【RLchina第二讲】 Foundations of Reinforcement Learning
文章目录
- 策略方法
-
-
-
- VI
- PI
- VI and PI: 收敛性分析
- Q learning
- n-step transition probability: an example
-
-
- Computational learning theory
-
-
-
- Probably Approximately Correct (PAC) learning
-
-
- 理论分析
-
-
-
- **Learning bound for finite H - consistent case**:
- **Learning bound for finite H: inconsistent Case**
-
-
- Theoretical analysis
-
-
-
- Performance bounds of AVI(值迭代的bound)
- Performance bounds of API(策略迭代的bound)
- Performance bounds of BRM
- Sample-based ADP: sample complexity
-
-
所有强化学习的方法无外乎两个近似的东西:
一个是sample的性质,我们不可能把所有的state-action遍历,就有function approximation的方法。而近似的方法,会衍生出另外一个问题,sample complex的问题,需要多少数据能够达到什么样的一个精确程度。这个就是大部分理论分析的一个出发点。
策略方法
policy有两种:1. deterministic policy a : = π ( s ) a:=\pi(s) a:=π(s)。2. randomized policy p r ( a ∣ s ) = π ( a ∣ s ) p_{r}(a|s)=\pi(a|s) pr(a∣s)=π(a∣s)。policy的目的是最大化奖励,奖励也有不同地定义形式:
- total reward MDP over a finite horizon
J ( π ) : = E [ ∑ k = 0 N R ( s k , π ( s k ) ) ] J(\pi):=\mathbb{E}\left[\sum_{k=0}^{N} R\left(s_{k}, \pi\left(s_{k}\right)\right)\right] J(π):=E[k=0∑NR(sk,π(sk))]
- discounted reward MDP over an infinite horizon
J ( π ) : = E [ ∑ k = 0 ∞ γ k R ( s k , π ( s k ) ) ] , for 0 < γ < 1 J(\pi):=\mathbb{E}\left[\sum_{k=0}^{\infty} \gamma^{k} R\left(s_{k}, \pi\left(s_{k}\right)\right)\right], \text { for } 0<\gamma<1 J(π):=E[k=0∑∞γkR(sk,π(sk))], for 0<γ<1
- average reward MDP over an infinite horizon (ergodic reward)
J ( π ) = lim K → ∞ E [ 1 K + 1 ∑ k = 0 K R ( s , π ( s ) ) ] J(\pi)=\lim _{K \rightarrow \infty} \mathbb{E}\left[\frac{1}{K+1} \sum_{k=0}^{K} R(s, \pi(s))\right] J(π)=K→∞limE[K+11k=0∑KR(s,π(s))]
想要获得这样的policy有两个核心的问题:
- 怎么衡量policy的好坏? (policy evaluation)
policy evaluation value function: the expected discounted rewards under a policy π \pi π starting from state s s s:
V π ( s ) : = E [ ∑ k = 0 ∞ γ k R ( s k , π ( s k ) ) ∣ s 0 = s ] V^{\pi}(s):=\mathbb{E}\left[\sum_{k=0}^{\infty} \gamma^{k} R\left(s_{k}, \pi\left(s_{k}\right)\right) \mid s_{0}=s\right] Vπ(s):=E[k=0∑∞γkR(sk,π(sk))∣s0=s]
and the corresponding action-value function (Q function), the expected reward of taking a particular action, under a policy
Q π ( s ) : = R ( s , π ( s ) ) + E s ′ ∼ Pr ( s ′ ∣ s , π ( s ) ) [ V ⋆ ( s ′ ) ] Q^{\pi}(s):=R(s, \pi(s))+\mathbb{E}_{s^{\prime} \sim \operatorname{Pr}\left(s^{\prime} \mid s, \pi(s)\right)}\left[V^{\star}\left(s^{\prime}\right)\right] Qπ(s):=R(s,π(s))+Es′∼Pr(s′∣s,π(s))[V⋆(s′)]
- 最优的策略怎么获取?(policy optimisation)
policy optimisation the value function optimising the policy gives the optimal value function,
V ⋆ ( s ) : = max π E [ ∑ k = 0 ∞ R ( s k , π ( s k ) ) ∣ s 0 = s ] V^{\star}(s):=\max _{\pi} \mathbb{E}\left[\sum_{k=0}^{\infty} R\left(s_{k}, \pi\left(s_{k}\right)\right) \mid s_{0}=s\right] V⋆(s):=πmaxE[k=0∑∞R(sk,π(sk))∣s0=s]
By the same token, the optimal Q function is
Q ⋆ ( s ) : = max a R ( s , a ) + E s ′ ∼ Pr ( s ′ ∣ s , a ) [ V π ( s ′ ) ] Q^{\star}(s):=\max _{a} R(s, a)+\mathbb{E}_{s^{\prime} \sim \operatorname{Pr}\left(s^{\prime} \mid s, a\right)}\left[V^{\pi}\left(s^{\prime}\right)\right] Q⋆(s):=amaxR(s,a)+Es′∼Pr(s′∣s,a)[Vπ(s′)]
如果知道state transition和reward function,我们就可以用DP的方法来做,如果是model-free的话,就用RL。值函数又可以分解为两部分,即时奖励和对下一个状态的估计。
V π ( s ) = E [ γ 0 R ( s 0 , π ( s 0 ) ) ∣ s 0 = s ] + E [ ∑ k = 1 ∞ γ k R ( s k , π ( s k ) ) ∣ s 0 = s ] = R ( s , π ( s ) ) + E s ′ ∼ Pr ( s ′ ∣ s , π ( s ) ) [ ∑ k = 1 ∞ γ k R ( s k , π ( s k ) ) ∣ s 1 = s ′ ] = R ( s , π ( s ) ) + γ ∑ s ′ Pr ( s ′ ∣ s , a ) E [ ∑ k = 0 ∞ γ k R ( s k , π ( s k ) ) ∣ s 0 = s ′ ] \begin{aligned} V^{\pi}(s) &=\mathbb{E}\left[\gamma^{0} R\left(s_{0}, \pi\left(s_{0}\right)\right) \mid s_{0}=s\right]+\mathbb{E}\left[\sum_{k=1}^{\infty} \gamma^{k} R\left(s_{k}, \pi\left(s_{k}\right)\right) \mid s_{0}=s\right] \\ &=R(s, \pi(s))+\mathbb{E}_{s^{\prime} \sim \operatorname{Pr}\left(s^{\prime} \mid s, \pi(s)\right)}\left[\sum_{k=1}^{\infty} \gamma^{k} R\left(s_{k}, \pi\left(s_{k}\right)\right) \mid s_{1}=s^{\prime}\right] \\ &=R(s, \pi(s))+\gamma \sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, a\right) \mathbb{E}\left[\sum_{k=0}^{\infty} \gamma^{k} R\left(s_{k}, \pi\left(s_{k}\right)\right) \mid s_{0}=s^{\prime}\right] \end{aligned} Vπ(s)=E[γ0R(s0,π(s0))∣s0=s]+E[k=1∑∞γkR(sk,π(sk))∣s0=s]=R(s,π(s))+Es′∼Pr(s′∣s,π(s))[k=1∑∞γkR(sk,π(sk))∣s1=s′]=R(s,π(s))+γs′∑Pr(s′∣s,a)E[k=0∑∞γkR(sk,π(sk))∣s0=s′]
最终可以得到策略 π \pi π下的贝尔曼方程:
V π ( s ) = R ( s , π ( s ) ) + γ ∑ s ′ Pr ( s ′ ∣ s , π ( s ) ) V π ( s ′ ) V^{\pi}(s)=R(s, \pi(s))+\gamma \sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, \pi(s)\right) V^{\pi}\left(s^{\prime}\right) Vπ(s)=R(s,π(s))+γs′∑Pr(s′∣s,π(s))Vπ(s′)
已知转移概率 p r ( s ′ ∣ s , a ) p_{r}(s^{\prime}|s,a) pr(s′∣s,a)和回报函数就可以迭代计算值函数:

在值迭代的时候引入max,我们就间接引入了策略的求解,也成为贝尔曼最优方程:
V ⋆ ( s ) = max a ∈ A R ( s , a ) + γ ∑ s ′ Pr ( s ′ ∣ s , a ) V ⋆ ( s ′ ) V^{\star}(s)=\max _{a \in \mathbb{A}} R(s, a)+\gamma \sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, a\right) V^{\star}\left(s^{\prime}\right) V⋆(s)=a∈AmaxR(s,a)+γs′∑Pr(s′∣s,a)V⋆(s′)
由贝尔曼方程和贝尔曼最优方程衍生出了两种迭代算法,值迭代和策略迭代:
VI

值迭代是最优策略下计算最优值函数 V ∗ V^{*} V∗。有了最优的值函数,依据贝尔曼最优方程就可以计算得到最优策略:
a ⋆ = π ⋆ ( s ) = arg max a ∈ A R ( s , a ) + γ ∑ s ′ Pr ( s ′ ∣ s , a ) V ⋆ ( s ′ ) a^{\star}=\pi^{\star}(s)=\underset{a \in \mathbb{A}}{\arg \max } R(s, a)+\gamma \sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, a\right) V^{\star}\left(s^{\prime}\right) a⋆=π⋆(s)=a∈AargmaxR(s,a)+γs′∑Pr(s′∣s,a)V⋆(s′)
PI

在策略迭代中,先计算某个策略下的值函数,收敛之后再去求新的policy。
VI and PI: 收敛性分析
在求证VI和PI的收敛性分析的时候有一个很重要的工具operator,贝尔曼方程或者贝尔曼最优方程可以用operator来表示:
T π V ( s ) : = R ( s , a ) + γ ∑ s ′ Pr ( s ′ ∣ s , a ) V ( s ′ ) , ∀ s T V ( s ) : = max a ∈ A R ( s , a ) + γ ∑ s ′ Pr ( s ′ ∣ s , a ) V ( s ′ ) ∀ s \begin{aligned} T^{\pi} V(s) &:=R(s, a)+\gamma \sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, a\right) V\left(s^{\prime}\right), \forall s \\ T V(s) &:=\max _{a \in \mathbb{A}} R(s, a)+\gamma \sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, a\right) V\left(s^{\prime}\right) \forall s \end{aligned} TπV(s)TV(s):=R(s,a)+γs′∑Pr(s′∣s,a)V(s′),∀s:=a∈AmaxR(s,a)+γs′∑Pr(s′∣s,a)V(s′)∀s
operator是function到function的映射,可以将值函数 V ( s ) V(s) V(s)转成另外一个函数 T V ( s ) TV(s) TV(s)。这种映射满足两点性质:
- monotonicity(单调):如果对任意 s s s,有 V ( s ) ≥ U ( s ) V(s) \geq U(s) V(s)≥U(s),那么:
T π V ( s ) ≥ T π U ( s ) T V ( s ) ≥ T U ( s ) \begin{array}{c} T^{\pi} V(s) \geq T^{\pi} U(s) \\ T V(s) \geq T U(s) \end{array} TπV(s)≥TπU(s)TV(s)≥TU(s)
- 单调性证明:
由 T π V ( s ) ≥ T π U ( s ) T^{\pi} V(s) \geq T^{\pi} U(s) TπV(s)≥TπU(s)可知:
T π V ( s ) − T π U ( s ) = ∑ s ′ Pr ( s ′ ∣ s , π ( s ) ) ( V ( s ′ ) − U ( s ′ ) ) ≥ 0 T^{\pi} V(s)-T^{\pi} U(s)=\sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, \pi(s)\right)\left(V\left(s^{\prime}\right)-U\left(s^{\prime}\right)\right) \geq 0 TπV(s)−TπU(s)=s′∑Pr(s′∣s,π(s))(V(s′)−U(s′))≥0
由 T π V ( s ) T^{\pi} V(s) TπV(s)的定义,将其展开即可得到:
R ( s , a ) + ∑ s ′ Pr ( s ′ ∣ s , a ) V ( s ′ ) ≥ R ( s , a ) + ∑ s ′ Pr ( s ′ ∣ s , a ) U ( s ′ ) R(s, a)+\sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, a\right) V\left(s^{\prime}\right) \geq R(s, a)+\sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, a\right) U\left(s^{\prime}\right) R(s,a)+s′∑Pr(s′∣s,a)V(s′)≥R(s,a)+s′∑Pr(s′∣s,a)U(s′)
- contraction(收缩):
∥ T π V − T π U ∥ ∞ ≤ γ ∥ V − U ∥ ∞ ∥ T V − T U ∥ ∞ ≤ γ ∥ V − U ∥ ∞ \begin{aligned} \left\|T^{\pi} V-T^{\pi} U\right\|_{\infty} & \leq \gamma\|V-U\|_{\infty} \\ \|T V-T U\|_{\infty} & \leq \gamma\|V-U\|_{\infty} \end{aligned} ∥TπV−TπU∥∞∥TV−TU∥∞≤γ∥V−U∥∞≤γ∥V−U∥∞
从原空间到映射空间,两点之间的距离是收缩的。收缩的约束是折扣因子 γ \gamma γ,假设其中一个值函数是最优的,那么他们就会越来越近。
- 压缩映射证明:
∥ T π V − T π U ∥ ∞ ≤ γ ∥ V − U ∥ ∞ \left\|T^{\pi} V-T^{\pi} U\right\|_{\infty} \leq \gamma\|V-U\|_{\infty} ∥TπV−TπU∥∞≤γ∥V−U∥∞展开有:
∥ T π V − T π U ∥ ∞ = max s γ ∑ s ′ Pr ( s ′ ∣ s , π ( s ) ) ∣ V ( s ′ ) − U ( s ′ ) ∣ ≤ γ ( ∑ s ′ Pr ( s ′ ∣ s , π ( s ) ) ) max s ′ ∣ V ( s ′ ) − U ( s ′ ) ∣ ≤ γ ∥ U − V ∥ ∞ \begin{array}{c} \left\|T^{\pi} V-T^{\pi} U\right\|_{\infty}=\max _{s} \gamma \sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, \pi(s)\right)\left|V\left(s^{\prime}\right)-U\left(s^{\prime}\right)\right| \\ \leq \gamma\left(\sum_{s^{\prime}} \operatorname{Pr}\left(s^{\prime} \mid s, \pi(s)\right)\right) \max _{s^{\prime}}\left|V\left(s^{\prime}\right)-U\left(s^{\prime}\right)\right| \leq \gamma\|U-V\|_{\infty} \end{array} ∥TπV−TπU∥∞=maxsγ∑s′Pr(s′∣s,π(s))∣V(s′)−U(s′)∣≤γ(∑s′Pr(s′∣s,π(s)))maxs′∣V(s′)−U(s′)∣≤γ∥U−V∥∞
∥ T V − T U ∥ ∞ ≤ γ ∥ V − U ∥ ∞ \|T V-T U\|_{\infty} \leq \gamma\|V-U\|_{\infty} ∥TV−TU∥∞≤γ∥V−U∥∞展开有:

对任意一个contraction operator,我们都有一个唯一的不动点 V ∗ = T V ∗ V^{*}=TV^{*} V∗=TV∗。有一个不动点,然后另外一个点不断地靠近它,然后就收敛到这个不动点。
∥ v k + 1 − v ⋆ ∥ ∞ = ∥ T V k − T V ⋆ ∥ ∞ ≤ γ ∥ V k − V ⋆ ∥ ∞ ≤ ⋯ ≤ γ k + 1 ∥ V 0 − V ⋆ ∥ ∞ → 0 \begin{array}{r} \left\|v_{k+1}-v^{\star}\right\|_{\infty}=\left\|T V_{k}-T V^{\star}\right\|_{\infty} \\ \leq \gamma\left\|V_{k}-V^{\star}\right\|_{\infty} \leq \cdots \leq \gamma^{k+1}\left\|V_{0}-V^{\star}\right\|_{\infty} \rightarrow 0 \end{array} ∥vk+1−v⋆∥∞=∥TVk−TV⋆∥∞≤γ∥Vk−V⋆∥∞≤⋯≤γk+1∥V0−V⋆∥∞→0
有了这两个性质之后就可以证明策略迭代的收敛性:
假设我们有了新的策略 π k + 1 \pi_{k+1} πk+1(下标表示在k+1的策略下迭代),用这个新的策略来更新值函数,依据贝尔曼方程有:
V π k + 1 = ( I − γ P π k + 1 ) − 1 R π k + 1 ≥ ( I − γ P π k + 1 ) − 1 ( V π k − γ P π k + 1 V π k ) = V π ∘ 1 d \begin{aligned} V^{\pi_{k+1}} &=\left(I-\gamma P^{\pi k+1}\right)^{-1} R^{\pi_{k+1}} \\ & \geq\left(I-\gamma P^{\pi_{k+1}}\right)^{-1}\left(V^{\pi_{k}}-\gamma P^{\pi_{k+1}} V^{\pi_{k}}\right) \\ &=V^{\pi_{\circ} 1 d} \end{aligned} Vπk+1=(I−γPπk+1)−1Rπk+1≥(I−γPπk+1)−1(Vπk−γPπk+1Vπk)=Vπ∘1d
上述的不等号由以下公式推导得到( T V π k T V^{\pi_{k}} TVπk为最优贝尔曼方程):
R π k + 1 + γ P π k + 1 V π k = T π k + 1 V π k = T V π k ≥ V π k ⟺ R π k + 1 ≥ ( I − γ P π k + 1 ) V π k \begin{aligned} R^{\pi_{k+1}}+\gamma P^{\pi_{k+1}} V^{\pi_{k}} &=T^{\pi_{k+1}} V^{\pi_{k}}=T V^{\pi_{k}} \geq V^{\pi_{k}} \\ & \Longleftrightarrow R^{\pi_{k+1}} \geq\left(I-\gamma P^{\pi_{k+1}}\right) V^{\pi_{k}} \end{aligned} Rπk+1+γPπk+1Vπk=Tπk+1Vπk=TVπk≥Vπk⟺Rπk+1≥(I−γPπk+1)Vπk
因为值函数是单调的,所以有 V π ⋆ = lim k → ∞ V π k V^{\pi^{\star}}=\lim _{k \rightarrow \infty} V^{\pi_{k}} Vπ⋆=limk→∞Vπk,存在 V π ⋆ = T V π ⋆ V^{\pi^{\star}}=T V^{\pi^{\star}} Vπ⋆=TVπ⋆满足贝尔曼最优方程。
VI and PI的问题:1. 没法解决连续状态-动作空间的问题。也存在维度灾难问题。2. POMDP问题不可解。3. Unknown model的问题不可解。
Q learning
对于不知道reward,也不知道转移概率的情况,Q-Learning采用sample数据的方式来做值函数的更新:
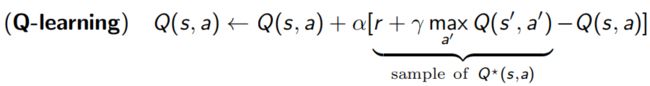
小结:
RL就是在MDP的约束下求解策略 π \pi π,VI/PI的方法会遇到维度灾难的问题。然后通过值函数近似(function approximate),或者sample的方法,像TD/MC的方法。function的估计可以泛化到未知的state,也正是由这些问题导致converge的算法变得不converge。对于PI的方法,就是对策略 π \pi π用function来近似。
n-step transition probability: an example
当马尔可夫链的状态转移概率在long-term下固定了,称其具有stationary distribution:

在满足两个条件的情况下,马尔科夫链会具有stationary distribution的性质:
- 任意一个state都具有一个path到另外一个state。
- 不允许有loop的情况,就是不能在一个state圈里面转。
回到PI的目标函数上来,假定策略 π θ \pi_{\theta} πθ,这个策略的期望回报可表示为:
J ( θ ) = ∑ s ∈ S d π ( s ) V π ( s ) = ∑ s ∈ S d π ( s ) ( ∑ a ∈ A π θ ( a ∣ s ) Q π ( s , a ) ) J(\theta)=\sum_{s \in S} d^{\pi}(s) V^{\pi}(s)=\sum_{s \in S} d^{\pi}(s)\left(\sum_{a \in A} \pi_{\theta}(a \mid s) Q^{\pi}(s, a)\right) J(θ)=s∈S∑dπ(s)Vπ(s)=s∈S∑dπ(s)(a∈A∑πθ(a∣s)Qπ(s,a))
其中 d π ( s ) : = lim t → ∞ p ( S t = s ∣ s 0 , π θ ) d^{\pi}(s):=\lim _{t \rightarrow \infty} p\left(S_{t}=s \mid s_{0}, \pi_{\theta}\right) dπ(s):=limt→∞p(St=s∣s0,πθ),是stationary distribution的话,那这个策略的评估是与初始状态无关的,因此在 J ( θ ) J(\theta) J(θ)中就不需要 s 0 s_{0} s0。
对于 J ( θ ) J(\theta) J(θ)的目标函数,我们就可以用gradient的方法来做,但是这个参数 θ \theta θ的求解比较trick,因为它影响两个东西:
- 动作的选择 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)。
- stationary distribution d π d^{\pi} dπ,因为 p ( s ′ ∣ s ) = p ( s ′ ∣ s , a ) p(s^{\prime}|s)=p(s^{\prime}|s,a) p(s′∣s)=p(s′∣s,a)。
这样的话求解就比较麻烦了,99年Sutton提出了下面这篇论文:
- Richard S Sutton et al. “Policy gradient methods for reinforcement learning with function approximation”. In: Advances in Neural Information Processing Systems (NeurIPS). 1999, pp. 1057–1063.
去消去state distribution的求导问题:
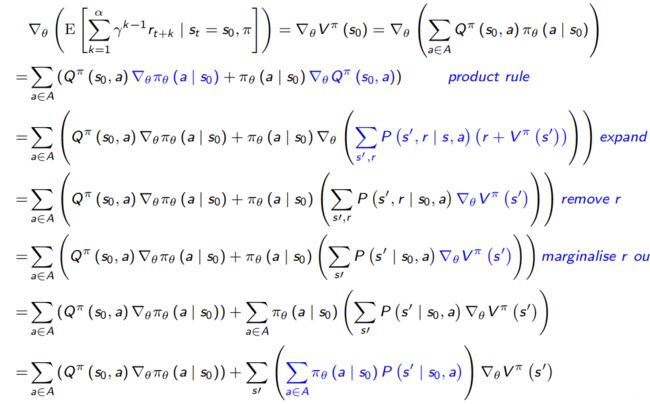
因此得到了对 ∇ θ V π ( s 0 ) \nabla_{\theta} V^{\pi}\left(s_{0}\right) ∇θVπ(s0)的求导也变成了循环(recursive)的形式:
∇ θ V π ( s 0 ) = ∑ a ∈ A ( Q π ( s 0 , a ) ∇ θ π θ ( a ∣ s 0 ) ) + ∑ s ′ ( ∑ a ∈ A π θ ( a ∣ s 0 ) P ( s ′ ∣ s 0 , a ) ) ∇ θ V π ( s ′ ) \begin{aligned} \nabla_{\theta} V^{\pi}\left(s_{0}\right)=& \sum_{a \in A}\left(Q^{\pi}\left(s_{0}, a\right) \nabla_{\theta} \pi_{\theta}\left(a \mid s_{0}\right)\right) \\ &+\sum_{s \prime}\left(\sum_{a \in A} \pi_{\theta}\left(a \mid s_{0}\right) P\left(s^{\prime} \mid s_{0}, a\right)\right) \nabla_{\theta} V^{\pi}\left(s^{\prime}\right) \end{aligned} ∇θVπ(s0)=a∈A∑(Qπ(s0,a)∇θπθ(a∣s0))+s′∑(a∈A∑πθ(a∣s0)P(s′∣s0,a))∇θVπ(s′)
简单化之后得到:
∇ θ V π ( s 0 ) = φ ( s 0 ) + ∑ s ′ P π ( s ′ ∣ s 0 ) ∇ θ V π ( s ′ ) \nabla_{\theta} V^{\pi}\left(s_{0}\right)=\varphi\left(s_{0}\right)+\sum_{s^{\prime}} P^{\pi}\left(s^{\prime} \mid s_{0}\right) \nabla_{\theta} V^{\pi}\left(s^{\prime}\right) ∇θVπ(s0)=φ(s0)+s′∑Pπ(s′∣s0)∇θVπ(s′)
其中 φ ( s 0 ) : = ∑ a ∈ A ( Q π ( s 0 , a ) ∇ θ π θ ( a ∣ s 0 ) ) \varphi\left(s_{0}\right):=\sum_{a \in A}\left(Q^{\pi}\left(s_{0}, a\right) \nabla_{\theta} \pi_{\theta}\left(a \mid s_{0}\right)\right) φ(s0):=∑a∈A(Qπ(s0,a)∇θπθ(a∣s0)), Markov transition表示成 P π ( s ′ ∣ s 0 ) : = ∑ a ∈ A π θ ( a ∣ s 0 ) P ( s ′ ∣ s 0 , a ) P^{\pi}\left(s^{\prime} \mid s_{0}\right):=\sum_{a \in A} \pi_{\theta}\left(a \mid s_{0}\right) P\left(s^{\prime} \mid s_{0}, a\right) Pπ(s′∣s0):=∑a∈Aπθ(a∣s0)P(s′∣s0,a)形式。
定义从 s 0 s_{0} s0状态转移k步,关系如下:
P π ( s ′ ′ ∣ s 0 , k ) ≡ ∑ s ′ P π ( s ′ ′ ∣ s ′ , k − 1 ) P π ( s ′ ∣ s 0 ) P^{\pi}\left(s^{\prime \prime} \mid s_{0}, k\right) \equiv \sum_{s^{\prime}} P^{\pi}\left(s^{\prime \prime} \mid s^{\prime}, k-1\right) P^{\pi}\left(s^{\prime} \mid s_{0}\right) Pπ(s′′∣s0,k)≡s′∑Pπ(s′′∣s′,k−1)Pπ(s′∣s0)
回到之前的循环形式:

再定义 d π ( s ) : = ∑ k = 0 α P π ( s ∣ s 0 , k ) d^{\pi}(s):=\sum_{k=0}^{\alpha} P^{\pi}\left(s \mid s_{0}, k\right) dπ(s):=∑k=0αPπ(s∣s0,k),那此时就与之前stationary distribution一样了,可以写成:
∇ θ V π ( s 0 ) = ∑ s ∈ S d π ( s ) ∑ a ∈ A ( Q π ( s , a ) ∇ θ π θ ( a ∣ s ) ) \nabla_{\theta} V^{\pi}\left(s_{0}\right)=\sum_{s \in S} d^{\pi}(s) \sum_{a \in A}\left(Q^{\pi}(s, a) \nabla_{\theta} \pi_{\theta}(a \mid s)\right) ∇θVπ(s0)=s∈S∑dπ(s)a∈A∑(Qπ(s,a)∇θπθ(a∣s))
也就是梯度也是recursive的形式。这样使得求梯度的时候不用考虑状态转移。另外一点是上式中 ∑ a ∈ A \sum_{a \in A} ∑a∈A是对所有的动作求和,但是我们是sample样本,那怎么使得我们的estimation是unbiased的呢?
∇ θ V π ( s 0 ) = ∑ s ∈ S d π ( s ) ∑ a ∈ A ( Q π ( s , a ) ∇ θ π θ ( a ∣ s ) ) ∝ ∑ s ∈ S μ ( s ) ∑ a ∈ A ( π θ ( a ∣ s ) Q π ( s , a ) ∇ θ π θ ( a ∣ s ) π θ ( a ∣ s ) ) = E s ∼ μ , a ∼ π [ Q π ( s , a ) ∇ θ ln π θ ( a ∣ s ) ] = E s ∼ μ , a ∼ π [ G t ∇ θ ln π θ ( a ∣ s ) ] where E s ∼ d π , a ∼ π [ G t ∣ s , a ] = Q π ( s , a ) \begin{array}{c} \nabla_{\theta} V^{\pi}\left(s_{0}\right)=\sum_{s \in S} d^{\pi}(s) \sum_{a \in A}\left(Q^{\pi}(s, a) \nabla_{\theta} \pi_{\theta}(a \mid s)\right) \\ \propto \sum_{s \in S} \mu(s) \sum_{a \in A}\left(\pi_{\theta}(a \mid s) Q^{\pi}(s, a) \frac{\nabla_{\theta} \pi_{\theta}(a \mid s)}{\pi_{\theta}(a \mid s)}\right) \\ =E_{s \sim \mu, a \sim \pi}\left[Q^{\pi}(s, a) \nabla_{\theta} \ln \pi_{\theta}(a \mid s)\right] \\ =E_{s \sim \mu, a \sim \pi}\left[G_{t} \nabla_{\theta} \ln \pi_{\theta}(a \mid s)\right] \\ \text { where } E_{s \sim d \pi, a \sim \pi}\left[G_{t} \mid s, a\right]=Q^{\pi}(s, a) \end{array} ∇θVπ(s0)=∑s∈Sdπ(s)∑a∈A(Qπ(s,a)∇θπθ(a∣s))∝∑s∈Sμ(s)∑a∈A(πθ(a∣s)Qπ(s,a)πθ(a∣s)∇θπθ(a∣s))=Es∼μ,a∼π[Qπ(s,a)∇θlnπθ(a∣s)]=Es∼μ,a∼π[Gt∇θlnπθ(a∣s)] where Es∼dπ,a∼π[Gt∣s,a]=Qπ(s,a)
乘一个 π θ ( a ∣ s ) \pi_{\theta}(a \mid s) πθ(a∣s),使其概率化,来解决这一点。此时梯度更新变为:
θ t + 1 = θ t + α G t ∇ θ ln π θ ( a ∣ s ) \theta_{t+1}=\theta_{t}+\alpha G_{t} \nabla_{\theta} \ln \pi_{\theta}(a \mid s) θt+1=θt+αGt∇θlnπθ(a∣s)
- Ronald J Williams. “Simple statistical gradient-following algorithms for connectionist reinforcement learning”. In: Machine learning 8.3-4 (1992).

但是如果sample到episode结束的话,这个variance就会比较大,一般我们加个baseline V π θ ( s ) V^{\pi_{\theta}}(s) Vπθ(s)来减少方差:
A π θ ( s , a ) : = Q π θ ( s , a ) − V π θ ( s ) A^{\pi_{\theta}}(s, a):=Q^{\pi_{\theta}}(s, a)-V^{\pi_{\theta}}(s) Aπθ(s,a):=Qπθ(s,a)−Vπθ(s)
Computational learning theory
在q-learning和pg的方法中都是通过sample来做的,那learnability怎么衡量呢,也就是sample的数量对收敛性的影响。
Probably Approximately Correct (PAC) learning
PAC主要关注两点,sample complexity和computational complexity。这里我们主要关注sample complexity。
- PAC定义:

因为 S S S是sample自distribution D D D,所以定义一下误差:

理论分析
- PAC Learning定义:
PAC Learning大概的意思就是找一个算法,使得其在样本上的误差(与generalisation error之间的误差),以一个很高的概率去小于一个值:

Learning bound for finite H - consistent case:
那 ε \varepsilon ε和 m m m、 δ \delta δ的关系是什么呢?

证明:

上述是consistent case的情况,也就是我们能够找到训练误差为0的假设,但很多时候做不到这一点,这个时候我们就需要其它的一些方法。
Learning bound for finite H: inconsistent Case
inconsistent hypotheses就是会在training set上存在些许误差,这个时候我们利用Hoeffding’s inequality来解决这个问题:
- Hoeffding’s inequality

与之前类似,其定理和证明可表示为:

这里有一个概念,估计误差和近似误差。在训练集 s s s上的学到的假设为 h s h_{s} hs,那与真实的误差 R ∗ R^{*} R∗之间的差距可以表示为两部分:
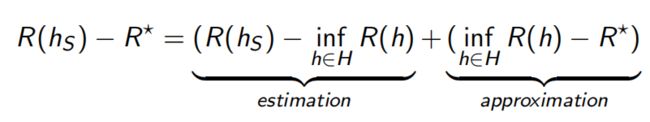
一个是sample数量有限导致的error(estimation error),另外一个是假设空间 H H H本身导致的误差(approximation error)。这两个误差一个是sample导致的,另外一个是做approximate所导致的,由此有了上述的这些bound,有了这个bound之后我们就可以去分析各种各样的算法。
Theoretical analysis
先来分析approximation error,当状态空间很大时,我们可以用线性模型或者神经网络来逼近这个值函数,这种方法也被称作(Approximate DP),我们希望在整个函数空间 V \mathcal{V} V中找到一个 V V V不断逼近最优值函数 V ∗ V^{*} V∗:
V = arg min U ∈ V distance ( V ⋆ , U ) V=\underset{U \in \mathcal{V}}{\arg \min } \operatorname{distance}\left(V^{\star}, U\right) V=U∈Vargmindistance(V⋆,U)
若得到 V V V就可以利用贪婪策略得到强化的策略。现如今的大部分RL算法都是在ADP的基础上做状态转移和奖励未知的情况,一般也都是用sample来做。此时性能上面的gap与近似误差的关系可表示为:
- ADP performance bounds

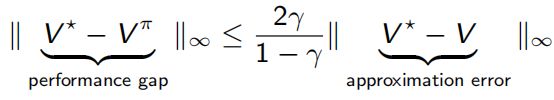
因为用的贪婪策略 T π = T T^{\pi}=T Tπ=T。
- Bounds by Bellman residual

上述也是用的贪婪策略。这样就把寻找与最优值函数 V ∗ V^{*} V∗(这个值未知)的差距转化为寻找Bellman residua的差距,像TD就是这么做的。接下来就是对 Bellman residual minimisation:
- Bellman residual minimisation:
( BRM ) min V ∈ V ∥ T V − V ∥ (\text { BRM }) \quad \min _{V \in \mathcal{V}}\|T V-V\| ( BRM )V∈Vmin∥TV−V∥
Performance bounds of AVI(值迭代的bound)
AVI bound [BT96]: K次迭代的bound结果:
∥ V ⋆ − V π K ∥ ∞ ≤ 2 γ ( 1 − γ ) 2 max 0 ≤ k ≤ K ∥ T V k − V k + 1 ∥ ∞ + 2 γ K + 1 1 − γ ∥ V ⋆ − V 0 ∥ ∞ \begin{aligned} \left\|V^{\star}-V^{\pi_{K}}\right\|_{\infty} \leq \frac{2 \gamma}{(1-\gamma)^{2}} & \max _{0 \leq k \leq K}\left\|T V_{k}-V_{k+1}\right\|_{\infty} \\ &+\frac{2 \gamma^{K+1}}{1-\gamma}\left\|V^{\star}-V_{0}\right\|_{\infty} \end{aligned} ∥V⋆−VπK∥∞≤(1−γ)22γ0≤k≤Kmax∥TVk−Vk+1∥∞+1−γ2γK+1∥V⋆−V0∥∞
证明:
令 ε = max 0 ≤ k ≤ K ∥ T V k − V k + 1 ∥ ∞ \varepsilon=\max _{0 \leq k \leq K}\left\|T V_{k}-V_{k+1}\right\|_{\infty} ε=max0≤k≤K∥TVk−Vk+1∥∞,有:
∥ V ⋆ − V k + 1 ∥ ∞ ≤ ∥ T V ⋆ − T V k ∥ + ∥ T V k − V k + 1 ∥ ∞ ≤ γ ∥ V ⋆ − V k ∥ ∞ + ε \begin{aligned}\left\|V^{\star}-V_{k+1}\right\|_{\infty} & \leq\left\|T V^{\star}-T V_{k}\right\|+\left\|T V_{k}-V_{k+1}\right\|_{\infty} \\ & \leq \gamma\left\|V^{\star}-V_{k}\right\|_{\infty}+\varepsilon \end{aligned} ∥V⋆−Vk+1∥∞≤∥TV⋆−TVk∥+∥TVk−Vk+1∥∞≤γ∥V⋆−Vk∥∞+ε
将上述结果迭代下去有:
∥ V ⋆ − V k ∥ ∞ ≤ ( 1 + γ + ⋯ + γ K − 1 ) ε + γ K ∥ V ⋆ − V 0 ∥ ∞ ≤ 1 1 − γ ε + γ K ∥ V ⋆ − V 0 ∥ ∞ \begin{aligned} \left\|V^{\star}-V_{k}\right\|_{\infty} & \leq\left(1+\gamma+\cdots+\gamma^{K-1}\right) \varepsilon+\gamma^{K}\left\|V^{\star}-V_{0}\right\|_{\infty} \\ & \leq \frac{1}{1-\gamma} \varepsilon+\gamma^{K}\left\|V^{\star}-V_{0}\right\|_{\infty} \end{aligned} ∥V⋆−Vk∥∞≤(1+γ+⋯+γK−1)ε+γK∥V⋆−V0∥∞≤1−γ1ε+γK∥V⋆−V0∥∞
把这个结果带入到公式13即可得证。
下文并未看懂,以后再补:
Performance bounds of API(策略迭代的bound)
- API bound [BT96]: the asymptotic performance bound is
lim sup k → ∞ ∥ V ⋆ − V π k ∥ ∞ ≤ 2 γ ( 1 − γ ) 2 lim sup k → ∞ ∥ V k − V π k ∥ ∞ \limsup _{k \rightarrow \infty}\left\|V^{\star}-V^{\pi_{k}}\right\|_{\infty} \leq \frac{2 \gamma}{(1-\gamma)^{2}} \limsup _{k \rightarrow \infty}\left\|V_{k}-V^{\pi_{k}}\right\|_{\infty} k→∞limsup∥V⋆−Vπk∥∞≤(1−γ)22γk→∞limsup∥Vk−Vπk∥∞
证明:

Performance bounds of BRM

Sample-based ADP: sample complexity

- Sample complexity: sampling-based AVI


- Deep Q learning and its sample complexity
