RAID各级别、软RAID
0.目录
- 目录
- RAID
- 1 什么是RAID
- 2 使用场景
- 3 RAID如何提高磁盘耐用性和IO能力
- 4 RAID级别
- RAID各级别组织方式
- 1 RAID-0
- 11 实现方式
- 12 指标及分析
- 2 RAID-1
- 21 实现方式
- 22 指标及分析
- 3 RAID-4
- 31 实现方式
- 32 降级模式
- 33 缺陷
- 4 RAID-5
- 41 实现方式
- 42 指标及分析
- 5 RAID-10
- 51 实现方式
- 52 指标及分析
- 6 RAID-01
- 61 实现方式
- 7 RAID-50
- 71 实现方式
- 8 JBOD概念
- 1 RAID-0
- 软RAID
- 1 mdadm
- 11 使用格式
- 12 各常用模式
- 13 各常用选项
- 2 使用举例
- 21 创建
- 22 查看
- 23 格式化挂载
- 24 冗余测试
- 25 移除坏盘添加好盘
- 26 停用启用删除软RAID
- 1 mdadm
1.RAID
1.1 什么是RAID
RAID,全称Redundant Array Inexpensive(Independent) Disks。这个名称的由来有一定历史原因,不赘述。现在就直接视为磁盘阵列。
磁盘阵列:将多块磁盘,按一定的方式组合起来,以提高耐用性和IO能力。
需要注意的是,RAID有冗余能力提高了耐用性,但取代不了数据备份。因RAID冗余只能保证磁盘坏时数据不受影响,如果数据遭到误删,那和磁盘就没关系了,所以重要数据还是要备份。
1.2 使用场景
1、数据存储在某磁盘上,若该磁盘损坏,则会导致业务终止。
2、磁盘访问密集时,其有限的I/O能力将成为业务瓶颈。
1.3 RAID如何提高磁盘耐用性和I/O能力
RAID耐用性的实现,主要通过磁盘冗余来实现;
RAID使I/O能力的提升,可通过其自带的“CPU”和“内存”(仅供RAID使用),也可理解为是RAID的控制器。
- 通过其“内存”的异步存取可有效提升I/O能力。如果发生断电等会导致异步存取中断。所以RAID一般配有电池,关机后仍可供电一段时间。
- 通过其“CPU”,可将需存取的数据切割为多个chunk(即多份相同大小的数据)。按一定策略(即各RAID级别)存储在各磁盘上,读取时再合并各chunk的数据。这样可降低各磁盘的I/O压力,从而提升整体的I/O能力。
1.4 RAID级别
RAID有不同级别,各级别表示的是其组织各磁盘的方式,并非有级别“高低”之分。
RAID级别的设置在BIOS中,而非操作系统。
2.RAID各级别组织方式
2.1 RAID-0
2.1.1 实现方式
RAID-0,也称条带卷。RAID-0实现方式:
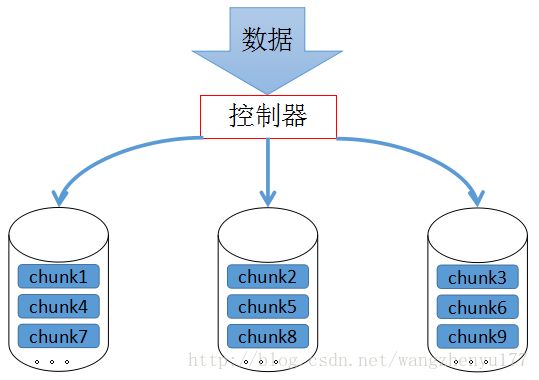
数据存储方式:
各chunk平均、依次分配存储至各磁盘上,即把整个数据条带化存储了。
2.1.2 指标及分析
| 指标 | 产生结果(提升、下降均相对于单硬盘) |
|---|---|
| I/O能力 | 提升 |
| 耐用性 | 下降 |
| 使用的最少硬盘数 | 2 |
| 可用空间 | N*min(Disk1,Disk2……) |
分析:
- I/O能力
以上述图示为例,如果数据的总大小为9G,每个硬盘仅需吞吐(即I/O)3G的数据,相对于单硬盘,RAID-0的每个硬盘I/O压力明显降低。
使用更多的磁盘,就会更多地分摊I/O压力。不过并不是添加硬盘越多就越好。因为读取时,控制器需要时间合并各磁盘读来的数据;写入时又要费时间来分割数据。 - 耐用性
由RAID-0组织方式,可以看出其无冗余能力。任何一块硬盘损坏,就会造成整个数据的不完整,而多个硬盘出故障的概率又大于单硬盘。所以RAID-0耐用性相对于单硬盘是降低的。
所以RAID-0不适合存储关键数据。可用于存储非关键的“中间数据”,比如交换分区数据、临时文件系统等。 - 最少硬盘数
由RAID-0组织方式,可知其最少使用2块硬盘。 - 可用空间
RAID-0可用空间取决于其组成硬盘中最小的那个。因为根据RAID-0写入数据的方式,任何一块盘满,其他硬盘也无法再写入。
2.2 RAID-1
2.2.1 实现方式
RAID-1,也称镜像卷。RAID-1实现方式:

数据存储方式:
各chunk,每个硬盘都存一份,如同镜像。
2.2.2 指标及分析
| 指标 | 产生结果(提升、下降均相对于单硬盘) |
|---|---|
| I/O能力 | 写性能略微下降;读性能提升 |
| 耐用性 | 提升 |
| 存储空间利用率 | 50%以下 |
| 使用的最少硬盘数 | 最少为2,且一般也只用2块硬盘 |
| 可用空间 | 1*min(Disk1,Disk2…) |
分析:
- I/O能力
RAID-1各硬盘存储的数据相同,在写入时,数据在所有硬盘上都完整存储才算写入完成,所以虽然每个硬盘的写入压力相同,但RAID-1整体写性能取决于最慢的那个硬盘。相对于单硬盘写性能是略有下降的。
读性能提升。读取各chunk不一定要在一块硬盘上。比如chunk1在第一块读,chunk2在第二块读等等。从而降低各硬盘读取压力,RAID-1整体读性能提升。 - 耐用性
有冗余能力,也是其最大优点。每个硬盘都存储数据,只要不同时损坏,数据即可正常读写。耐用性提升。 - 存储空间利用率
有冗余的RAID级别,存储空间利用率都不会是100%。
RAID-1若使用2块盘,利用率为50%;使用更多则会在50%以下。因各硬盘数据都一样。 - 使用最少硬盘数
由其组织方式决定,最少硬盘数为2,且一般就使用2个。如果使用2个以上,除了存储空间利用率降低,写性能也会进一步降低,因为写入数据时要等所有硬盘都写入完毕。 - 可用空间
各硬盘存储的数据大小一致,所以只要其中1块硬盘满,其他硬盘均无法继续写入。且各硬盘存储的内容相同。所以可用空间为1*min(Disk1,Disk2…)。
2.3 RAID-4
2.3.1 实现方式
RAID-4实现方式:

数据存储方式:
前面硬盘按条带卷存储各chunk,最后一块硬盘作为校验盘,存储前面硬盘数据计算得出的校验码(比如按位计算出的异或值)。如果存储数据的某硬盘损坏,校验盘可和剩下的正常硬盘数据计算,得出损坏盘上的数据1。
2.3.2 降级模式
- 什么是降级模式
以RAID-4为例,一块硬盘坏了之后,读、写仍是可以执行的。读的话,需要边计算边读,速度会比较慢;写的话,也是边计算边写到没坏的硬盘和校验盘上。
这种存在坏硬盘的情况下继续工作的状态称为降级模式。 - 降级模式的风险及规避
显然,降级模式下的读、写操作会增大剩余好硬盘和校验盘的压力。对于RAID-4,处于降级模式时如果再坏一块硬盘(也可以是校验盘),那么就彻底坏了。
所以在出现硬盘故障时,应暂停使用RAID,换一块新硬盘(一般是热备一块空闲盘)并计算出原来硬盘的数据。这样就和原来状态一样了。
不过,在计算原来硬盘数据的过程中也有可能出现新的坏盘(概率很小),对于RAID-4,这种情况也就意味着彻底坏了,RAID-4最多允许一块坏盘。
2.3.3 缺陷
RAID-4的一大缺陷:单块盘作为校验盘,任何一个存数据的盘写入数据,校验盘的数据都要跟着变。这大大增加了校验盘的压力,使之成为RAID-4的性能瓶颈。
所以RAID-4不常用。
2.4 RAID-5
2.4.1 实现方式

数据存储方式:
RAID-5存储原理与RAID-4相同。不过为了避免RAID-4单个校验盘的压力,RAID-5采用了各硬盘轮流存储校验值的方式。
校验数据从第一块盘开始存储,之后各硬盘依次做校验盘,称为左对衬。如上图所示就是左对衬的方式(虚线标出)。相反地,校验数据若从最后一块盘开始,依次向前轮流做校验盘,称为右对称。一般采用左对衬。
2.4.2 指标及分析
| 指标 | 产生结果(提升、下降均相对于单硬盘) |
|---|---|
| I/O能力 | 提升 |
| 耐用性 | 提升 |
| 存储空间利用率 | (N-1)/N以下,其中N为硬盘总数 |
| 使用的最少硬盘数 | 最少3个 |
| 可用空间 | (N-1)*min(Disk1,Disk2…) |
分析:
- I/O能力
每个硬盘仅存储数据的一部分,所以I/O压力减小,RAID总体I/O能力提升。 - 耐用性
同RAID-4,最多允许一块硬盘挂掉,挂掉后即变为降级模式。2块以上挂掉则彻底挂。 - 可用空间
最小的一块硬盘满,则RAID-5无法继续存储数据。且校验数据大小相当于其中一块硬盘。所以可用空间为(N-1)*min(Disk1,Disk2…)。
2.5 RAID-10
2.5.1 实现方式
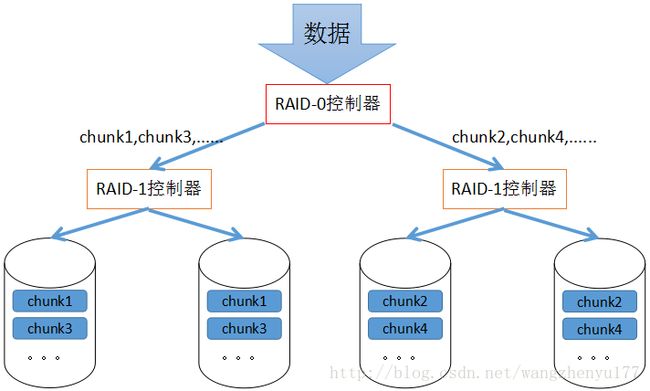
数据存储方式:
各硬盘先分组做RAID-1,各组再在更高级别上做RAID-0。
2.5.2 指标及分析
| 指标 | 产生结果(提升、下降均相对于单硬盘) |
|---|---|
| I/O能力 | 提升 |
| 耐用性 | 提升 |
| 存储空间利用率 | 50%以下 |
| 使用的最少硬盘数 | 4个 |
| 可用空间 | N*min(Disk1,Disk2…)/2 |
分析:
- I/O能力
每个硬盘仅存储数据的一部分,所以I/O压力减小,RAID总体I/O能力提升。 - 耐用性
除非某组镜像卷的硬盘同时坏,否则数据不会损坏。镜像卷包含硬盘较少,同时坏的可能性不大。
RAID-10是相对理想的机制。
2.6 RAID-01
2.6.1 实现方式
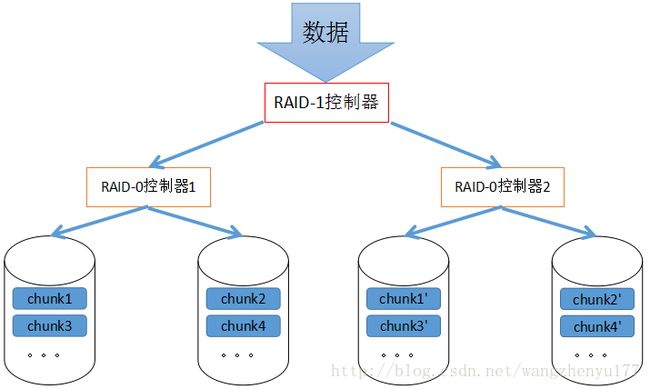
数据存储方式:
用若干硬盘先做RAID-0,再用同样数量的硬盘,在更高级别上做RAID-1。
两边的RAID-0存储的总数据一样,但由于两边RAID-0控制器对数据的切片方式未必相同,所以两边的切片结果未必相同(上图中使用chunk1、chunk1一撇以示区分),所以两边的RAID-0若各有一个硬盘坏,则整个数据就会损坏。
虽然这种方式可以在某一边RAID-0的全部硬盘坏的情况下,仍保存完整数据,但发生这种情况概率较低。反而是两边各坏一块硬盘的概率较高(两边都是一堆里面坏一个)。
整体来看,RAID-01不如RAID-10。
2.7 RAID-50
2.7.1 实现方式
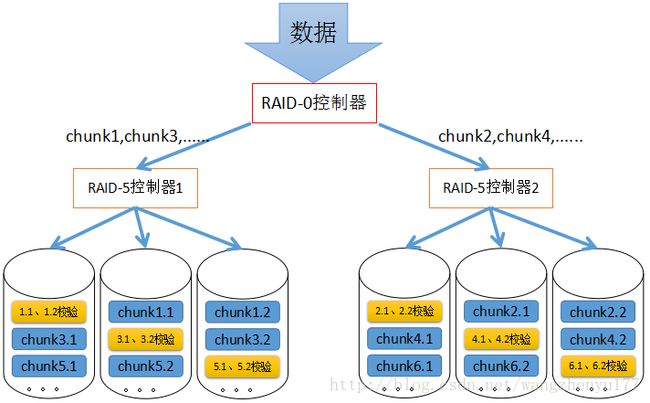
数据存储方式:
各硬盘先分组做RAID-5,各组再在更高级别上做RAID-0。
2.8 JBOD概念
这里仅作为了解。
Just a Bunch Of Disks,仅是一组硬盘的捆绑。
顾名思义,JBOD逻辑上是把一堆硬盘合起来当做一个磁盘来用(这点同RAID),但它没有提升I/O能力和耐用性,功能仅是结合各硬盘存储空间,即其可用空间为sum(Disk1,Disk2…)。存储数据方式是前一个硬盘满就继续存储在后一个上。
3.软RAID
3.1 mdadm
3.1.1 使用格式
RAID也可通过软件实现,但生产环境中肯定都是硬件实现。不过以下使用软RAID使用举例,可对RAID有更清晰的理解。
软件实现RAID是基于内核中的MD(Multi Devices)模块。
centos6上,使用系统命令mdadm来与该模块通信,它具有不同模式。使用格式为:
mdadm [mode] [options] | 各字段 | 意义 |
|---|---|
| mode | 指定模式。 |
| raiddevice | 指定RAID设备2 |
| options | 选项。对于不同模式,可用的选项不同。 |
| component-devices | 组成RAID的成员设备。 |
3.1.2 各常用模式
| 各模式 | 符号 | 意义 |
|---|---|---|
| 创建 | -C | 用于创建(create) |
| 显示 | -D | 显示设备详细信息(detail) |
| 监控 | -F | |
| 管理 | 无 | 该模式无需指定,使用某些选项默认就是在管理模式下。 |
| 停止 | -S | 停止指定RAID,释放所有资源。 |
| 装配 | -A | 装配(assemble)一个已存在的阵列3 |
3.1.3 各常用选项
创建模式下
选项 意义 -n # 指定多少块设备创建RAID(#为数字,下同) -l # 指定创建的RAID级别(level)4 -a {yes|no} 指定是否自动(auto)创建RAID的设备文件 -c 指定RAID的chunk的大小,比如512K -x # 指定备用的空闲盘的个数5 管理模式下
选项 意义 -a 添加磁盘 -r 移除磁盘 -f 标记磁盘为损坏
3.2 使用举例
3.2.1 创建
比如创建一个10G可用空间,3块盘组成的RAID-5,另有1块空闲盘备用。共需4硬盘。
创建4个分区当作硬盘,注意分区ID应为fd(Linux raid auto),否则无法装配为RAID。创建分区结果:
[root@local ~]# fdisk -l /dev/sdb Disk /dev/sdb: 107.4 GB, 107374182400 bytes 255 heads, 63 sectors/track, 13054 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x6f7a5b9a Device Boot Start End Blocks Id System /dev/sdb1 1 654 5253223+ fd Linux raid autodetect /dev/sdb2 655 1308 5253255 fd Linux raid autodetect /dev/sdb3 1309 1962 5253255 fd Linux raid autodetect /dev/sdb4 1963 13054 89096490 5 Extended /dev/sdb5 1963 2616 5253223+ fd Linux raid autodetect查看/proc/mdstat(显示当前系统所有RAID设备),或查看所有/dev/md#文件,以添加新RAID设备文件时,避免和已有的设备文件名重复。
[root@local ~]# cat /proc/mdstat Personalities : unused devices:# 表示目前系统上没有RAID设备 使用mdadm创建RAID-5。chunk大小未指定,表示使用默认大小。
[root@local ~]# mdadm -C /dev/md0 -n 3 -x 1 -l 5 -a yes /dev/sdb{1,2,3,5} mdadm: /dev/sdb1 appears to contain an ext2fs file system size=3156740K mtime=Sun Dec 4 15:29:29 2016 Continue creating array? y mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started.仍在/proc/mdstat查看是否创建完毕。
[root@local ~]# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] md0 : active raid5 sdb3[4] sdb5[3](S) sdb2[1] sdb1[0] 10498048 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU] unused devices:active表示该RAID处于活动(可用)状态;
如有recovery正在执行及其执行的百分比6,表示组成RAID的各设备正在逐位对齐7。至此,RAID-5创建完成,可把该RAID在逻辑上看做为一个设备了。
3.2.2 查看
创建完成后,可使用显示模式,查看该软RAID详细信息。
[root@local ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Mon Jan 23 22:06:37 2017
Raid Level : raid5
Array Size : 10498048 (10.01 GiB 10.75 GB)
Used Dev Size : 5249024 (5.01 GiB 5.38 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Mon Jan 23 22:07:11 2017
State : clean # clean表示目前软RAID状态正常
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric # 表示该RAID-5使用左对称的方式
Chunk Size : 512K
Name : local:0 (local to host local)
UUID : e50fa76a:477feeb3:c23cdc50:8a415bb4
Events : 18
Number Major Minor RaidDevice State
0 8 17 0 active sync /dev/sdb1
1 8 18 1 active sync /dev/sdb2
4 8 19 2 active sync /dev/sdb3
3 8 21 - spare /dev/sdb53.2.3 格式化、挂载
格式化
[root@local ~]# mke2fs -t ext4 /dev/md0 mke2fs 1.41.12 (17-May-2010) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=128 blocks, Stripe width=256 blocks 657072 inodes, 2624512 blocks 131225 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=2688548864 81 block groups 32768 blocks per group, 32768 fragments per group 8112 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632 Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 30 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.挂载
[root@local ~]# mount /dev/md0 test_md [root@local ~]# mount | grep /dev/md0 /dev/md0 on /root/test_md type ext4 (rw)
注意,如上所提到的,如果想让其开机自动挂载,最好使用UUID或卷标来指定这个RAID,因为RAID的设备文件的数字在重启后可能会改变。
3.2.4 冗余测试
向该软RAID挂载的目录下拷贝一个文件,后续验证是否损坏。
[root@local ~]# echo hello > test_md/hello [root@local ~]# cat test_md/hello hello使用指令,人为标记组成该软RAID的某设备损坏。
[root@local ~]# mdadm /dev/md127 -f /dev/sdb1 mdadm: set /dev/sdb1 faulty in /dev/md127 # 由于重启过机器,该软RAID的设备文件发生改变了,变为md127了。 # 此处是把/dev/sdb1标记为损坏。此时查看软RAID的状态。
损坏设备时立即查看,可以看到数据正在重建(rebuild)及重建的进度百分比。
[root@local ~]# mdadm -D /dev/md127 /dev/md127: Version : 1.2 Creation Time : Mon Jan 23 22:06:37 2017 Raid Level : raid5 Array Size : 10498048 (10.01 GiB 10.75 GB) Used Dev Size : 5249024 (5.01 GiB 5.38 GB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Wed Feb 1 20:21:34 2017 State : clean, degraded, recovering # 此时坏了一个设备,备用的设备在恢复(recovering)数据,所以只有两块可用,是降级(degraded)模式 Active Devices : 2 Working Devices : 3 Failed Devices : 1 Spare Devices : 1 Layout : left-symmetric Chunk Size : 512K Rebuild Status : 17% complete Name : local:0 (local to host local) UUID : e50fa76a:477feeb3:c23cdc50:8a415bb4 Events : 28 Number Major Minor RaidDevice State 3 8 21 0 spare rebuilding /dev/sdb5 1 8 18 1 active sync /dev/sdb2 4 8 19 2 active sync /dev/sdb3 0 8 17 - faulty /dev/sdb1备用盘重建数据完成后再次查看软RAID信息,可看到备用的/dev/sdb5完全替代了/dev/sdb1,其他信息均和损坏前一样。
[root@local ~]# mdadm -D /dev/md127 /dev/md127: Version : 1.2 Creation Time : Mon Jan 23 22:06:37 2017 Raid Level : raid5 Array Size : 10498048 (10.01 GiB 10.75 GB) Used Dev Size : 5249024 (5.01 GiB 5.38 GB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Wed Feb 1 20:22:20 2017 State : clean Active Devices : 3 Working Devices : 3 Failed Devices : 1 Spare Devices : 0 Layout : left-symmetric Chunk Size : 512K Name : local:0 (local to host local) UUID : e50fa76a:477feeb3:c23cdc50:8a415bb4 Events : 43 Number Major Minor RaidDevice State 3 8 21 0 active sync /dev/sdb5 1 8 18 1 active sync /dev/sdb2 4 8 19 2 active sync /dev/sdb3 0 8 17 - faulty /dev/sdb1此时查看软RAID挂载点下的文件,未损坏。
[root@local ~]# cat test_md/hello hello
再标记一个设备损坏,使软RAID变为降级模式,并查看状态和挂载点下的文件。
[root@local ~]# mdadm /dev/md127 -f /dev/sdb2 mdadm: set /dev/sdb2 faulty in /dev/md127 # 标记损坏 [root@local ~]# mdadm -D /dev/md127 | grep "State :" State : clean, degraded # 查看软RAID状态 [root@local ~]# mdadm -D /dev/md127 | tail -n 7 Number Major Minor RaidDevice State 3 8 21 0 active sync /dev/sdb5 2 0 0 2 removed 4 8 19 2 active sync /dev/sdb3 0 8 17 - faulty /dev/sdb1 1 8 18 - faulty /dev/sdb2 # 组成软RAID各设备的状态 [root@local ~]# cat test_md/hello hello # 降级模式不影响数据
3.2.5 移除坏盘,添加好盘
标记为坏盘的设备,在重启后会自动被移除出软RAID;也可通过命令,直接移除。
[root@local ~]# mdadm /dev/md127 -r /dev/sdb{1,2}
mdadm: hot removed /dev/sdb1 from /dev/md127
mdadm: hot removed /dev/sdb2 from /dev/md127然后可再添加好盘,上述的/dev/sdb{1,2}并不是真的故障,所以再添加进去也没有问题。软RAID的状态也恢复为正常。
[root@local ~]# mdadm /dev/md127 -a /dev/sdb{1,2}
mdadm: added /dev/sdb1
mdadm: added /dev/sdb2
[root@local ~]# mdadm -D /dev/md127 | grep "State :"
State : clean3.2.6 停用、启用、删除软RAID
当软RAID不再使用时,可停用。停用前应先卸载,否则会报错。
[root@local ~]# umount /dev/md127
[root@local ~]# mdadm -S /dev/md127
mdadm: stopped /dev/md127
[root@local ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
unused devices: 如果软RAID设备文件还在可使用装配模式重新启用;
如需删除软RAID,把所有组成设备移除即可。
(完)
- 比如chunk1数据为1101,chunk2数据为0110,它们的异或值是1011。如果chunk1坏了,使用它们的异或值,和chunk2再做一次异或即可得出chunk1原来的1101。 ↩
- RAID设备文件一般为/dev/md#,在重启后数字可能会改变,所以一般通过卷标、UUID来指定RAID设备。 ↩
- 一个软RAID停用后,再想启用时,需使用装配模式。此处的装配可理解为启用。 ↩
- mdadm支持的级别:LINEAR(即JBOD)、RAID-0、RAID-1、RAID-4、RAID-5、RAID-6、RAID-10。 ↩
- 显然,只有有冗余能力的RAID级别,指定空闲盘才有意义。 ↩
- 使用cat查看的百分比显然会是一个固定的数字,使用命令watch可动态查看其完成进度。 ↩
- RAID的存储尤其是有冗余能力的RAID,各硬盘要逐位对齐,否则出现坏盘时无法按位计算坏盘上的数据。 ↩