这节依然是关于时间方面的知识.
上一节学习了如何获取日期序列的函数, 以及通过一些基本的参数设置可以使时间序列跳过休息日等.
这一节, 将要深入学习这个点, 做更自定义的设计.
通过上一节的学习, 我们知道了如何获取一个时间段的序列, 那我们很容易就可以得到 2019年2月1日到2月28日的所有工作日的时间序列:
import pandas as pd
pd.date_range(start='2/1/2019', end='2/28/2019', freq='B') 输出:
DatetimeIndex(['2019-02-01', '2019-02-04', '2019-02-05', '2019-02-06', '2019-02-07', '2019-02-08', '2019-02-11', '2019-02-12', '2019-02-13', '2019-02-14', '2019-02-15', '2019-02-18', '2019-02-19', '2019-02-20', '2019-02-21', '2019-02-22', '2019-02-25', '2019-02-26', '2019-02-27', '2019-02-28'], dtype='datetime64[ns]', freq='B') 那我们现在得到的就是 2019年2月的所有工作日, 但是其实在美国 2019年2月18日是华盛顿诞辰日 Washington's Birthday (President's Day), 也就是说这一天不能算成工作日, 所以 date_range()函数的第三个参数 freq 现有的几个选项值都无法满足这个需求, 而 Pandas 也提供了这种自定义的空间:
from pandas.tseries.holiday import USFederalHolidayCalendar from pandas.tseries.offsets import CustomBusinessDay usb = CustomBusinessDay(calendar = USFederalHolidayCalendar()) pd.date_range(start='2/1/2019', end='2/28/2019', freq=usb) 输出:
DatetimeIndex(['2019-02-01', '2019-02-04', '2019-02-05', '2019-02-06', '2019-02-07', '2019-02-08', '2019-02-11', '2019-02-12', '2019-02-13', '2019-02-14', '2019-02-15', '2019-02-19', '2019-02-20', '2019-02-21', '2019-02-22', '2019-02-25', '2019-02-26', '2019-02-27', '2019-02-28'], dtype='datetime64[ns]', freq='C') 先来看输出结果, 果然 '2019-02-18' 被略过了. 其实, 代码中每个函数的名字取得都非常好, 基本就是见字知意了, 我这里就不赘述了(如果有不明白的可以留言).
但是特别说下这个函数 --- USFederalHolidayCalendar() 美国联邦假期日历函数, 得益于 Pandas 自带的这个函数, 我们很轻松地获取到了美国实际的工作日数据. 那么是不是其他国家也都有这个函数呢? 答案是否定的, 不过没关系, 我们可以根据这个函数的源码, 依葫芦画瓢, 自定义我们想要的任何日历. 下面是 Pandas 的 github 地址, 大家找到如下图的源码, 拷贝一下:
https://github.com/pandas-dev/pandas/blob/master/pandas/tseries/holiday.py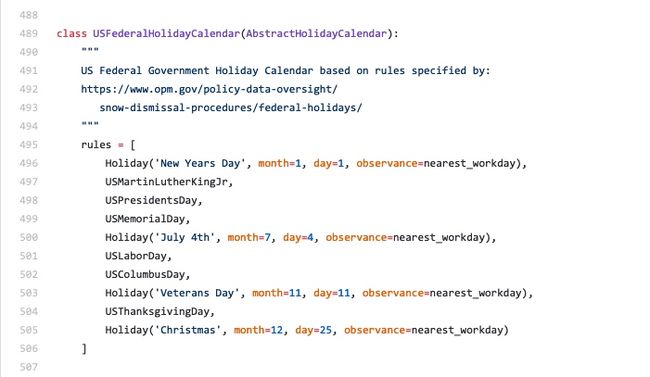
源码的代码很简单, 对假日的定义主要就是体现在 holiday() 函数里. 下面来实践一下, 比如我的生日是4月20日, 我要把这一天自定义到4月的休息日里:
from pandas.tseries.holiday import AbstractHolidayCalendar, nearest_workday, Holiday class myBirthdayCalendar(AbstractHolidayCalendar): rules = [ Holiday('Rachel"s Birthday', month=4, day=20) ] myc = CustomBusinessDay(calendar = myBirthdayCalendar()) pd.date_range(start='4/1/2018', end='4/30/2018', freq=myc) 输出:
DatetimeIndex(['2018-04-02', '2018-04-03', '2018-04-04', '2018-04-05', '2018-04-06', '2018-04-09', '2018-04-10', '2018-04-11', '2018-04-12', '2018-04-13', '2018-04-16', '2018-04-17', '2018-04-18', '2018-04-19', '2018-04-23', '2018-04-24', '2018-04-25', '2018-04-26', '2018-04-27', '2018-04-30'], dtype='datetime64[ns]', freq='C') 另外, 大家在看 USFederalHolidayCalendar() 的源代码时, 应该已经注意到 holiday() 函数的第三个参数 observance=nearest_workday, 这个参数的意思就是说, 如果刚好节日的那天也是周六的话, 那么就把周五定为休息日, 如果刚好节日的那天也是周日的话, 就把下周一定为休息日, 也就是不能白过节的意思, 哈哈哈. 不知道我表达清楚了没有, 如果还是有点迷糊, 就动手时间一下, 对照日历看下就明白了. 我这里暂且把生日改为4月21日, 刚好那天是周六, 但是我加上这个参数 -- observance=nearest_workday:
from pandas.tseries.holiday import AbstractHolidayCalendar, nearest_workday, Holiday class myBirthdayCalendar(AbstractHolidayCalendar): rules = [ Holiday('Rachel"s Birthday', month=4, day=21, observance=nearest_workday) ] myc = CustomBusinessDay(calendar = myBirthdayCalendar()) pd.date_range(start='4/1/2018', end='4/30/2018', freq=myc) 输出:
DatetimeIndex(['2018-04-02', '2018-04-03', '2018-04-04', '2018-04-05', '2018-04-06', '2018-04-09', '2018-04-10', '2018-04-11', '2018-04-12', '2018-04-13', '2018-04-16', '2018-04-17', '2018-04-18', '2018-04-19', '2018-04-23', '2018-04-24', '2018-04-25', '2018-04-26', '2018-04-27', '2018-04-30'], dtype='datetime64[ns]', freq='C') 从输出可以看出, 2018-04-20 也被划为休息日了. OK, 继续......
大多数国家的工作日都是从周一到周五, 但是也有不一样的, 比如埃及的工作日就是从周日到周四, 所以, 我们又要自定义了:
b = CustomBusinessDay(weekmask='Sun Mon Tue Wed Thu') pd.date_range(start='4/1/2018', end='4/30/2018', freq=b) 输出:
DatetimeIndex(['2018-04-01', '2018-04-02', '2018-04-03', '2018-04-04',
'2018-04-05', '2018-04-08', '2018-04-09', '2018-04-10',
'2018-04-11', '2018-04-12', '2018-04-15', '2018-04-16',
'2018-04-17', '2018-04-18', '2018-04-19', '2018-04-22',
'2018-04-23', '2018-04-24', '2018-04-25', '2018-04-26',
'2018-04-29', '2018-04-30'],
dtype='datetime64[ns]', freq='C')
那比方说, 其中的某一天或者几天又是法定节假日呢? 简单:
b = CustomBusinessDay(weekmask='Sun Mon Tue Wed Thu', holidays=['2018-04-15']) pd.date_range(start='4/1/2018', end='4/30/2018', freq=b) 输出:
DatetimeIndex(['2018-04-01', '2018-04-02', '2018-04-03', '2018-04-04', '2018-04-05', '2018-04-08', '2018-04-09', '2018-04-10', '2018-04-11', '2018-04-12', '2018-04-16', '2018-04-17', '2018-04-18', '2018-04-19', '2018-04-22', '2018-04-23', '2018-04-24', '2018-04-25', '2018-04-26', '2018-04-29', '2018-04-30'], dtype='datetime64[ns]', freq='C') 综上, 我们可以看到 Pandas 真的非常强大, 它有各种各样的参数, 通过不同的设置, 取值, 可谓是花样玩转数据分析.