pyspider登陆并取新闻并自动分析
工作中可能会接到各种要求抓取的网站, 但是并不是所有的网站的抓取规则都会很繁琐, 或者需要登录的,
偶尔会遇到几个,大部分都是那种静态的,ajax加载的,
今天就简单的用Pyspider写个国外的新闻网站 https://energy.einnews.com, 先来简单的看下这个网站

- 抓取这里面的新闻的日期,时间,和新闻内容
随便打开一篇新闻看看
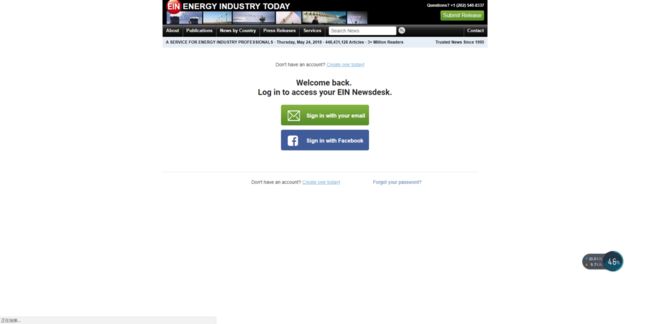
- 点开链接后发现,看这篇新闻都要让你登陆,真是…
我们随便注册个账号登陆下试试.

- 登陆后显示原文

- 我们来看看他提交了哪些参数.

aemail : 你的账号
apass : 你的密码
url: 链接
remember: on
-
然后再来看看网页的结构,要抓取的内容都在网页的哪部分
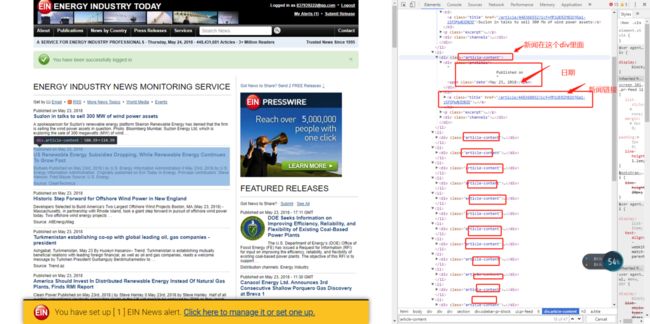
-
要的新闻在div[@class=“content”] 这个标签里

-
翻页链接

- 问题来了
1.写的过程中发现有的时间格式并不统一 当天的新闻只显示时间不显示日期,所以要把那些没有日期的单独处理,默认为当天的日期就OK

2. 进入新闻页后你会发现这篇新闻的内容并不在源码中

在network里面一顿搜索你就会找他的原文的地址,是不是很烦躁,但是令人惊喜的是复制这个链接,
在网页源码中可以搜到这个链接!!!
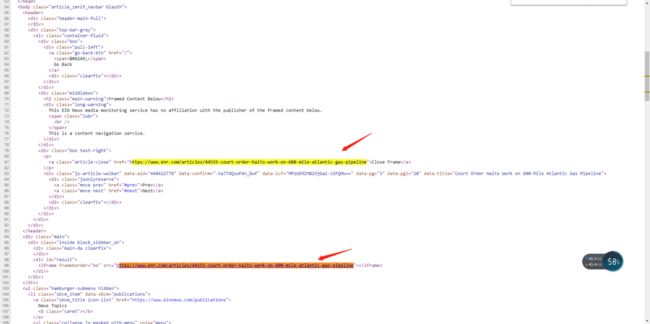
ok 那在请求写这个链接获取新闻内容
- 新闻原文的链接的主域名居然是不一样的!!!新闻页的html结构也是不一样的!!!要怎么提取新闻内容!!!
把它交给newspaper这个模块去自动分析吧,
可以自动获取新闻内容,摘要,title等等
- OK, 问题解决
上代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-05-24 15:09:19
# Project: Einnews
from pyspider.libs.base_handler import *
import requests
import newspaper
from datetime import datetime
default_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
#登陆获取cookies
def get_cookies():
login_url = 'https://energy.einnews.com/account/login'
login_data = {
'aemail':'账号',
'apass':'密码',
'url':'https://energy.einnews.com/',
'remember':'on'
}
res = requests.get(login_url, data=login_data, headers=default_headers)
cookies = res.cookies
default_cookies = {}
for item in cookies:
default_cookies[item.name] = item.value
return default_cookies
class Handler(BaseHandler):
crawl_config = {
'headers': default_headers,
'timeout': 300,
'cookies':get_cookies()
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://energy.einnews.com/news/brent-crude-opec', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('div[@class="article-content"] h3 a').items():
news_title = each.find('a').text()
#时间处理,报错即为格式不符合的 修改为当天日期
try:
news_date = datetime.strptime(each.find('span.date'),'%B %d, %Y').strftime('%Y-%m-%d')
except:
news_date = datetime.now().strftime('%Y-%m-%d')
self.crawl(each.attr.href, save={'tt':news_title, 'url': response.url, 'dt': news_date}, callback=self.get_real_url)
for each in response.doc('div[@class="pagination pagination-centered"] ul a').items():
self.crawl(each.attr.href, callback=self.index_page)
#获取真正的新闻url
def get_real_url(self, response):
url = response.doc('a.article-close').attr.href
self.crawl(url, save={'tt':response.save['tt'], 'url': response.save['url'], 'dt': response.save['dt']}, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
news_html = response.text
#利用newspaper模块自动处理新闻信息
news_parse = newspaper.Article(url=response.url, html=news_html, language="en")
news_parse.build()
result = {
#新闻标题
'title':response.save['tt'],
#新闻添加时间
'addtime':response.save['dt'],
#新闻keywords
'tag' : news_parse.keywords,
#新闻摘要
'introduce' : news_parse.summary,
#新闻原文
'content' : news_parse.text,
'fromurl':response.url,
'copyfrom':response.save['url'],
'catid': 5,
'auth' : '123456'
}
print(result)
return result
def on_result(self, result):
if not result or not result['title'] or not result['content'] or not result['introduce']:
return
else :
print(result)
#r = requests.post('发送至数据接收API', data = result)
#print(r.text)
run一下



#总结:
- 刚刚学python爬虫也没多久,希望能遇到很多想一起学习的朋友,一起交流,学习。
如果有写的不对的地方,或者有更好的方法,不用给面子,大胆的说出来,哈哈哈哈哈哈