hadoop详细笔记(十五) MR原理加强(mapreduce内部处理数据流程和shuffle详解)
免费视频教程 https://www.51doit.com/ 或者联系博主微信 17710299606
1 MR内部处理数据流程

- mr程序分为map端和reduce端,来进行处理数据,mr程序在运行的时候最先启动的程序就是MRAppMaster,MRAppMaster是可以读到在job提交的时候的参数信息,所以它可以根据参数信息,来启动对应数量的maptask和reducetask,在maptask启动后,会读取自己对应的任务切片,以逐行读取的方式,一个K,V执行一次map()方法,K为起始偏移量,V为行内容
- 在map()方法执行完一次后,会将数据写入到环形缓冲区中,当环形环形缓冲区中的数据存储达到80%的时候,就会进行分区,排序,然后然后将数据溢出到磁盘当中,剩余20%空间可以继续用来接收数据,如果在20%的空间接收满数据后,仍没有完成分区,排序的工作,那么环形缓冲区就会出现阻塞,防止向缓冲区中写入数据,等到数据.
- 将环形缓冲区中分区排序完的数据,使用的是归并排序算法,写入到本地磁盘当中
- 当这个maptask读取完给自己分配的任务切片的时候,会将存在本地磁盘中的相同分区的文件加载到内存中,进行合并排序.
- 将内存中合并排序完的数据,存入到yarn集群中的某一台nodemanager中,这台nodemanager机器就提供外部服务,以便于reduce可以下载到文件,到这里maptask的工作就结束了
- reducetask会从nodemanager中,以http协议的方式拉去属于自己分区的文件
- 在拉取到所有的文件后,reducetask会将文件,进行合并,排序,然后通过调用GroupingComparator将数据进行分组
- 根据mr程序中自己写的代码逻辑,进行数据运算处理
- 最后将处理完的数据存入到HDFS当中,这样一个mr程序的处理流程就结束了
2 shuffle详解
Mapreduce确保每个reducer的的输入都是按键排序的。系统执行排序的过程(即将map输出作为输入 传给reducer)成为shuffle。从多个方面来看shuffle是mapreduce的心脏,是奇迹发生的地方。
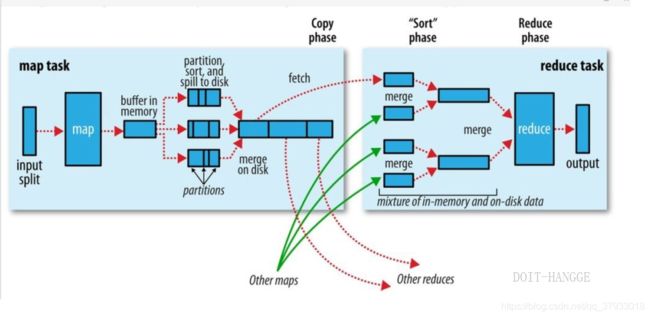
1).Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value序列化数据,Partition分区信息等。
2).Spill 阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
3).Merge 阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
4).Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
5).Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程(一个是内存到磁盘的合并,一个是磁盘到磁盘的合并)对内存到本地的数据文件进行合并操作。
6).Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask 阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可
2.1 任务切片
1 输入分片
对于数据的输入分片,要根据不同的存储格式有不同的介绍。对于,hdfs存储的文件,数据的分片就可分为两种,文件可切分(不压缩或者压缩格式bzip2)的按照一定大小进行分片有既定算法根据输入路径中文件的个数和文件的大小来计算任务切片,一个任务切片就会启动一个MapTask任务去处理对应的数据!
计算逻辑:
由FileInputFormat实现类的getSplits()方法实现切片
默认切片大小就是Block块大小(默认块大小128M)
在FileInputFormat中,计算切片大小的逻辑代码为:
Math.max(minSize, Math.min(maxSize, blockSize));
minsize:默认值:1
配置参数: mapreduce.input.fileinputformat.split.minsize
maxsize:默认值:Long.MAXValue
配置参数:mapreduce.input.fileinputformat.split.maxsize
输入数据有两个文件:
file1.txt 320M
file2.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt.split2-- 0~128
file1.txt.split3-- 128~256
file1.txt.split3-- 256~320
file1.txt.split1-- 0~10M
-
源码中计算切片大小的公式
Math.max(minSize, Math.min(maxSize,blockSize))
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue 默认值Long.MAXValue
切片大小设置:
maxsize(切片最大值):参数如果调的比blockSize小,则会让切片变小,而且就等于配置的这个参数的值
minsize(切片最小值):参数调的比blockSize大,则可以让切片变得比blockSize还大
-
获取切片信息API:
//获取切片的文件名称
String name = inputSplit.getPath().getName();
//根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();
-
ConbineTextInputFormat切片机制:
框架默认的TextInputFormat切片机制是对任务按文件规划切开,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,会产生大量的MapTask
应用场景:ConbineTextInputFormat 用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件可以交给一个MapTask处理
虚拟存储切片最大值设置:
ConbineTextInputFormat.setMaxInputSplitSize(job, 4194304); //4M
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值
2.2 map端

Collect:
每个Map任务不断地以对的形式把数据输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。这个数据结构其实就是个字节数组,叫Kvbuffer
Sort:
先把Kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
Spill:
Spill线程为这次Spill过程创建一个磁盘文件:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于 “spill12.out”的文件。Spill线程根据排过序的Kvmeta挨个partition的把数据吐到这个文件中,一个partition对应的数据吐完之后顺序地吐下个partition,直到把所有的partition遍历 完。一个partition在文件中对应的数据也叫段(segment)。
内存缓冲区是有大小限制的,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
Merge:
Map任务如果输出数据量很大,可能会进行好几次Spill,out文件和Index文件会产生很多,分布在不同的磁盘上。最后把这些文件进行合并的merge过程闪亮登场。如前面的例子,“aaa”从某个map task读取过来时值是5,从另外一个map 读取时值是8,因为它们有相同的key,所以得merge成group。什么是group。对于“aaa”就是像这样的:{“aaa”, [5, 8, 2, …]}
2.3 reduce端
Copy:
Reduce 任务通过HTTP向各个Map任务拖取它所需要的数据。每个节点都会启动一个常驻的HTTP server,其中一项服务就是响应Reduce拖取Map数据。当有MapOutput的HTTP请求过来的时候,HTTP server就读取相应的Map输出文件中对应这个Reduce部分的数据通过网络流输出给Reduce。
Merge SORT:
这里使用的Merge和Map端使用的Merge过程一样。Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的 sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。
当Reducer的输入文件已定,整个Shuffle才最终结束!
集群中往往一个mr任务会有若干map任务和reduce任务,map任务运行有快有慢,reduce不可能等到所有的map任务都运行结束再启动,因此只要有一个任务完成,reduce任务就开始复制器输出。复制线程的数量由mapred.reduce.parallel.copies属性来改变,默认是 5。
Reducer如何知道map输出的呢?对于MRv2 map运行结束之后直接就通知了appmaster,对于给定的job appmaster是知道map的输出和host之间的关系。在reduce端获取所有的map输出之前,Reduce端的线程会周期性的询问master 关于map的输出。Reduce并不会在获取到map输出之后就立即删除hosts,因为reduce有肯能运行失败。相反,是等待appmaster的删除消息来决定删除host。
Reduce对map输出的不同大小也有相应的调优处理。如果map输出相当小,会被复制到reduce任务JVM的内存(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,指定用于此用途的堆空间的百分比),否则,map输出会被复制到磁盘。一旦内存缓冲区达到阈值(由mapred.job.shuffle.merge.percent决定)或达到map的输出阈值(mapred.inmem.merge,threshold控制),则合并后溢出写到磁盘中。如果指定combiner,则在合并期间运行它已降低写入磁盘的数据量。
随着磁盘上副本的增多,后台线程会将它们合并为更大的,排序好的文件。这会为后面的合并节省一些时间。注意,为了合并,压缩的map输出(通过map任务)都必须在内存中解压缩。
复制完所有的map输出后,reduce任务进入排序阶段(更加恰当的说法是合并阶段,因为排序是在map端进行的),这个阶段将合并map的输出,维持其顺序排序。这是循环进行的。比如,有50个map输出,而合并因子是10(默认值是10,由io.sort.factor属性设置,与map的合并类似),合并将进行5趟。每趟将10个文件合并成一个文件,因此最后有5个中间文件。
在最后阶段,即reduce阶段,直接把数据输入reduce函数,从而省略了一次磁盘往返行程,并没有将这5个文件合并成一个已排序的文件最为最后一趟。最后的合并可以来自内存和磁盘片段。
在reduce阶段,对已排序输出中的每个键调用reduce函数。此阶段的输出直接写到输出文件系统,一般为hdfs。