HashMap使用和原理分析(以及HashMap内存优化)
HashMap、HashTable、ConcurrentHashMap使用和原理分析(以及内存优化)
哈希码
每个对象和基本类型都有的一个方法 hashCode() 可以获取其hashCode
默认是 对象的地址经过hash算法转换的整数
String aa = "123";
String bb = "456";
String cc = "123";
String dd = aa;
aa、cc、dd的hashCode均为 48690 bb为51669
hash值相等 对象不一定一致
对象一致 hash值一定相等
因为他是一个散列算法
equals和== 比较的是对象的地址 只有是同一个对象才返回true
只是String这种 重写了equals方法 只要同一个对象或者值相等就返回true
而Hash相关的数据结构 如HashMap就是根据键对象的hash值来进行存放
HashMap
概念:
容量(capacity ): 默认16 一个桶中的容量
加载因子(load factor): 默认0.75 即桶中的可利用大小
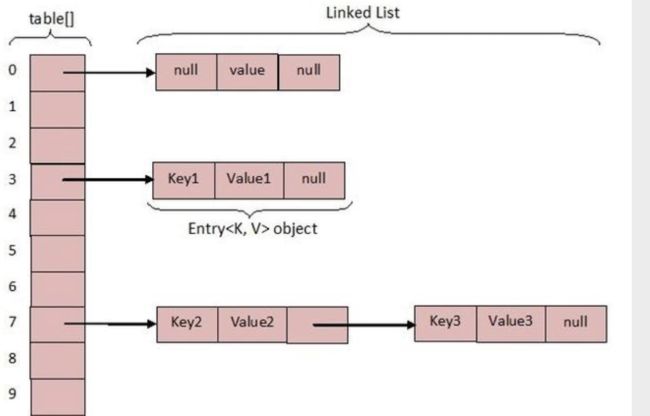
链地址法:(开散列方法):设散列表地址空间的位置从0~m-1,则通过对所有的Key用散列函数(hashCode())计算出存放的位置,具有相同地址的关键码归于一个子集合(桶),在同一个Bucket中的键值对对象采用链表的方式链接起来
HashMap非线程安全的 HashTable线程安全,但是他是锁住整个整个table,ConcurrentHashMap也是线程安全的,锁的是segment
HashMap时间复杂度
若美好的状态下没有hash冲突 每个桶只有一个元素时间复杂度 O(1) ,最差是O(n) 红黑树则是O(logn)
HashMap原理(数据结构)/HashMap怎么解决冲突的: 通过链地址法存放键值对的一种数据结构
根本:数组 + 链表(jdk1.7)/数组+链表+红黑树(jdk1.8)(当链表长度超过阈值(8)将链表转为红黑树 时间复杂度降低为O(logn))
计算key的hash值,每个桶对应一个hash值,若发生了hash冲突,则将相同的元素作为链表的一个节点放到链表中
HashMap怎么扩容: 根据容量*加载因子的大小,若达到了这个大小,则会自动扩容2倍。jdk1.8在长度达到了8个时,还会升级为红黑树 (扩容是很耗时的)
HashMap的问题
1 当地址不够大时,HashMap会采用扩大当前空间两倍的方式去增大空间,而且在此过程中也需要不断的做hash运算,数据获取时也是通过遍历方式获取数据
2 当hash冲突较多,则链表会过长,遍历时间会过长
常见使用
构造函数
HashMap()
Constructs an empty HashMap with the default initial capacity (16) and the default load factor (0.75).
HashMap(int initialCapacity)
Constructs an empty HashMap with the specified initial capacity and the default load factor (0.75).
HashMap(int initialCapacity, float loadFactor)
Constructs an empty HashMap with the specified initial capacity and load factor.
1 size()
获取map的大小
2 isEmpty()
返回map 是否为空
3 get(Object key)
根据key返回value
4 containsKey(Object key)
根据key是否存在返回true or false
5 put(K key,V value)
装载 键值对
对于put进了相同的key而不同的values。则后面的values会覆盖前面的values
6 putAll(Map< ? extends K,? extends V> m)
将形参的map的全部键值对传递给当前定义的map作为当前map的键值对
7 remove(Object key)
根据Key 移除 map中该键值对数据
8 clear()
清除map中所有数据
9 public Set keySet()
获取map中所有的key(key的遍历)
Set (集合中各元素唯一的)
for (String key : map.keySet()) {
System.out.println("key= "+ key);
}
或者
Set keySet = map.keySet();
System.out.println(keySet);
10 public Collection values()
返回map中所有的values (values的遍历)
for (String v : map.values()) {
System.out.println("value= " + v);
}
11 遍历map
for (Map.Entry entry : map.entrySet()) {
System.out.println("key:"+entry.getKey() + ", value:" + entry.getValue());
}
12 public boolean remove(Object key,Object value)
移除键值对返回布尔值
13 replace(K key,V value)
替换键值对
Android中对HashMap的优化
1 通过 SparseArray稀疏数组的方式去节省内存空间
注意: key是为int 形式!!!
SparseArray: 由两个数组 分别存放key 和 values
并且 key的存放为int形式,减少了装箱操作,采取了压缩的方式来表示稀疏数组的数据,并且通过二分查找方式去装载和读取数据
使用:
SparseArray array = new SparseArray<>();
1 delete(int key) 或者 remove(int key)
移除key 对应的数据
2 get(int key)
获取key对应的键值对
3 put(int key, E value)
添加键值对
4 append(int key, E value)
也是添加键值对,若添加的键是按顺序递增的,则更推荐使用该方式,因为可以提高性能。
5 size()
获取SparseArray 大小
参考,官方文档:https://developer.android.com/reference/android/util/SparseArray.html
HashTable
基本原理和HashMap类似
只是用Synchronized对对象加了锁,锁住的都是对象整体,线程安全的,key和value都不允许传null
效率低
ConcurrentHashMap
基本原理与HashMap类似
但是是线程安全的 key和value都不允许传null
与HashTable锁住整个对象不同,ConcurrentHashMap有一个Segment(作为每个数组的元素)的概念,只对每个Segment加lock,锁住的是put方法