java的HashCode equals == 以及hashMap底层实现深入理解
1.==等号
对比对象实例的内存地址(也即对象实例的ID),来判断是否是同一对象实例;又可以说是判断对象实例是否物理相等;(参见:http://kakajw.iteye.com/blog/935226)
2.equals
查看底层object的equals方法 public boolean equals(Object obj) { return (this == obj); }
当对象所属的类没有重写根类Object的equals()方法时 调用==判断 即物理相等
当对象所属的类重写equals()方法(可能因为需要自己特有的“逻辑相等”概念)
equals()判断的根据就因具体实现而异:
如String类重写equals()来判断字符串的值是否相等
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String) anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}首先,如果两个String引用 实际上是指向同一个String对象时(物理相等)则返回true
如果物理不相等,还要判断:通过遍历两个对象底层的char数组,如果每一个字符都完全相等,则认为这两个对象是相等的(逻辑相等)
3.hashCode()
java.lang.Object类的源码中 方法是native的
public native int hashCode();通过将该对象的内部地址转换成一个整数来实现的 ,toString方法也会用到这个hashCode
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}如果覆写了hashCode方法,则情况不一样了
eg. java.lang.String
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
private final char value[];eg.Integer类
public int hashCode() {
return value;
}hashCode()返回的是它值本身
java.lang.Object的约定:
(参见:http://blog.csdn.net/jason_deng/article/details/7074230)
两个对象的equals()方法等同===>两对象hashCode()必相同。
hashCode()相同 不能推导 equals()相等
我的理解是:equals方法是鉴定两个对象逻辑相等的唯一标准
hashCode是对象的散列值 比如不同的ABCDEFGHI对象 它们经过一系列计算得到散列值(右边),不同的对象是可能会有相同的散列值的

hashCode()就是一个提高效率的策略问题 ,因为hashCode是int型的,int型比较运算是相当快的。所以比较两个对象是否相等,可以先比较其hashCode 如果hashCode不相等说明肯定是两个不同的对象。但hashCode相等的情况下,并不一定equals也相等,就再执行equals方法真正来比较两者是否相等
hashCode相等 无法表明equals相等,举例:
比如:"a".hashCode() 结果是97;
new Integer(97).hashCode() 呢?也是97
但new Integer(97).equals("a") 结果是false
(计算方式上面已经阐述了,也可以用代码运行得出结果)
总结:
hashCode()方法存在的主要目的就是提高效率,把对象放到散列存储结构的集合中时,先比hashCode()再比equals
(参见:http://blog.sina.com.cn/s/blog_5396eb5301013ugt.html)
注意:
重写了equals方法则一定要重写hashCode
就像String类一样,equals方法不同于Object的equals,它的hashCode方法也不一样。
为什么:反证一下,如果不重写hashCode,那么两个字符串,不同的对象,但里面的内容是一样的,equals则返回true。但他们的hashCode却返回实例的ID(内存地址)。那么这两个对象的hashCode就不相等了!
违反了上面所说的:equals方法是鉴定两个对象逻辑相等的唯一标准
两个对象的equals()方法等同===>两对象hashCode()必相同。
hashCode()相同 不能推导 equals()相等
因此,重写了equals方法则一定要重写hashCode。保证上面的语句成立
4.HashMap
http://alex09.iteye.com/blog/539545
关于HashMap底层源码,这篇博文介绍的很清楚了
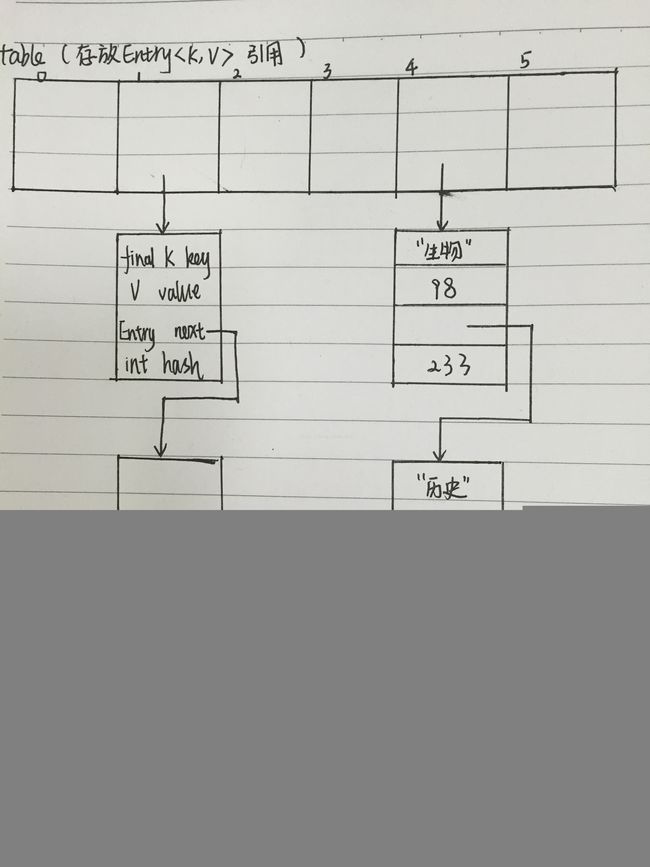
HashMap中维护了一个特别的数据结构,就是Entry
static class Entry implements Map.Entry {
final K key;
V value;
Entry next;
int hash; http://zuoqiang.iteye.com/blog/734842
map.put("英语" , 78.2); -----------------> map.put(Key , Value);
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
} 梳理总结一下:
put方法是:1)对Key的hashCode再运算得到hash值 (Key的hashCode)
2)计算hash值在table中的索引
3)索引处为空,则添加如此对象。
4)如果不为空:
a.遍历索引处的链表,先比较hash值(注意,虽然它们在table的索引相等,不能说明hash相等) 再 真正比较equals 逻辑相等 ==物理相等 如果相等则覆盖之前这个对象的value进行覆盖
b.链表中没有相等的,则将此对象加在这个索引的第一位(链表的头插法)
插入节点的代码
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
} 总结:当程序试图将一个 key-value 对放入 HashMap 中时,程序首先根据该 key 的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry 的 value,但 key 不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部
HashMap大概的样子如下(个人意淫)
另外:
(1)负载因子
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;这个loadFactor就是我们的负载因子,它是怎么用的?我找遍了源码没找到相除然后和loadFactor比较的语句
原来是这样的:
它借助threshold,该变量包含了 HashMap 能容纳的 key-value 对的极限,它的值等于 HashMap 的容量乘以负载因子(load factor)
在addEntry()方法中我们看到
添加之前先比较一下现在的size与threshold,如果超过则resize
如果没有,则成功添加一个元素(key-value对)之后,size都会加1
(2)resize
将会创建原来HashMap大小的两倍的bucket数组,并将原来的对象放入新的bucket数组。(因为新的数组的length变化了,所以计算出来计算hash值在table中的索引也会有改变)。同时,table里面每个坑里面的链表也会倒置过来(自己体会)
重新调整HashMap大小存在什么问题:多线程的情况下,可能产生条件竞争,它们会同时试着调整大小,死循环
======>不应该在多线程的情况下使用HashMap
Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好
比较HashMap和Hashtable:
http://www.importnew.com/7010.html
参考文章:http://blog.csdn.net/Kinger0/article/details/46963741?ref=myread
5.HashSet
HashSet的底层也是醉了 竟然是HashMap
private transient HashMap map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing HashMap instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
} 从源程序看,HashSet只是封装了一个HashMap对象来存储所有的集合元素。所有放入HashSet的值其实就相当于HashMap的Key,而Value是静态final的Object,连注释都要说它是Dummy value......
HashSet的大部分方法都是通过调用HashMap的方法来实现的
剩下的方法总结及HashSet底层还在研究中 未完待续...............
如果以上存在任何错误,欢迎指正