爬虫教程( 4 ) --- 分布式爬虫 ( scrapy-redis )
分布式爬虫 scrapy - redis
scrapy 分布式爬虫
文档:http://doc.scrapy.org/en/master/topics/practices.html#distributed-crawls
Scrapy 并没有提供内置的机制支持分布式(多服务器)爬取。不过还是有办法进行分布式爬取, 取决于您要怎么分布了。
如果您有很多spider,那分布负载最简单的办法就是启动多个Scrapyd,并分配到不同机器上。
如果想要在多个机器上运行一个单独的spider,那您可以将要爬取的 url 进行分块,并发送给spider。 例如:
首先,准备要爬取的 url 列表,并分配到不同的文件 url 里:
http://somedomain.com/urls-to-crawl/spider1/part1.list
http://somedomain.com/urls-to-crawl/spider1/part2.list
http://somedomain.com/urls-to-crawl/spider1/part3.list接着在3个不同的 Scrapd 服务器中启动 spider。spider 会接收一个(spider)参数 part , 该参数表示要爬取的分块:
curl http://scrapy1.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=1
curl http://scrapy2.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=2
curl http://scrapy3.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=3
scrapy-redis 分布式爬虫
scrapy-redis 巧妙的利用 redis 队列实现 request queue 和 items queue,利用 redis 的 set 实现 request 的去重,将 scrapy 从单台机器扩展多台机器,实现较大规模的爬虫集群
Scrapy-Redis 架构分析
scrapy 任务调度是基于文件系统,这样只能在单机执行 crawl。
scrapy-redis 将待抓取 request 请求信息和数据 items 信息的存取放到 redis queue 里,使多台服务器可以同时执行 crawl 和 items process,大大提升了数据爬取和处理的效率。
scrapy-redis 是基于 redis 的 scrapy 组件,主要功能如下:
- 分布式爬虫。多个爬虫实例分享一个 redis request 队列,非常适合大范围多域名的爬虫集群
- 分布式后处理。爬虫抓取到的 items push 到一个 redis items 队列,这就意味着可以开启多个 items processes 来处理抓取到的数据,比如存储到 Mongodb、Mysql
- 基于 scrapy 即插即用组件。Scheduler + Duplication Filter、Item Pipeline、 Base Spiders
scrapy 原生架构
分析 scrapy-redis 的架构之前先回顾一下 scrapy 的架构


- 调度器(Scheduler):调度器维护 request 队列,每次执行取出一个 request。
- Spiders:Spider 是 Scrapy 用户编写用于分析 response,提取 item 以及跟进额外的 URL 的类。每个 spider 负责处理一个特定 (或一些) 网站。
- Item Pipeline:Item Pipeline 负责处理被 spider 提取出来的 item。典型的处理有清理、验证数据及持久化(例如存取到数据库中)。
如上图所示,scrapy-redis 在 scrapy 的架构上增加了 redis,基于 redis 的特性拓展了如下组件:
- 调度器(Scheduler)
scrapy-redis 调度器通过 redis 的 set 不重复的特性, 巧妙的实现了Duplication Filter去重(DupeFilter set存放爬取过的request)。 Spider 新生成的 request,将 request 的指纹到 redis 的 DupeFilter set 检查是否重复, 并将不重复的request push写入redis的request队列。 调度器每次从 redis 的 request 队列里根据优先级 pop 出一个 request, 将此 request 发给 spider 处理。 - Item Pipeline
将 Spider 爬取到的 Item 给 scrapy-redis 的 Item Pipeline, 将爬取到的 Item 存入 redis 的 items 队列。可以很方便的从 items 队列中提取 item, 从而实现 items processes 集群
总结
scrapy-redis 巧妙的利用 redis 实现 request queue和 items queue,利用 redis 的 set 实现 request 的去重,将 scrapy 从单台机器扩展多台机器,实现较大规模的爬虫集群
scrapy-redis 安装
文档: https://scrapy-redis.readthedocs.org.
- 安装 scrapy-redis:pip install scrapy-redis
scrapy-redis 源码截图:

可以看到 scrapy-redis 的 spiders.py 模块,导入了 scrapy.spiders 的 Spider、CrawlSpider,然后重新写了两个类 RedisSpiders、RedisCrawlSpider,分别继承 Spider、CrawlSpider,所以如果要想从 redis 读取任务,需要把自己写的 spider 继承 RedisSpiders、RedisCrawlSpider,而不是 scrapy 的 Spider、CrawlSpider。。。
scrapy-redis 使用 项目案例( 以 有缘网 北京 18-25岁 女朋友 )
以抓取 有缘网 北京 18-25岁 女朋友 为例
创建 scrapy-redis 的工程目录
- 方法 1:scrapy startproject MyScrapyRedis,然后自己写的 spider 继承 RedisSpider 或者 RedisCrawlSpider ,设置对应的 redis_key ,即队列的在 redis 中的 key。注意:这个需要手动 在 setting.py 里面配置设置。( 参考配置:https://github.com/rmax/scrapy-redis )
- 方法 2:使用 scrapy-redis 的 example 来修改。先从 github ( https://github.com/rmax/scrapy-redis ) 上拿到 scrapy-redis 的 example,然后将里面的 example-project 目录移到指定的地址。
或者将整个项目下载下来, 解压 scrapy-redis-master.zip 后,直接使用示例工程作为模板进行修改git clone https://github.com/rmax/scrapy-redis.git cp -r scrapy-redis/example-project ./scrapy-youyuancp -r scrapy-redis-master/example-project/ ./redis-youyuan cd redis-youyuan/
tree 查看项目目录

修改 settings.py ( 参考配置:https://github.com/rmax/scrapy-redis )
下面列举了修改后的配置文件中与 scrapy-redis 有关的部分,middleware、proxy 等内容在此就省略了。
# Scrapy settings for example project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/topics/settings.html
#
BOT_NAME = 'example'
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders'
# USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# The class used to detect and filter duplicate requests.
# The default (RFPDupeFilter) filters based on request fingerprint using
# the scrapy.utils.request.request_fingerprint function.
# In order to change the way duplicates are checked you could subclass RFPDupeFilter and
# override its request_fingerprint method. This method should accept scrapy Request object
# and return its fingerprint (a string).
# By default, RFPDupeFilter only logs the first duplicate request.
# Setting DUPEFILTER_DEBUG to True will make it log all duplicate requests.
DUPEFILTER_DEBUG = True
# 指定使用 scrapy-redis 的 Scheduler
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 在 redis 中保持 scrapy-redis 用到的各个队列,从而允许暂停和暂停后恢复
SCHEDULER_PERSIST = True
# 指定排序爬取地址时使用的队列,默认是按照优先级排序
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
# 只在使用 SpiderQueue 或者 SpiderStack 是有效的参数,,指定爬虫关闭的最大空闲时间
SCHEDULER_IDLE_BEFORE_CLOSE = 10
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'example.pipelines.MyRedisPipeline': 400,
# 'scrapy_redis.pipelines.RedisPipeline': 400,
}
LOG_LEVEL = 'DEBUG'
# Introduce an artifical delay to make use of parallelism. to speed up the
# crawl.
# DOWNLOAD_DELAY = 1
# 指定redis的连接参数
# REDIS_PASS是我自己加上的redis连接密码,需要简单修改scrapy-redis的源代码以支持使用密码连接redis
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
# Custom redis client parameters (i.e.: socket timeout, etc.)
REDIS_PARAMS = {}
# REDIS_URL = 'redis://user:pass@hostname:9001'
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Accept-Encoding': 'gzip, deflate, sdch',
}
查看 pipeline.py。注意:RedisPipeline 往 redis 写 item 数据时进行了序列化( 可以查看 RedisPipeline 的 _process_item 方法即刻看到进行了序列化),为了看到原始数据的item,这里自定义了一个 MyRedisPipeline,继承自 RedisPipeline,重写 _process_item 方法,不进行序列化,直接把数据写到 redis 里。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/topics/item-pipeline.html
import json
from datetime import datetime
from scrapy_redis.pipelines import RedisPipeline
class ExamplePipeline(object):
def process_item(self, item, spider):
item["crawled"] = str(datetime.now().replace(microsecond=0))
item["spider"] = spider.name
return item
class MyRedisPipeline(RedisPipeline):
def _process_item(self, item, spider):
key = self.item_key(item, spider)
# data = self.serialize(item)
self.server.rpush(key, json.dumps(item, ensure_ascii=False))
return item
也可以不用重写,通过在 setting.py 里面配置 REDIS_ITEMS_SERIALIZER = 'json.dumps' 即可使用 json 序列化( # scrapy-redis 默认使用 ScrapyJSONEncoder 进行项目序列化 #You can use any importable path to a callable object. #REDIS_ITEMS_SERIALIZER = 'json.dumps',通过查看 scrapy-redis 的 pipelines.py )
参考:https://www.cnblogs.com/Alexephor/p/11446167.html

修改 items.py,增加我们最后要保存的 Profile 项
class Profile(Item):
# 提取头像地址
header_url = Field()
# 提取相册图片地址
pic_urls = Field()
username = Field()
# 提取内心独白
monologue = Field()
age = Field()
# youyuan
source = Field()
source_url = Field()
crawled = Field()
spider = Field()
非分布式,即 scrapy 示例
修改爬虫文件。在 spiders 目录下添加 youyuan.py, 编写爬虫,之后就可以运行爬虫。 这里的提供一个简单的版本:
# -*- coding: utf-8 -*-
import re
from abc import ABC
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
# 这两个还是 scrapy.spiders 中的 Spider, CrawlSpider
from scrapy_redis.spiders import Spider, CrawlSpider
# scrapy_redis 自定义的 RedisSpider, RedisCrawlSpider
from scrapy_redis.spiders import RedisSpider, RedisCrawlSpider
class YouYuanSpider(CrawlSpider, ABC):
name = 'yy_spider'
allowed_domains = ['youyuan.com']
# 有缘网的列表页
start_urls = ['http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/']
pattern = re.compile(r'[0-9]')
# 提取列表页和 Profile 资料页的链接形成新的 request 保存到 redis 中等待调度
profile_page_lx = LinkExtractor(allow=(r'http://www.youyuan.com/\d+-profile/',))
page_lx = LinkExtractor(allow=(r'http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p\d+/',))
rules = (
Rule(page_lx, callback='parse_list_page', follow=True),
Rule(profile_page_lx, callback='parse_profile_page', follow=False),
)
def __init__(self):
super(YouYuanSpider, self).__init__()
self.temp = None
# 处理列表页,其实完全不用的,就是留个函数debug方便
def parse_list_page(self, response):
print(f"Processed list {response.url}")
# print response.body
self.profile_page_lx.extract_links(response)
pass
# 处理 Profile 资料页,得到我们要的 Profile
def parse_profile_page(self, response):
print(f"Processing profile {response.url}")
profile = dict()
profile['header_url'] = self.get_header_url(response)
profile['username'] = self.get_username(response)
profile['monologue'] = self.get_monologue(response)
profile['pic_urls'] = self.get_pic_urls(response)
profile['age'] = self.get_age(response)
profile['source'] = 'youyuan'
profile['source_url'] = response.url
# print "Processed profile %s" % response.url
yield profile
# 提取头像地址
def get_header_url(self, response):
self.temp = None
header = response.xpath('//dl[@class="personal_cen"]/dt/img/@src').extract()
if len(header) > 0:
header_url = header[0]
else:
header_url = ""
return header_url.strip()
# 提取用户名
def get_username(self, response):
self.temp = None
usernames = response.xpath('//dl[@class="personal_cen"]/dd/div/strong/text()').extract()
if len(usernames) > 0:
username = usernames[0]
else:
username = ""
return username.strip()
# 提取内心独白
def get_monologue(self, response):
self.temp = None
monologues = response.xpath('//ul[@class="requre"]/li/p/text()').extract()
if len(monologues) > 0:
monologue = monologues[0]
else:
monologue = ""
return monologue.strip()
# 提取相册图片地址
def get_pic_urls(self, response):
self.temp = None
pic_urls = []
data_url_full = response.xpath('//li[@class="smallPhoto"]/@data_url_full').extract()
if len(data_url_full) <= 1:
pic_urls.append("")
else:
for pic_url in data_url_full:
pic_urls.append(pic_url)
if len(pic_urls) <= 1:
return ""
return '|'.join(pic_urls)
# 提取年龄
def get_age(self, response):
age_urls = response.xpath('//dl[@class="personal_cen"]/dd/p[@class="local"]/text()').extract()
if len(age_urls) > 0:
age = age_urls[0]
else:
age = ""
age_words = re.split(' ', age)
if len(age_words) <= 2:
return "0"
# 20岁
age = age_words[2][:-1]
if self.pattern.match(age):
return age
return "0"
if __name__ == '__main__':
from scrapy import cmdline
cmdline.execute('scrapy crawl yy_spider'.split())
pass
运行项目:scrapy crawl yy_spider ,或者直接运行 youyuan.py 文件
redis 数据截图:

存储
假设我们要把 yy_spider:items 中保存的 Profile 读出来写进 Mongodb、mysql,那么我们可以修改模板 process_items.py 文件,然后保持后台运行就可以不停地入库爬回来的 Profile 了。
导出 MongoDB。数据库 youyuan、表名 Infos 。Python 操作 MongoDB 简单示例
import pymongo
conn = pymongo.Connection('192.168.17.129', 27017)
db = conn.youyuan
db["Infos"].save(item)导出 MYSQL。sql 语句:建立数据库 youyuan、表名 Infos
-- ----------------------------
-- Table structure for Infos
-- ----------------------------
DROP TABLE IF EXISTS `Infos`;
CREATE TABLE `Infos` (
`header_url` varchar(255) DEFAULT NULL,
`pic_urls` text,
`username` varchar(255) DEFAULT NULL,
`monologue` varchar(255) DEFAULT NULL,
`age` varchar(255) DEFAULT NULL,
`source` varchar(255) DEFAULT NULL,
`source_url` varchar(255) DEFAULT NULL,
`crawled` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`spider` varchar(255) DEFAULT NULL,
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=742 DEFAULT CHARSET=utf8;修改 process_items.py
import MySQLdb
conn = MySQLdb.connect(
host='192.168.17.129',
user='root', passwd='root',
db='youyuan', port=3306,
charset="utf8"
)
cur = conn.cursor()
sql_str = '''
insert into Infos(header_url,pic_urls,username,monologue,age,source,source_url,crawled,spider)
values('%s','%s','%s','%s','%s','%s','%s','%s','%s')''' % (
item['header_url'],
item['pic_urls'],
item['username'],
item['monologue'],
item['age'],
item['source'],
item['source_url'],
item['crawled'],
item['spider']) + ';'
print(sql_str)
cur.execute(sql_str)
conn.commit()
cur.close()
Ubuntu 安装 mysql 并设置远程访问
安装 mysql
安装需要使用 root 账号,安装 mysql 过程中,需要设置 mysql 的 root 账号的密码,不要忽略了。
sudo apt-get install mysql-server
apt install mysql-client
apt install libmysqlclient-dev以上3个软件包安装完成后,使用如下命令查询是否安装成功:
sudo netstat -tap | grep mysql查询结果如下图所示,表示安装成功。
root@xyz:~# netstat -tap | grep mysql
tcp6 0 0 [::]:mysql [::]:* LISTEN 7510/mysqld
root@xyz:~#
设置 mysql 远程访问
编辑 mysql 配置文件,把其中 bind-address = 127.0.0.1 注释了
vi /etc/mysql/mysql.conf.d/mysqld.cnf使用 root 进入 mysql 命令行,执行如下2个命令,示例中 mysql 的 root 账号密码:root
python@ubuntu:/etc/mysql/conf.d$ mysql -u root -p
Enter password:
grant all on *.* to root@'%' identified by 'root';
flush privileges;重启 mysql
service mysql restart重启成功后,在其他计算机上,便可以登录。
分布式,即 scrapy-redis 示例
上面 的非分布式爬虫 是从 start_urls 读取的 任务,现在改成从 redis 里面读取任务,从而实现分布式爬虫。即 从 redis 启动 Spider。( scrapy_redis.spiders 下有两个类 RedisSpider 和 RedisCrawlSpider,能够使 spider 从 Redis 读取 start_urls,然后执行爬取,若爬取过程中返回更多的 request url,那么它会继续进行直至所有的 request 完成之后,再从 redis start_urls 中读取下一个 url,循环这个过程 )
RedisSpider 示例
以 example 下 mycrawler_redis.py 举例
运行:scrapy runspider example/spiders/myspider_redis.py
push urls to redis:redis-cli lpush myspider:start_urls http://baidu.com
RedisCrawlSpider 示例
以上面的 有缘 spider 示例进行改造。。。
首先添加任务,push urls to redis:( add_task.py ):

示例代码
import json
from scrapy.utils.project import get_project_settings
from scrapy_redis.connection import get_redis_from_settings
from scrapy_redis import connection
from scrapy_redis.queue import PriorityQueue
# def _encode_request(self, request):
# """Encode a request object"""
# obj = request_to_dict(request, self.spider)
# return self.serializer.dumps(obj)
#
#
# def _decode_request(self, encoded_request):
# """Decode an request previously encoded"""
# obj = self.serializer.loads(encoded_request)
# return request_from_dict(obj, self.spider)
def add_task_to_redis():
redis_key = 'start_urls:yy_spider_request'
url_string = 'http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/'
# 方法 1
server = get_redis_from_settings(get_project_settings())
server.lpush(redis_key, url_string)
# server.zadd(redis_key, url_string, 1000)
# 方法 2
# server = connection.from_settings(get_project_settings())
# server.execute_command('ZADD', redis_key, 1000, url_string)
if __name__ == '__main__':
# temp = 'test json string'
# print(json.dumps(temp))
add_task_to_redis()
pass
添加完任务,可以看到 redis 里面 的 start_urls:yy_spider_request 已经有添加的任务

修改 youyuan.py 的代码( redis_key 指明从哪个 key 里面获取任务 ):
# -*- coding: utf-8 -*-
import re
from abc import ABC
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
# 这两个还是 scrapy.spiders 中的 Spider, CrawlSpider
from scrapy_redis.spiders import Spider, CrawlSpider
# scrapy_redis 自定义的 RedisSpider, RedisCrawlSpider
from scrapy_redis.spiders import RedisSpider, RedisCrawlSpider
class YouYuanSpider(RedisCrawlSpider, ABC):
name = 'yy_spider'
allowed_domains = ['youyuan.com']
# 有缘网的列表页
# start_urls = ['http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/']
redis_key = 'start_urls:yy_spider_request'
pattern = re.compile(r'[0-9]')
# 提取列表页和 Profile 资料页的链接形成新的 request 保存到 redis 中等待调度
profile_page_lx = LinkExtractor(allow=(r'http://www.youyuan.com/\d+-profile/',))
page_lx = LinkExtractor(allow=(r'http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p\d+/',))
rules = (
Rule(page_lx, callback='parse_list_page', follow=True),
Rule(profile_page_lx, callback='parse_profile_page', follow=False),
)
def __init__(self):
super(YouYuanSpider, self).__init__()
self.temp = None
# 处理列表页,其实完全不用的,就是留个函数debug方便
def parse_list_page(self, response):
print(f"Processed list {response.url}")
# print response.body
self.profile_page_lx.extract_links(response)
pass
# 处理 Profile 资料页,得到我们要的 Profile
def parse_profile_page(self, response):
print(f"Processing profile {response.url}")
profile = dict()
profile['header_url'] = self.get_header_url(response)
profile['username'] = self.get_username(response)
profile['monologue'] = self.get_monologue(response)
profile['pic_urls'] = self.get_pic_urls(response)
profile['age'] = self.get_age(response)
profile['source'] = 'youyuan'
profile['source_url'] = response.url
# print "Processed profile %s" % response.url
yield profile
# 提取头像地址
def get_header_url(self, response):
self.temp = None
header = response.xpath('//dl[@class="personal_cen"]/dt/img/@src').extract()
if len(header) > 0:
header_url = header[0]
else:
header_url = ""
return header_url.strip()
# 提取用户名
def get_username(self, response):
self.temp = None
usernames = response.xpath('//dl[@class="personal_cen"]/dd/div/strong/text()').extract()
if len(usernames) > 0:
username = usernames[0]
else:
username = ""
return username.strip()
# 提取内心独白
def get_monologue(self, response):
self.temp = None
monologues = response.xpath('//ul[@class="requre"]/li/p/text()').extract()
if len(monologues) > 0:
monologue = monologues[0]
else:
monologue = ""
return monologue.strip()
# 提取相册图片地址
def get_pic_urls(self, response):
self.temp = None
pic_urls = []
data_url_full = response.xpath('//li[@class="smallPhoto"]/@data_url_full').extract()
if len(data_url_full) <= 1:
pic_urls.append("")
else:
for pic_url in data_url_full:
pic_urls.append(pic_url)
if len(pic_urls) <= 1:
return ""
return '|'.join(pic_urls)
# 提取年龄
def get_age(self, response):
age_urls = response.xpath('//dl[@class="personal_cen"]/dd/p[@class="local"]/text()').extract()
if len(age_urls) > 0:
age = age_urls[0]
else:
age = ""
age_words = re.split(' ', age)
if len(age_words) <= 2:
return "0"
# 20岁
age = age_words[2][:-1]
if self.pattern.match(age):
return age
return "0"
if __name__ == '__main__':
from scrapy import cmdline
cmdline.execute('scrapy crawl yy_spider'.split())
pass
run the spider:
scrapy runspider example/spiders/youyuan.py
或者 : scrapy crawl yy_spider
或者 : python youyuan.py抓取结果:

添加任务到 Redis 有序集合(sorted set)
思考:
- 现在添加的任务是到 redis 的 list 里面,怎么添加任务到 redis 的 有序集合中 ???
- 怎么实现队列中添加的任务是 json 格式的字符串 ???
- 使用布隆去重代替 scrapy_redis (分布式爬虫)自带的 dupefilter ???
后续说明怎么实现
防禁封策略 --- 分布式实战
以 丁香园用药助手( http://drugs.dxy.cn/ ) 项目为例。架构示意图如下:
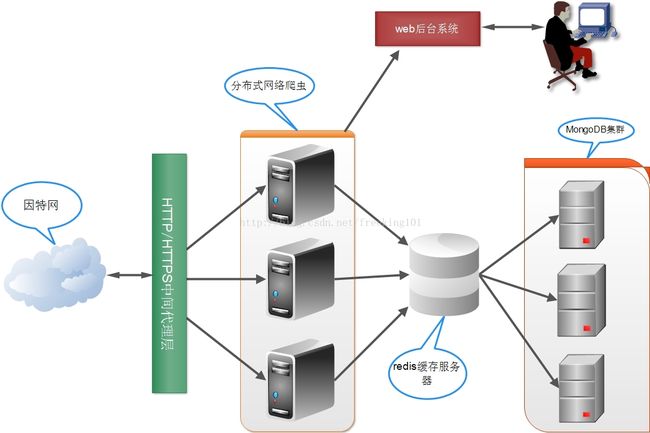
首先通过药理分类采集一遍,按照drug_id排序,发现:
我们要完成 http://drugs.dxy.cn/drug/[50000-150000].htm
正常采集:

异常数据情况包括如下:
- 药品不存在

- 当采集频率过快,弹出验证码

- 当天采集累计操作次数过多,弹出禁止

这个时候就需要用到代理
项目流程
1. 创建项目
scrapy startproject drugs_dxy
# 创建 spider
cd drugs_dxy/
scrapy genspider -t basic Drugs dxy.cn2. items.py 下添加类 DrugsItem
class DrugsItem(scrapy.Item):
# define the fields for your item here like:
#药品不存在标记
exists = scrapy.Field()
#药品id
drugtId = scrapy.Field()
#数据
data = scrapy.Field()
#标记验证码状态
msg = scrapy.Field()
pass3. 编辑 spider 下 DrugsSpider 类
# -*- coding: utf-8 -*-
# from drugs_dxy.items import DrugsItem
import re
import scrapy
from scrapy.spiders import Spider
class DrugsSpider(Spider):
name = "Drugs"
allowed_domains = ["dxy.cn"]
size = 60
def __init__(self):
super(DrugsSpider, self).__init__()
self.temp = None
def start_requests(self):
for i in range(50000, 50000 + self.size, 1):
url = f'http://drugs.dxy.cn/drug/{i}.htm'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
self.temp = None
# drug_Item = DrugsItem()
drug_item = dict()
drug_item["drugId"] = int(re.search(r'(\d+)', response.url).group(1))
if drug_item["drugId"] >= 150000:
return
url = f'http://drugs.dxy.cn/drug/{drug_item["drugId"] + self.size}.htm'
yield scrapy.Request(url=url, callback=self.parse)
if '药品不存在' in response.body:
drug_item['exists'] = False
yield drug_item
return
if '请填写验证码继续正常访问' in response.body:
drug_item["msg"] = '请填写验证码继续正常访问'
return
drug_item["data"] = {}
details = response.xpath("//dt")
for detail in details:
detail_name = detail.xpath('./span/text()').extract()[0].split(':')[0]
if detail_name == u'药品名称':
drug_item['data'][u'药品名称'] = {}
try:
detail_str = detail.xpath("./following-sibling::*[1]")
detail_value = detail_str.xpath('string(.)').extract()[0]
detail_value = detail_value.replace('\r', '').replace('\t', '').strip()
for item in detail_value.split('\n'):
item = item.replace('\r', '').replace('\n', '').replace('\t', '').strip()
name = item.split(u':')[0]
value = item.split(u':')[1]
drug_item['data'][u'药品名称'][name] = value
except BaseException as ex:
pass
else:
detail_str = detail.xpath("./following-sibling::*[1]")
detail_value = detail_str.xpath('string(.)').extract()[0]
detail_value = detail_value.replace('\r', '').replace('\t', '').strip()
# print detail_str,detail_value
drug_item['data'][detail_name] = detail_value
yield drug_item
if __name__ == '__main__':
from scrapy import cmdline
cmdline.execute('scrapy crawl Drugs'.split())
pass

4. Scrapy代理设置
4.1 在 settings.py 文件里
1)启用 scrapy_redis 组件
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
# Specify the host and port to use when connecting to Redis (optional).
REDIS_HOST = '101.200.170.171'
REDIS_PORT = 6379
# Custom redis client parameters (i.e.: socket timeout, etc.)
REDIS_PARAMS = {}
#REDIS_URL = 'redis://user:pass@hostname:9001'
REDIS_PARAMS['password'] = 'redis_password'2) 启用 DownLoader 中间件;httpproxy
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'drugs_dxy.middlewares.ProxyMiddleware': 400,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': None,
}3) 设置禁止跳转(code=301、302),超时时间90s
DOWNLOAD_TIMEOUT = 90
REDIRECT_ENABLED = False
4.2 在 drugs_dxy 目录下创建 middlewares.py 并编辑 (settings.py 同级目录)
# -*- coding: utf-8 -*-
import random
import base64
import Queue
import redis
class ProxyMiddleware(object):
def __init__(self, settings):
self.queue = 'Proxy:queue'
# 初始化代理列表
self.r = redis.Redis(host=settings.get('REDIS_HOST'),port=settings.get('REDIS_PORT'),db=1,password=settings.get('REDIS_PARAMS')['password'])
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings)
def process_request(self, request, spider):
proxy={}
source, data = self.r.blpop(self.queue)
proxy['ip_port']=data
proxy['user_pass']=None
if proxy['user_pass'] is not None:
#request.meta['proxy'] = "http://YOUR_PROXY_IP:PORT"
request.meta['proxy'] = "http://%s" % proxy['ip_port']
#proxy_user_pass = "USERNAME:PASSWORD"
encoded_user_pass = base64.encodestring(proxy['user_pass'])
request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_pass
print "********ProxyMiddleware have pass*****" + proxy['ip_port']
else:
#ProxyMiddleware no pass
print request.url, proxy['ip_port']
request.meta['proxy'] = "http://%s" % proxy['ip_port']
def process_response(self, request, response, spider):
"""
检查response.status, 根据status是否在允许的状态码中决定是否切换到下一个proxy, 或者禁用proxy
"""
print("-------%s %s %s------" % (request.meta["proxy"], response.status, request.url))
# status不是正常的200而且不在spider声明的正常爬取过程中可能出现的
# status列表中, 则认为代理无效, 切换代理
if response.status == 200:
print 'rpush',request.meta["proxy"]
self.r.rpush(self.queue, request.meta["proxy"].replace('http://',''))
return response
def process_exception(self, request, exception, spider):
"""
处理由于使用代理导致的连接异常
"""
proxy={}
source, data = self.r.blpop(self.queue)
proxy['ip_port']=data
proxy['user_pass']=None
request.meta['proxy'] = "http://%s" % proxy['ip_port']
new_request = request.copy()
new_request.dont_filter = True
return new_requestredis-scrapy
settings.py 千万不能添加:LOG_STDOUT=True