MySQL+ Sqoop + Hive + HBase
一、安装
1、MySQL
1)首先在自己电脑上,打开链接:https://dev.mysql.com/downloads/repo/yum/,选择

下载并上传到hadoop的master服务器/opt/bigdata/hadoop/。
2)登录master,进行如下操作
[hadoop@zhoumaster ~]$ cd /opt/bigdata/hadoop/
[hadoop@zhoumaster hadoop]$ ll
总用量 386528
drwxr-xr-x 12 hadoop hadoop 4096 12月 27 02:18 hadoop-2.7.3
-rwxrwxrwx 1 hadoop hadoop 214092195 3月 13 2017 hadoop-2.7.3.tar.gz
drwxrwxr-x 8 hadoop hadoop 4096 3月 13 2017 jdk1.8
-rwxrwxrwx 1 hadoop hadoop 181668321 3月 22 2017 jdk1.8.tar.gz
-rw-rw-r-- 1 hadoop hadoop 25820 12月 27 17:49 mysql80-community-release-el7-1.noarch.rpm
drwxrwxr-x 3 hadoop hadoop 4096 12月 26 21:29 opt
[hadoop@zhoumaster hadoop]$ sudo rpm -Uvh mysql80-community-release-el7-1.noarch.rpm
We trust you have received the usual lecture from the local System
Administrator. It usually boils down to these three things:
#1) Respect the privacy of others.
#2) Think before you type.
#3) With great power comes great responsibility.
[sudo] password for hadoop:
警告:mysql80-community-release-el7-1.noarch.rpm: 头V3 DSA/SHA1 Signature, 密钥 ID 5072e1f5: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:mysql80-community-release-el7-1 ################################# [100%]
3)修改文件,把里面的5.6的enabled值改成1,其他的enabled值都改成0,这样即安装mysql5.6版。
[hadoop@zhoumaster hadoop]$ sudo vim /etc/yum.repos.d/mysql-community.repo
# Enable to use MySQL 5.5
[mysql55-community]
name=MySQL 5.5 Community Server
baseurl=http://repo.mysql.com/yum/mysql-5.5-community/el/7/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
# Enable to use MySQL 5.6
[mysql56-community]
name=MySQL 5.6 Community Server
baseurl=http://repo.mysql.com/yum/mysql-5.6-community/el/7/$basearch/
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
# Enable to use MySQL 5.7
[mysql57-community]
name=MySQL 5.7 Community Server
baseurl=http://repo.mysql.com/yum/mysql-5.7-community/el/7/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
[mysql80-community]
name=MySQL 8.0 Community Server
baseurl=http://repo.mysql.com/yum/mysql-8.0-community/el/7/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
[mysql-connectors-community]
name=MySQL Connectors Community
baseurl=http://repo.mysql.com/yum/mysql-connectors-community/el/7/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
[mysql-tools-community]
name=MySQL Tools Community
baseurl=http://repo.mysql.com/yum/mysql-tools-community/el/7/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
[mysql-tools-preview]
name=MySQL Tools Preview
baseurl=http://repo.mysql.com/yum/mysql-tools-preview/el/7/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
[mysql-cluster-7.5-community]
name=MySQL Cluster 7.5 Community
baseurl=http://repo.mysql.com/yum/mysql-cluster-7.5-community/el/7/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
[mysql-cluster-7.6-community]
name=MySQL Cluster 7.6 Community
baseurl=http://repo.mysql.com/yum/mysql-cluster-7.6-community/el/7/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
4)安装依赖
[hadoop@zhoumaster hadoop]$ sudo yum install mysql-community-server
5)输入以下命令,启动MySQL服务,以root账户登录MySQL,刚进入时没有密码,需要输入系统密码
[hadoop@zhoumaster ~]$ service mysqld start
Redirecting to /bin/systemctl start mysqld.service
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
[hadoop@zhoumaster ~]$ mysql -uroot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.6.42 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
6)执行命令
mysql> CREATE USER 'xxx'@'%' IDENTIFIED BY 'yyy';
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE USER 'xxx'@'127.0.0.1' IDENTIFIED BY 'yyy';
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE USER 'xxx'@'localhost' IDENTIFIED BY 'yyy';
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE USER 'xxx'@'192.168.225.100' IDENTIFIED BY 'yyy';
Query OK, 0 rows affected (0.00 sec)
mysql> Grant all on *.* to 'xxx'@'127.0.0.1' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> Grant all on *.* to 'xxx'@'%' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> Grant all on *.* to 'xxx'@'localhost' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> Grant all on *.* to 'xxx'@'192.168.225.100' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> Flush privileges;
Query OK, 0 rows affected (0.00 sec)
说明:完成上面的命令后,就创建了一个用户名为xxx、密码为yyy、ip为本机ip、端口为3306的mysql账户,且具备在任何机器上登陆mysql的权限。
2、hive
1)将老师给的安装包中的hive-0.11.0-bin.zip上传到hadoop的master机器
2)解压后即可使用。
[hadoop@zhoumaster hadoop]$ sudo yum -y install zip unzip
[hadoop@zhoumaster hadoop]$ unzip hive-0.11.0-bin.zip
3、hbase(先安装zookeeper,教程往下拉)
1)将老师给的安装包中的hbase-1.2.5-bin.tar.gz上传到hadoop的master机器,并解压。
[hadoop@zhoumaster hadoop]$ tar -zxvf hbase-1.2.5-bin.tar.gz
2)进到hbase解压路径的conf文件夹下,配置hbase-site.xml
1. hbase.rootdir的值设置成hdfs://zhoumaster:9000/hbase
2. hbase.zookeeper.quorum的值设置成master以及两个slave机器的名字。
hbase.rootdir
#设置hbase数据库存放数据的目录
hdfs://zhoumaster:9000/hbase
hbase.cluster.distributed
#打开hbase分布模式
true
hbase.master
#指定hbase集群主控节点
zhoumaster:60000
hbase.zookeeper.quorum
zhoumaster,zhouslave1,zhouslave2
#指定zookeeper集群节点名,因为是由zookeeper表决算法决定的
hbase.zookeeper.property.dataDir
#指zookeeper集群data目录
/opt/bigdata/hadoop/zookeeper-3.4.9/data
hbase.master.info.port
16010
3)进到hbase解压路径的conf文件夹下,编辑hbase-env.sh文件,底部加入:
export JAVA_HOME=/opt/bigdata/hadoop/jdk1.8
export HADOOP_HOME=/opt/bigdata/hadoop/hadoop-2.7.3
export HBASE_HOME=/opt/bigdata/hadoop/hbase-1.2.5
export HBASE_CLASSPATH=/opt/bigdata/hadoop/hadoop-2.7.3/etc/hadoop
PATH=$PATH:$HBASE_HOME/bin
4)进到hbase解压路径的conf文件夹下,新建文件regionservers,并输入如下内容:
[hadoop@zhoumaster conf]$ sudo vim regionservers
zhoumaster
zhouslave1
zhouslave2
5)修改环境变量
[hadoop@zhoumaster conf]$ sudo vi /etc/profile
export HBASE_HOME=/opt/bigdata/hadoop/hbase-1.2.5
export PATH=$PATH:/opt/bigdata/hadoop/hbase-1.2.5/bin
6)启动
将master的hbase文件夹重新打包,复制给slave1和slave2并解压在/opt/bigdata/hadoop目录下
进入到master的hbase的bin目录下,执行./start-hbase.sh即可。
说明:需要先启动hadoop、zookeeper。
[hadoop@zhoumaster sbin]$ cd /opt/bigdata/hadoop/hbase-1.2.5/bin/
[hadoop@zhoumaster bin]$ ./start-hbase.sh
这里给出zookeeper的安装方式
1)下载zk,https://archive.apache.org/dist/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz ,上传到master到hadoop目录,并且解压。
2)修改环境变量
sudo vim /etc/profile,最底下加入如下几行:
ZK_HOME=/opt/bigdata/hadoop/zookeeper-3.4.9
export ZK_HOME
PATH=$PATH: $ZK_HOME/bin
3)进入zk的conf文件夹,执行
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
底下加入下面几行,缺少的文件夹需要新建:
dataDir=/opt/bigdata/hadoop/zookeeper-3.4.9/data
dataLogDir=/opt/bigdata/hadoop/zookeeper-3.4.9/log
server.1=192.168.225.100:2888:3888
server.2=192.168.225.101:2888:3888
server.3=192.168.225.102:2888:3888
其中三个ip分别是hadoop的master、slave1、slave2的ip。
4)进入到上面设置的data的路径,执行命令:
echo 1 >> myid
5)对于slave1、slave2机器,需要上面同样步骤的操作(三台机器安装配置zk),只不过在生成myid的时候,slave1是执行: echo 2 >> myid,slave2是执行:echo 3 >> myid
在slave1,2上可能要改用户组,和权限
chown -R hadoop.hadoop /opt/bigdata/hadoop/zookeeper-3.4.9
chmod -R 777
6)在三台机器上分别启动zk:
在三台机器上,分别执行下面的操作:
进入到zk根目录的bin路径,执行: ./zkServer.sh start
4、安装sqoop
1)下载压缩包
浏览器进入http://mirror.bit.edu.cn/apache/sqoop/1.4.7/,下载
2)将压缩包上传到hadoop的master机器,并解压。
3)下载mysql依赖的包,路径:http://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.32.tar.gz ,上传到sqoop的lib文件夹下,并且解压。
4)修改环境变量
sudo vi /etc/profile
加入两行:
export SQOOP_HOME=/opt/bigdata/hadoop/sqoop
export PATH=$PATH:$SQOOP_HOME/bin保存退出后,执行source /etc/profile
5)修改启动的配置文件
cd /opt/bigdata/hadoop/sqoop/conf/
mv sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh修改下面四个配置文件的路径:
HADOOP_COMMON_HOME:hadoop的根路径
HADOOP_MAPRED_HOME:hadoop的*.core.jar的路径,通常在HADOOP_HOME的share下
HBASE_HOME:hbase的根路径
HIVE_HOME:hive的根路径
ZOOCFGDIR:zk的conf的路径
6)确保hdfs已经启动
即进入hadoop的sbin,输入 ./start-all.sh
7)在sqoop根目录创建两个文件夹:
mkdir accumulo hcatalog
8)再次修改配置文件,路径:cd /opt/bigdata/hadoop/sqoop/conf/,文件名:sqoop-env.sh
最底下加上:
export ZOOKEEPER_HOME=/opt/bigdata/hadoop/zookeeper
export HCAT_HOME=/opt/bigdata/hadoop/sqoop/hcatalog
export ACCUMULO_HOME=/opt/bigdata/hadoop/sqoop/accumulo9)确认安装完成
进到sqoop的bin路径,输入: ./sqoop help ,有结果即可
10)启动MapReduce JobHistory Server服务
cd $HADOOP_HOME/sbin/ && ./mr-jobhistory-daemon.sh start historyserver关闭用 mr-jobhistory-daemon.sh stop historyserver
二、素材预处理及上传到HDFS
1、将small_user.csv文件上传到/opt/bigdata/hadoop/hadoop-2.7.3文件夹
2、命令:sed -i 1d small_user.csv,用于删除small_user.csv文件的第一行数据;
命令:cat small_user.csv | head -n 10 ,用于检查是否删除成功;
3、命令:vim pre.py 新建python文件
4、pre.py:
# encoding: utf-8
import csv
#打开small_user.csv文件
with open('small_user.csv','r') as rf,open('small_user1.csv','w') as wf:
reader = csv.reader(rf)
writer = csv.writer(wf)
for row in reader:
#取第一位到第十位字符
col_time = row[5][0:10]
#写入small_user1.csv文件
writer.writerow([row[0],row[1],row[2],row[3],row[4],col_time])5、命令:python pre.py执行
6、命令:cat small_user1.csv | head -10 查看预处理后的文件(前十行)
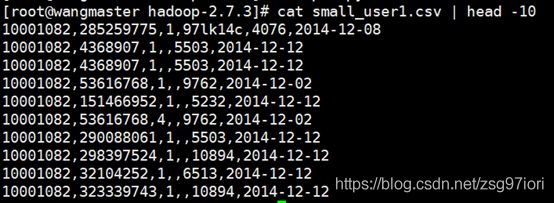
7、将数据上传到hdfs
hadoop fs -put small_user1.csv /small_user.csv三、HIVE创建库表
1、在hive建库表
进入到hive的bin路径,输入./hive,进入hive的命令行,执行下面命令:
create database dbuser;
CREATE EXTERNAL TABLE dbuser.small_user(user_id INT,item_id INT,behavior_type INT,user_geohash STRING,item_category INT,time STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY ',';2、载入数据
LOAD DATA INPATH '/small_user.csv' OVERWRITE INTO TABLE dbuser.small_user;
3、四道查询题
select behavior_type from dbuser.small_user limit 10;
select distinct(user_id) from dbuser.small_user;
select behavior_type from dbuser.small_user where time = '2014-12-12';
select user_id from dbuser.small_user where time = '2014-12-12' and behavior_type > 5;四、Sqoop导数据
1、使用 Sqoop 将 Hive 中的数据导入到 MySQL
1)连接mysql
进入mysql的文件夹,在进入bin目录,用mysql -uroot -p123456;
u后面为你的用户名,p后面为密码;
2)建库表
create database mytest;使用数据库时需要声明:
mysql>use mytest;
create table small_user (user_id bigint(20), item_id bigint(20), behavior_type int(8), user_geohash varchar(20), item_category int(10), time varchar(20));3)在linux系统的命令行,使用hadoop账户,进入sqoop的bin路径,执行下面的命令:
./sqoop export --connect jdbc:mysql://192.168.225.100:3306/mytest --username root --password 123456 --table small_user --fields-terminated-by ',' --export-dir /user/hive/warehouse/dbuser.db/small_user说明:
1. jdbc后面的参数为数据库ip:端口/数据库,192.168.225.100为master主机ip,数据库为提前建好的mytest库,username和password为mysql的用户名和密码,table为提前创建好的small_user表。注意数据库ip必须输入ip,而不能输入localhost,否则会报错。
2. export-dir为实际的hdfs所在的路径,可以在192.168.225.100:50070的ui界面看;点Utilities里的browse the file system看表small_user1.csv。
每次做实验都需要将数据上传到hdfs
hadoop fs -put small_user1.csv /small_user.csv
4)查看结果
在mysql命令行,输入select * from mytest.small_user; ,即可看到结果。
2、使用 Sqoop 将 MySQL 中的数据导入到 HBase
1)启动hbase
进入到hbase的bin路径,执行:
sh start-hbase.sh (首先确保zk已经启动)
2)打开hbase命令行
进入hbase的bin路径,执行 ./hbase shell,输入list,确认能返回数据,表示hbase已经启动成功。
3)退出hbase的命令后,在linux命令行输入:
./sqoop import --connect jdbc:mysql://192.168.225.100:3306/mytest --username root --password 123456 --table small_user --hbase-table zr --column-family info --hbase-row-key user_id --hbase-create-table -m 1说明:
1. jdbc后面的参数为数据库ip:端口/数据库,数据库为提前建好的mytest库,username和password为mysql的用户名和密码,table为提前创建好的small_user表,zr为hbase里的表名,user_id为主键,列内不能有空值,否则报错。注意数据库ip必须输入ip,而不能输入localhost,否则会报错。
2. hbase的表不用提前创建,上面的命令会自动创建。
4)查看结果
在hbase的家目录下的bin目录输入hbase shell进入hbase,
输入 scan “表名”,即可看到数据