Redis-HyperLogLog内部实现原理源码解析
1、HyperLogLog算法时一种非常巧妙的近似统计大量去重元素数量的算法,它内部维护了16384个桶来记录各自桶的元素数量,当一个元素过来,它会散列到其中一个桶。当元素到来时,通过 hash 算法将这个元素分派到其中的一个小集合存储,同样的元素总是会散列到同样的小集合。这样总的计数就是所有小集合大小的总和。使用这种方式精确计数除了可以增加元素外,还可以减少元素。

一个HyperLogLog实际占用的空间大约是 13684 * 6bit / 8 = 12k 字节。但是在计数比较小的时候,大多数桶的计数值都是零。如果 12k 字节里面太多的字节都是零,那么这个空间是可以适当节约一下的。Redis 在计数值比较小的情况下采用了稀疏存储,稀疏存储的空间占用远远小于 12k 字节。相对于稀疏存储的就是密集存储,密集存储会恒定占用 12k 字节。
2、密集存储结构
1)Redis内部使用字符串位图来存储HyperLogLog所有桶的计数值,密集存储的结构非常简单,就是连续 16384 个 6bit 串成的字符串位图。
2)通过桶的编号,计算他的6bit计算值:offset_bytes代表6bit计数值的起始字节位置偏移,而offset_bits表示起始比特位置偏移,例如idx代表桶的编号且位2,则offset_bytes = (idx*6)/8 = 1 ,offset_bits = (idx * 6)%8 = 4,所有第2个字节的第5位是bucket 2的计数值。需要注意的是字节位序是左边是低位,右边是高位,正好与平时我们接触到的相反。
3)如offset_bits小于2,那么6bit在一个字节内部,如下图

对应代码如下
| val = buffer[offset_bytes] >> offset_bits # 向右移位 |
4)如果offset_bits大于2,那么就会跨越字节边界,需要俩个字节拼接起来
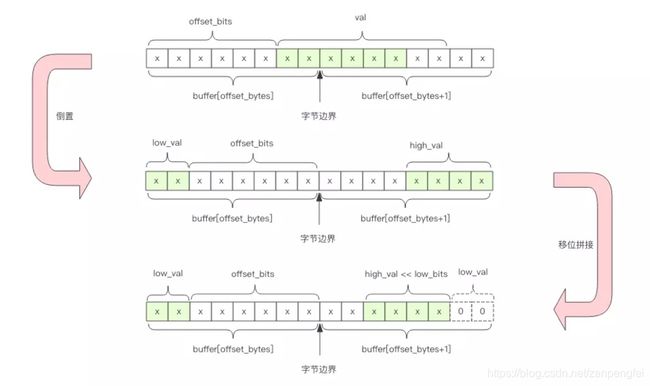
代码如下:
| # 低位值 low_val = buffer[offset_bytes] >> offset_bits # 低位个数 low_bits = 8 - offset_bits # 拼接,保留低6位 val = (high_val << low_bits | low_val) & 0b111111 |
3、稀疏存储结构
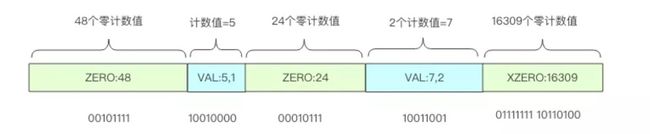
1)稀疏存储适用于很多计数值都是零的情况,如下图

2)当多个连续桶的计数值都是零时,Redis使用一个字节来表示多少个桶的计数值都是零即00xxxxxx,前缀俩个零表示接下来的6bit整数值加1就是零值计数器的数量,比如 00010101表示连续 22 个零值计数器;6bit最多能表示连续64个零值计数器,如果大于64个,采用来个字节表示即01xxxxxx yyyyyyyy,后面的 14bit 可以表示最多连续 16384 个零值计数器。
3)如果连续几个桶的计数值非零,那就使用形如 1vvvvvxx 这样的一个字节来表示。中间 5bit 表示计数值,尾部 2bit 表示连续几个桶。它的意思是连续 (xx +1) 个计数值都是 (vvvvv + 1)。比如 10101011 表示连续 4 个计数值都是 11。注意这两个值都需要加 1,因为任意一个是零都意味着这个计数值为零,那就应该使用零计数值的形式来表示。注意计数值最大只能表示到32,而 HyperLogLog 的密集存储单个计数值用 6bit 表示,最大可以表示到 63。当稀疏存储的某个计数值需要调整到大于 32 时,Redis 就会立即转换 HyperLogLog 的存储结构,将稀疏存储转换成密集存储。

Redis 为了方便表达稀疏存储,它将上面三种字节表示形式分别赋予了一条指令。
ZERO:len 单个字节表示 00[len-1],连续最多64个零计数值
VAL:value,len 单个字节表示 1[value-1][len-1],连续 len 个值为 value 的计数值
XZERO:len 双字节表示 01[len-1],连续最多16384个零计数值
上图可以使用指令形式表示如下:
4、存储转换
1)当计数值达到一定程度后,稀疏存储将不可逆一次性转换成密集型存储,但要满足俩个条件
a、任意一个计数值从 32 变成 33,因为VAL指令已经无法容纳,它能表示的计数值最大为 32
b、稀疏存储占用的总字节数超过 3000 字节,这个阈值可以通过 hll_sparse_max_bytes 参数进行调整。
5、计数缓冲
1)原因:计数为啥要增加缓冲
HyperLogLog的总计数值时根据16384个桶计数值进行调和平均后再基于修正因子公示计算出来的,它要遍历所有桶以及还要处理浮点数,这计算相对来说比较大,所以Redis使用一个64bit的字段缓冲这个总计数值,该字段最高如果是1,表示该缓冲已过期,如果是0,那么剩下的63bit就是该缓冲值。
2)HyperLogLog中任意一个桶的计数值发生变化,都会将计数缓冲设为过期
6、对象头
1)对象头要存一些附加的字段,例如总计数缓冲、存储类型等
| struct hllhdr { char magic[4]; /* 魔术字符串"HYLL" */ uint8_t encoding; /* 存储类型 HLL_DENSE or HLL_SPARSE. */ uint8_t notused[3]; /* 保留三个字节未来可能会使用 */ uint8_t card[8]; /* 总计数缓存 */ uint8_t registers[]; /* 所有桶的计数器 */ }; |
2)HyperLogLog整体的内部结构就是对象头加上16384个桶的计数值位图
3)不能使用HyperLogLog指令来操作普通字符串,因为内部要检查对象头魔术字符串是否位HYLL
4)如果字符串以 "HYLL\x00" 或者 "HYLL\x01" 开头,那么就可以使用 HyperLogLog 的指令
| 127.0.0.1:6379> set codehole "HYLL\x01whatmagicthing" OK 127.0.0.1:6379> get codehole "HYLL\x01whatmagicthing" 127.0.0.1:6379> pfadd codehole python java golang (integer) 1 |
这是因为 HyperLogLog 在执行指令前需要对内容进行格式检查,这个检查就是查看对象头的 magic 魔术字符串是否是 "HYLL" 以及 encoding 字段是否是 HLL_SPARSE=0 或者 HLL_DENSE=1 来判断当前的字符串是否是 HyperLogLog 计数器。如果是密集存储,还需要判断字符串的长度是否恰好等于密集计数器存储的长度。
| int isHLLObjectOrReply(client *c, robj *o) { ... /* Magic should be "HYLL". */ if (hdr->magic[0] != 'H' || hdr->magic[1] != 'Y' || hdr->magic[2] != 'L' || hdr->magic[3] != 'L') goto invalid; if (hdr->encoding > HLL_MAX_ENCODING) goto invalid; if (hdr->encoding == HLL_DENSE && stringObjectLen(o) != HLL_DENSE_SIZE) goto invalid; return C_OK; invalid: addReplySds(c, sdsnew("-WRONGTYPE Key is not a valid " "HyperLogLog string value.\r\n")); return C_ERR; } |
5)HyperLogLog 和 字符串的关系就好比 Geo 和 zset 的关系。你也可以使用任意 zset 的指令来访问 Geo 数据结构,因为 Geo 内部存储就是使用了一个纯粹的 zset来记录元素的地理位置。
7、Redis作者博客:http://antirez.com/latest/0