condition notFull = putLock.newCondition(); ArrayBlockingQueue:它是有界的,是一个有界缓存的等待队列。内部维护着一个定长数据缓存队列,由数组构成。takeIndex标识着队列的头部,putIndex标识着队列的尾部。ArrayBlockingQueue只有一个主锁,证明生产者和消费者无法并行运行。
/** The queued items */
final Object[] items;
/** items index for next take, poll, peek or remove */
int takeIndex;
/** items index for next put, offer, or add */
int putIndex;
/** Number of elements in the queue */
int count;
/*
* Concurrency control uses the classic two-condition algorithm
* found in any textbook.
*/
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
/**
* Shared state for currently active iterators, or null if there
* are known not to be any. Allows queue operations to update
* iterator state.
*/
transient Itrs itrs = null;无界队列和有界队列其实会给ThreadPoolExecutor造成一定的影响。
* 当corePoolSize = maximumPoolSize下,有界队列也满了的话,那么线程池就会采取拒绝任务策略。
- 与有界队列相比,除非系统资源耗尽,否则无界的任务队列不存在任务入队失败的情况。如果任务创建和处理的速度差异很大,无界队列会快速增长,直到耗尽内存。
ReetrantLock、Synchronized、ReadWriteLock
Lock是jdk1.5引进的,ReetrantLock是jdk1.6引进的。上一次二面机器人公司,就是挂在这里了。面试官让我说说它们的源码实现以及需求场景。
使用场景:
* 当读写频率几乎相等,而且不需要特殊需求的时候,优先考虑synchronized
当我们需要定制我们自己的
Lock时,或者需要更多的功能(类似定时锁,可中断锁等
待),我们可以使用ReetrantLock。当我们很少的进行写操作,更多的读操作,并且读操作是一个相对耗时的操作,那么就可以使用
ReadWriteLock。Synchronized是一种互斥锁。在实际开发中,当某个变量需要在多个线程之间共享的话,需要分析具体场景。如果多个线程对该共享变量的读和写没有竞争关系,则可以使用Concurrent包下提供的并发数据结构。但是如果多个线程对共享变量之间的读和写之间有竞争关系的话,则需要锁住整个变量了。Synchronized是Java内置锁,JVM是通过monitorenter和monitorexit指令实现内置锁。
每个对象都有一个
monitor锁,当monitor被占用时,该对象就处于锁定状态,其他试图访问该对象的线程将会被阻塞。对于同一个线程来说,
monitor是可重入的,重入的时候会将占有数加1。当一个线程试图访问某一个变量时,如果发现该变量的
monitor占有数为0,就可以美滋滋的占用该对象,如果大于等于1的话,那么苦滋滋的进入阻塞状态。执行
monitorexit的线程必须是持有monitor的某一个对象。当执行完这个命令时,如果占用数为0,则当前线程释放monitor。ReetrantLock是基于AQS(AbstractQueuedSynchronizer)的锁。
有一个
state变量,初始值为0,假设当前线程为A,每当A获取一次锁,state++。每当A释放一次锁的时候,state--。当
A拥有锁的时候,state肯定大于0。B线程尝试获取锁的时候,会对这个state有一个CAS(0,1)的操作,尝试几次失败后就挂起线程,进入等待队列。如果
A线程恰好释放锁,state等于0,就会去唤醒等待队列中的B。B被唤醒之后回去检查这个state的值,尝试CAS(0,1),如果这时恰好C线程也尝试争抢这把锁。公平锁的实现,
C发现线程B在等待队列,直接将自己进入等待队列并挂起,然后B获得锁。非公平锁的实现,
C直接尝试CAS(0,1)操作,并成功改变了state的值,B获得锁失败,再次挂起。B在C之前尝试获取锁,而最终C抢到了锁。
参考文章
- synchronized和ReetrantLock的区别
- 什么是Java中的公平锁?
- [有界、无界队列对ThreadPoolExcutor执行的影响](http://blog.csdn.net/kusedexingfu/article/details/72491864)
- Java 四种线程池的用法分析
- 简析SynchronousQueue,LinkedBlockingQueue,ArrayBlockingQueue
Java并发编程:线程池的使用
Java多线程15:Queue、BlockingQueue以及利用BlockingQueue实现生产者/消费者模型
- BlockingQueue
- Java Web技术经验总结(六)
尾言
书山有路勤为径,学海无涯苦作舟。