人体姿态2020(三)Self-supervised Learning of Interpretable Keypoints from Unlabelled Videos
《Self-supervised Learning of Interpretable Keypoints from Unlabelled Videos》论文解读
- Abstract
- 1. Introduction
- 2. Related work
-
- 2.1. Full supervision
- 2.2. Weak supervision
- 2.3. No supervision
- 2.4. Adversarial learning
- 3. Method
-
- 3.1. Dual representation of pose & bottleneck
- 3.2. Loss
- 4. Result

原文:Self-supervised Learning of Interpretable Keypoints from Unlabelled Videos
收录:CVPR2020
Abstract
- 实现:仅使用无标记视频(unlabelled videos) 和物体的 弱经验位姿先验(weak empirical prior),实现从单一图像中识别物体的姿态;

视频帧之间的主要区别在于对象的姿态,因此通过分析帧之间的差异可以提炼出姿态信息。这种提炼的机制则是:使用一种物体几何的二重表示:一组2D关节点以及一种图形表示,即骨架图像(uses a new dual representation of the geometry of objects as a set of 2D keypoints, and as a pictorial representation),这样有三大好处:
- 实现从外观解开姿态;
- 可以利用强大的图像到图像的转换网络来在光学和几何学之间进行映射;
- 它允许在学习过程中加入经验位姿先验。
其中,位姿先验是从未配对的数据中获得的,例如从不同的数据集或技术如 mocap(动作捕捉),这样在学习位姿识别网络时就不会使用带注释的图像。
- 优势:在不需要任何标记图像进行训练的方法中达到了最先进的性能。
1. Introduction
在有限或没有外部监督的情况下学习是机器学习中最重要的开放挑战之一。我们所知道,当我们从unlabeled图像中学习时,需要一个合适的监督。在视频中,一个物体通常会保持其固有的外观,只改变姿态。因此,位姿可以通过视频帧之间的差异来学习预测。
因此实现方法则是:① 先从给定的目标视频帧中提取少量的信息,保留姿态信息而放弃外观信息,将该过程称为条件图像生成;② 为了监督,再从提取的姿态重建目标帧,这两步类似一个自动编码器。然而,从只含姿态信息中来重建目标帧是很难的,因为第一步舍去了外观信息,为了重建,必须要传递给生成器第二个视频帧,这样获取外观信息才可以重建。
在本文中,考虑了条件图像生成方法,引入了一个全新的设计模型和 pose bottleneck结构。特别地,我们采用姿态的 二重表示(dual representation) :2D物体坐标的集合以及以骨架图像形式表示的2D坐标的图像表示 ,定义了一个可微骨架生成器来映射从图像表示到关节点坐标,就是总图的 η 、 β \eta 、\beta η、β。
姿态bottleneck结构进一步通过鉴别器控制,反向学习。这样做的好处是在学习过程中注入关于可能的物体姿势的先验信息。虽然获取这个先验可能需要一些监督,但这与用于学习姿态识别器的未标记视频是分开的——也就是说,我们的方法能够利用非成对监督
主要贡献:
- 提出了一种新的条件生成器设计方法:该方法结合图像平移、使用姿态二重表示的bottleneck结构以及对抗损失,极大地提高了识别性能;
- 第一次学会直接预测人类的landmarks,而不需要任何标记;
- 在后期处理中需要使用监督,与使用成对监督的方法相比,本文使用无监督landmark的检测性能更优。
2. Related work
- 对于监督分为三大类:全监督、弱监督以及无监督;
- 对于先验有无,也可分为经验先验,或没有先验,先验模型可以从任何类型的数据或监督中学习得到。
因此,本文方法则是含有经验先验的无监督模型。
2.1. Full supervision
全监督的方法则需要利用大型标注数据集,例如 MS COCO Keypoints、Human3.6M、 MPII 和 LSP。它们通常不使用单独的先验,因为注释本身根据经验捕获一个先验。一些方法使用图形结构来给物体姿态建模。还有一些使用CNN直接回归关节点坐标,或者关节点置信图,或者利用关节点之间的其他关系。另一些人则重复地使用网络来细化单人和多人的热图。
2.2. Weak supervision
一种典型的弱监督方法是Kanazawa等人的方法:他们通过稀疏的2D关节点标注来预测密集的3D人体网格。他们使用两种先验:SMPL参数人体网格模型,以及通过对抗学习从动作捕捉mocap数据获得的3D姿态先验。所有这些方法都使用预先训练过的未配对数据,此外,他们使用成熟的3D先验,如SMPL human或 Basel face models,而本文仅使用实例2D关节点配置形式的经验先验。
2.3. No supervision
其中有一些方法使用 条件图像生成,正如本文所做的。此外,由于本文使用先验,因此能够学习具有“语义意义”的landmarks;相反,那些使用条件图像生成却不使用先验的方法必须依赖一些成对的监督来在无监督和“语义”landmarks之间转换。
2.4. Adversarial learning
由于本文方法与对抗学习有关,因此来从这个方面介绍一下。如今,对抗学习在图像标记和图像生成中被证明是有用的,包括连接真实图像和生成图像之间的域转移。与本文工作最相关的是,Isola等人提出了一种使用配对数据(paired data)的图像到图像的转换框架,而 CycleGAN可以使用非配对数据。本文方法也使用图像到图像的转换网络,但与CycleGAN相比,本文使用条件图像生成解决了一个问题,即骨架不包含足够的信息来生成完整的图像。
3. Method
首要目标是学习一个从包含对象的图像 x 到姿态 y 的映射,为了避免使用图像标注,网络训练时使用自动编码auto-encoder formulation。
![]()
之后再训练一个译码器网络 Ψ \Psi Ψ 从姿态中重构图像,由于姿态缺乏外观信息,重构图像会是病态的,因此,也为解码器提供同一物体的不同图像 x ’ 来输入外观信息。
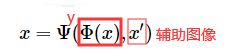
但是如果没有额外的约束,上面这个公式不能正确地学习到姿态信息。原因是:若给予足够的自由,编码器 Φ ( x ) \Phi(x) Φ(x) 可能只是简单让上式输出输入图像 x 的一个副本,只为满足上式,却没有学习到任何有用的东西。因此上式需要一个机制使得得到纯净的 y(即没有外观信息,只有姿态)

为解决上述问题,分两步来进行。① 引入姿态的二重表示,即2D关节点坐标向量和骨架图像形式的图形表示;② 引入经验先验。这样不仅可以约束单个姿态样本y,还可以约束它们的分布p(y)。
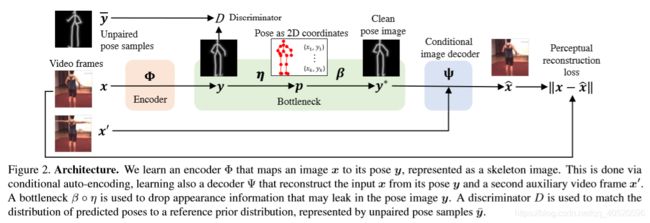

3.1. Dual representation of pose & bottleneck
这节来考虑物体姿态的二重表示,K维2D关节点坐标 p = (p1,…, pK)∈ΩK ,骨架图像 y∈RΩ (其中 Ω = {1,…,H} × {1,…,W} 表示像素坐标的的网格)
用bottleneck结构将姿态表示为一组2D关节点,只保留几何信息,抛弃外观信息;将姿态表示为骨架图像允许将编码器、解码器网络实现为图像转换网络,而且,图像 x 及其骨架图像 y 是空间对齐的,这使得CNN更容易在它们之间进行映射。
接下来将展示如何在姿态的两种表示形式之间进行切换。我们定义从坐标 p 到骨架图像 y 的映射为 y = β ( p ) y=\beta (p) y=β(p)。设 E 为由骨架边连接的关节点对 (i,j) 的集合。
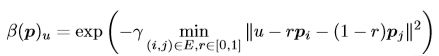
因此,关系转化为:
![]()
3.2. Loss
- Auto-encoding loss:为了学习到自动编码器,本文使用包含N个视频帧样本对的数据集 { ( x i , x i ′ ) } i = 1 N \{(x_{i},x_{i}')\}_{i=1}^{N} { (xi,xi′)}i=1N:

其中 x i ^ \hat{x_{i}} xi^是重构图像, Γ \Gamma Γ是特征提取器,通过例如VGG网络来提取特征进行比较,使训练更具鲁棒性。
- Pose prior:除了N个训练图像对,还用到M个不配对的姿态样本 { p j ˉ } j = 1 M \{\bar{p_{j}}\}_{j=1}^{M} { pjˉ}j=1M,通过M个不配对的姿态样本来鼓励预测的姿态y是真实可信的。原理则是通过匹配两者的分布,假设参考分布 q(y) 通过不匹配样本 { y j ˉ = β ( p j ˉ ) } j = 1 M \{\bar{y_{j}}=\beta (\bar{p_{j}})\}_{j=1}^{M} { yjˉ=β(pjˉ)}j=1M来得到;分布 p(y) 则是通过编码器得到的 { y i = Φ ( x i ) } i = 1 N \{y_{i}=\Phi (x_{i})\}_{i=1}^{N} { yi=Φ(xi)}i=1N,最终目的则是将这两个分布实现 p(y)≈q(y):
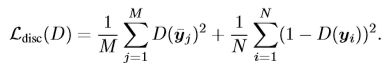
- Overall learning formulation:将前两个损失合并起来
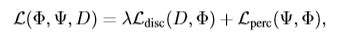
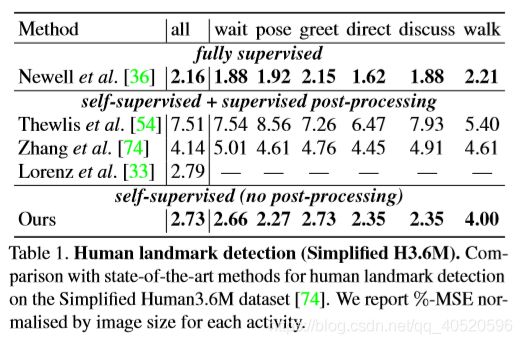
4. Result