deeplearning.ai题目记录
课程在网易云课堂上免费观看,作业题如下:加粗为答案。
神经网络和深度学习
第一周 深度学习概论
10个选择题,原见Github
- What does the analogy “AI is the new electricity” refer to?
- Similar to electricity starting about 100 years ago, AI is transforming multiple industries.
- Through the “smart grid”, AI is delivering a new wave of electricity.
- AI runs on computers and is thus powered by electricity, but it is letting computers do things not possible before.
- AI is powering personal devices in our homes and offices, similar to electricity.
- Which of these are reasons for Deep Learning recently taking off? (Check the three options that apply.)
- Deep learning has resulted in significant improvements in important applications such as online advertising, speech recognition, and image recognition.
- We have access to a lot more data.
- We have access to a lot more computational power.
- Neural Networks are a brand new field.
- Recall this diagram of iterating over different ML ideas. Which of the statements below are true? (Check all that apply.)
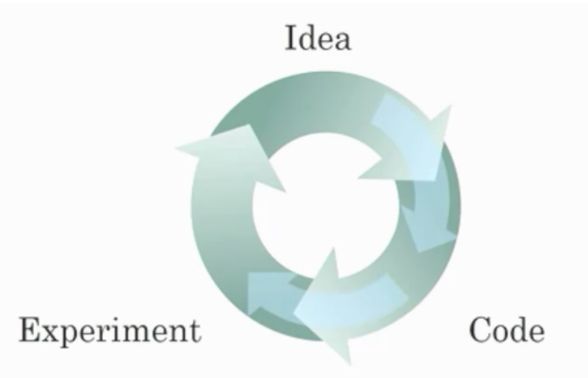
- Being able to try out ideas quickly allows deep learning engineers to iterate more quickly.
- Faster computation can help speed up how long a team takes to iterate to a good idea.
- It is faster to train on a big dataset than a small dataset.
- Recent progress in deep learning algorithms has allowed us to train good models faster (even without changing the CPU/GPU hardware).
- When an experienced deep learning engineer works on a new problem, they can usually use insight from previous problems to train a good model on the first try, without needing to iterate multiple times through different models. True/False?
- True
- False
- Which one of these plots represents a ReLU activation function?
- Figure 1:

- Figure 2:

- Figure 3:

- Figure 4:

- Figure 1:
- Images for cat recognition is an example of “structured” data, because it is represented as a structured array in a computer. True/False?
- True
- False
- A demographic dataset with statistics on different cities’ population, GDP per capita, economic growth is an example of “unstructured” data because it contains data coming from different sources. True/False?
- True
- False
- Why is an RNN (Recurrent Neural Network) used for machine translation, say translating English to French? (Check all that apply.)
- It can be trained as a supervised learning problem.
- It is strictly more powerful than a Convolutional Neural Network (CNN).
- It is applicable when the input/output is a sequence (e.g., a sequence of words).
- RNNs represent the recurrent process of Idea->Code->Experiment->Idea->….
- In this diagram which we hand-drew in lecture, what do the horizontal axis (x-axis) and vertical axis (y-axis) represent?

-
- x-axis is the performance of the algorithm
- y-axis (vertical axis) is the amount of data.
-
- x-axis is the input to the algorithm
- y-axis is outputs.
-
- x-axis is the amount of data
- y-axis is the size of the model you train.
-
- x-axis is the amount of data
- y-axis (vertical axis) is the performance of the algorithm.
-
- Assuming the trends described in the previous question’s figure are accurate (and hoping you got the axis labels right), which of the following are true? (Check all that apply.)
- Decreasing the training set size generally does not hurt an algorithm’s performance, and it may help significantly.
- Decreasing the size of a neural network generally does not hurt an algorithm’s performance, and it may help significantly.
- Increasing the training set size generally does not hurt an algorithm’s performance, and it may help significantly.
- Increasing the size of a neural network generally does not hurt an algorithm’s performance, and it may help significantly.
第二周 Logistic Regression
Neural-Network-Basics
10个选择题,原见Github
- What does a neuron compute?
- A neuron computes an activation function followed by a linear function (z = Wx + b)
- A neuron computes a linear function (z = Wx + b) followed by an activation function
- A neuron computes a function g that scales the input x linearly (Wx + b)
- A neuron computes the mean of all features before applying the output to an activation function
- Which of these is the “Logistic Loss”?
- L(i)(y^(i),y(i))=−(y(i)log(y^(i))+(1−y(i))log(1−y^(i))) L ( i ) ( y ^ ( i ) , y ( i ) ) = − ( y ( i ) log ( y ^ ( i ) ) + ( 1 − y ( i ) ) log ( 1 − y ^ ( i ) ) ) True
- L(i)(y^(i),y(i))=|y(i)−y^(i)| L ( i ) ( y ^ ( i ) , y ( i ) ) = | y ( i ) − y ^ ( i ) |
- L(i)(y^(i),y(i))=max(0,y(i)−y^(i)) L ( i ) ( y ^ ( i ) , y ( i ) ) = max ( 0 , y ( i ) − y ^ ( i ) )
- L(i)(y^(i),y(i))=|y(i)−y^(i)|2 L ( i ) ( y ^ ( i ) , y ( i ) ) = | y ( i ) − y ^ ( i ) | 2
- Suppose img is a (32,32,3) array, representing a 32x32 image with 3 color channels red, green and blue. How do you reshape this into a column vector?
x = img.reshape((32*32*3,1))x = img.reshape((32*32,3))x = img.reshape((1,32*32,*3))x = img.reshape((3,32*32))
- Consider the two following random arrays “a” and “b”:
python
a = np.random.randn(2, 3) # a.shape = (2, 3)
b = np.random.randn(2, 1) # b.shape = (2, 1)
c = a + b
What will be the shape of “c”?
- c.shape = (2, 1)
- c.shape = (3, 2)
- c.shape = (2, 3)
- The computation cannot happen because the sizes don’t match. It’s going to be “Error”!
- Consider the two following random arrays “a” and “b”:
python
a = np.random.rand(4, 3) # a.shape = (4, 3)
b = np.random.rand(3, 2) # a.shape = (3, 2)
c = a*b
What will be the shape of “c”?
- c.shape = (4, 2)
- c.shape = (4, 3)
- The computation cannot happen because the sizes don’t match. It’s going to be “Error”!
- c.shape = (3, 3)
- Suppose you have nx n x input features per example. Recall that X=[x(2)x(m)...x(1)] X = [ x ( 2 ) x ( m ) . . . x ( 1 ) ] . What is the dimension of X?
- (m, 1)
- ( nx n x , m)
- (m, nx n x )
- (1, m)
- Recall that “np.dot(a,b)” performs a matrix multiplication on a and b, whereas “a*b” performs an element-wise multiplication.
Consider the two following random arrays “a” and “b”:
python
a = np.random.randn(12288, 150) # a.shape = (12288, 150)
b = np.random.randn(150, 45) # b.shape = (150, 45)
c = np.dot(a, b)
What is the shape of c?
- The computation cannot happen because the sizes don’t match. It’s going to be “Error”!
- c.shape = (12288, 150)
- c.shape = (12288, 45)
- c.shape = (150,150)
Consider the following code snippet:
# a.shape = (3, 4) # b.shape = (4, 1) for i in range(3): for j in range(4): c[i][j] = a[i][j] + b[j]How do you vectorize this?
- c = a.T + b
- c = a.T + b.T
- c = a + b.T
- c = a + b
- Consider the following code:
python
a = np.random.randn(3, 3)
b = np.random.randn(3, 1)
c = a * b
What will be c? (If you’re not sure, feel free to run this in python to find out).
- This will invoke broadcasting, so b is copied three times to become (3,3), and ∗ is an element-wise product so c.shape will be (3, 3)
- This will invoke broadcasting, so b is copied three times to become (3, 3), and ∗ invokes a matrix multiplication operation of two 3x3 matrices so c.shape will be (3, 3)
- This will multiply a 3x3 matrix a with a 3x1 vector, thus resulting in a 3x1 vector. That is, c.shape = (3,1).
- It will lead to an error since you cannot use “*” to operate on these two matrices. You need to instead use np.dot(a,b)
- Consider the following computation graph.

What is the output J?
J = (c - 1)*(b + a)J = (a - 1) * (b + c)J = a*b + b*c + a*cJ = (b - 1) * (c + a)
Logistic-Regression-with-a-Neural-Network-mindset
相关数据集和输出见github
第三周 浅层神经网络
Shallow Neural Networks
10个选择题,原见Github
- Which of the following are true? (Check all that apply.)
- a[2] a [ 2 ] denotes the activation vector of the 2nd 2 n d layer.
- a[2](12) a [ 2 ] ( 12 ) denotes the activation vector of the 2nd 2 n d layer for the 12th 12 t h training example.
- X X is a matrix in which each row is one training example.
- a[2](12) a [ 2 ] ( 12 ) denotes activation vector of the 12th 12 t h layer on the 2nd 2 n d training example.
- X X is a matrix in which each column is one training example.
- a[2]4 a 4 [ 2 ] is the activation output by the 4th 4 t h neuron of the 2nd 2 n d layer
- a[2]4 a 4 [ 2 ] is the activation output of the 2nd 2 n d layer for the 4th 4 t h training example
- The tanh activation usually works better than sigmoid activation function for hidden units because the mean of its output is closer to zero, and so it centers the data better for the next layer. True/False?
- True
- False
- Which of these is a correct vectorized implementation of forward propagation for layer l l , where 1≤l≤L 1 ≤ l ≤ L ?
-
- Z[l]=W[l]A[l]+b[l] Z [ l ] = W [ l ] A [ l ] + b [ l ]
- A[l+1]=g[l+1](Z[l]) A [ l + 1 ] = g [ l + 1 ] ( Z [ l ] )
-
- Z[l]=W[l]A[l−1]+b[l] Z [ l ] = W [ l ] A [ l − 1 ] + b [ l ] True
- A[l]=g[l](Z[l]) A [ l ] = g [ l ] ( Z [ l ] ) True
-
- Z[l]=W[l]A[l]+b[l] Z [ l ] = W [ l ] A [ l ] + b [ l ]
- A[l+1]=g[l](Z[l]) A [ l + 1 ] = g [ l ] ( Z [ l ] )
-
- Z[l]=W[l−1]A[l]+b[l−1] Z [ l ] = W [ l − 1 ] A [ l ] + b [ l − 1 ]
- A[l]=g[l](Z[l]) A [ l ] = g [ l ] ( Z [ l ] )
-
- You are building a binary classifier for recognizing cucumbers (y=1) vs. watermelons (y=0). Which one of these activation functions would you recommend using for the output layer?
- ReLU
- Leaky ReLU
- sigmoid
- tanh
- Consider the following code:
python
A = np.random.randn(4, 3)
B = np.sum(A, axis = 1, keepdims = True)
What will be B.shape? (If you’re not sure, feel free to run this in python to find out).
- (4, 1)
- (4, )
- (1, 3)
- (, 3)
- Suppose you have built a neural network. You decide to initialize the weights and biases to be zero. Which of the following statements is true?
- Each neuron in the first hidden layer will perform the same computation. So even after multiple iterations of gradient descent each neuron in the layer will be computing the same thing as other neurons.
- Each neuron in the first hidden layer will perform the same computation in the first iteration. But after one iteration of gradient descent they will learn to compute different things because we have “broken symmetry”.
- Each neuron in the first hidden layer will compute the same thing, but neurons in different layers will compute different things, thus we have accomplished “symmetry breaking” as described in lecture.
- The first hidden layer’s neurons will perform different computations from each other even in the first iteration; their parameters will thus keep evolving in their own way.
- Logistic regression’s weights w should be initialized randomly rather than to all zeros, because if you initialize to all zeros, then logistic regression will fail to learn a useful decision boundary because it will fail to “break symmetry”, True/False?
- True
- False
- You have built a network using the tanh activation for all the hidden units. You initialize the weights to relative large values, using np.random.randn(..,..)*1000. What will happen?
- This will cause the inputs of the tanh to also be very large, thus causing gradients to be close to zero. The optimization algorithm will thus become slow.
- This will cause the inputs of the tanh to also be very large, causing the units to be “highly activated” and thus speed up learning compared to if the weights had to start from small values.
- It doesn’t matter. So long as you initialize the weights randomly gradient descent is not affected by whether the weights are large or small.
- This will cause the inputs of the tanh to also be very large, thus causing gradients to also become large. You therefore have to set α to be very small to prevent divergence; this will slow down learning.
- Consider the following 1 hidden layer neural network:

Which of the following statements are True? (Check all that apply).
- W[1] W [ 1 ] will have shape (2, 4)
- b[1] b [ 1 ] will have shape (4, 1)
- W[1] W [ 1 ] will have shape (4, 2)
- b[1] b [ 1 ] will have shape (2, 1)
- W[2] W [ 2 ] will have shape (1, 4)
- b[2] b [ 2 ] will have shape (4, 1)
- W[2] W [ 2 ] will have shape (4, 1)
- b[2] b [ 2 ] will have shape (1, 1)
- In the same network as the previous question, what are the dimensions of Z[1] Z [ 1 ] and A[1] A [ 1 ] ?
- Z[1] Z [ 1 ] and A[1] A [ 1 ] are (1, 4)
- Z[1] Z [ 1 ] and A[1] A [ 1 ] are (4, 2)
- Z[1] Z [ 1 ] and A[1] A [ 1 ] are (4, m)
- Z[1] Z [ 1 ] and A[1] A [ 1 ] are (4, 1)
Planar data classification with one hidden layer
相关数据集和输出见github
第四周 深层神经网络
Key concepts on Deep Neural Network
- What is the “cache” used for in our implementation of forward propagation and backward propagation?
- We use it to pass variables computed during forward propagation to the corresponding backward propagation step. It contains useful values for backward propagation to compute derivatives.
- We use it to pass variables computed during backward propagation to the corresponding forward propagation step. It contains useful values for forward propagation to compute activations.
- It is used to cache the intermediate values of the cost function during training.
- It is used to keep track of the hyperparameters that we are searching over, to speed up computation.
- Among the following, which ones are “hyperparameters”? (Check all that apply.)
- size of the hidden layers n[l] n [ l ]
- number of layers L L in the neural network
- learning rate α α
- activation values a[l] a [ l ]
- number of iterations
- weight matrices W[l] W [ l ]
- bias vectors b[l] b [ l ]
- Which of the following statements is true?
- The deeper layers of a neural network are typically computing more complex features of the input than the earlier layers.
- The earlier layers of a neural network are typically computing more complex features of the input than the deeper layers.
- Vectorization allows you to compute forward propagation in an L L -layer neural network without an explicit for-loop (or any other explicit iterative loop) over the layers l=1, 2, …,L. True/False?
- True
- False
- Assume we store the values for n[l] n [ l ] in an array called layers, as follows: layer_dims = [ nx n x , 4,3,2,1]. So layer 1 has four hidden units, layer 2 has 3 hidden units and so on. Which of the following for-loops will allow you to initialize the parameters for the model?
- Code1
python
for (i in range(1, len(layer_dims)/2)):
parameter['w' + str(i)] = np.random.randn(layers[i], layers[i-1]) * 0.01
parameter['b' + str(i)] = np.random.randn(layers[i], 1) * 0.01
- Code2
python
for (i in range(1, len(layer_dims)/2)):
parameter['w' + str(i)] = np.random.randn(layers[i], layers[i-1]) * 0.01
parameter['b' + str(i)] = np.random.randn(layers[i-1], 1) * 0.01
- Code3
python
for (i in range(1, len(layer_dims))):
parameter['w' + str(i)] = np.random.randn(layers[i-1], layers[i]) * 0.01
parameter['b' + str(i)] = np.random.randn(layers[i], 1) * 0.01
- Code4
python
for (i in range(1, len(layer_dims))):
parameter['w' + str(i)] = np.random.randn(layers[i], layers[i-1]) * 0.01
parameter['b' + str(i)] = np.random.randn(layers[i], 1) * 0.01
- Code1
- Consider the following neural network.
[图片上传失败…(image-4d5dce-1513913878329)]
How many layers does this network have?
- The number of layers L L is 4. The number of hidden layers is 3.
- The number of layers L L is 3. The number of hidden layers is 3.
- The number of layers L L is 4. The number of hidden layers is 4.
- The number of layers L L is 5. The number of hidden layers is 4.
- During forward propagation, in the forward function for a layer l l you need to know what is the activation function in a layer (Sigmoid, tanh, ReLU, etc.). During backpropagation, the corresponding backward function also needs to know what is the activation function for layer l l , since the gradient depends on it. True/False?
- True
- False
- There are certain functions with the following properties:
(i) To compute the function using a shallow network circuit, you will need a large network (where we measure size by the number of logic gates in the network), but (ii) To compute it using a deep network circuit, you need only an exponentially smaller network. True/False?
- True
- False
- Consider the following 2 hidden layer neural network:

Which of the following statements are True? (Check all that apply).
- W[1] will have shape (4, 4)
- b[1] will have shape (4, 1)
- W[1] will have shape (3, 4)
- b[1] will have shape (3, 1)
- W[2] will have shape (3, 4)
- b[2] will have shape (1, 1)
- W[2] will have shape (3, 1)
- b[2] will have shape (3, 1)
- W[3] will have shape (3, 1)
- b[3] will have shape (1, 1)
- W[3] will have shape (1, 3)
- b[3] will have shape (3, 1)
- Whereas the previous question used a specific network, in the general case what is the dimension of W^{[l]}, the weight matrix associated with layer l l ?
- W[l] has shape (n[l],n[l−1])
- W[l] has shape (n[l+1],n[l])
- W[l] has shape (n[l],n[l+1])
- W[l] has shape (n[l−1],n[l])
Building your Deep Neural Network - Step by Step
ipynb
Deep Neural Network - Application
ipynb
改善深层神经网络:超参数调试、正则化以及优化
网址
第一周 深度学习的实用层面
Practical aspects of deep learning
- If you have 10,000,000 examples, how would you split the train/dev/test set?
- 60% train . 20% dev . 20% test
- 98% train . 1% dev . 1% test
- 33% train . 33% dev . 33% test
- The dev and test set should:
- Come from the same distribution
- Come from different distributions
- Be identical to each other (same (x,y) pairs)
- Have the same number of examples
- If your Neural Network model seems to have high variance, what of the following would be promising things to try?
- Add regularization
- Make the Neural Network deeper
- Increase the number of units in each hidden layer
- Get more test data
- Get more training data
- You are working on an automated check-out kiosk for a supermarket, and are building a classifier for apples, bananas, and oranges. Suppose your classifier obtains a training set error of 0.5%, and a dev set error of 7%, Which of the following are promising things to try to improve your classfier? (Check all that apply.)
- Increase the regularization parameter lambda
- Decrease the regularization parameter lambda
- Get more training data
- Use a bigger neural network
- What is weight decay?
- Gradual corruption of the weights in the neural network if it is trained on noisy data.
- A technique to avoid vanishing gradient by imposing a ceiling on the values of the weights.
- A regularization technique (such as L2 regularization) that results in gradient descent shrinking the weights on every iteration.
- The process of gradually decreasing the learning rate during training.
- What happens when you increase the regularization hyperparameter lambda?
- Weights are pushed toward becoming smaller (closer to 0)
- Weights are pushed toward becoming bigger (further from 0)
- Doubling lambda should roughly result in doubling the weights
- Gradient descent taking bigger steps with each iteration (proportional to lambda)
- With the inverted dropout technique, at test time:
- You apply dropout (randomly eliminating units) and do not keep the 1/keep_prob factor in the calculations used in training
- You do not apply dropout (do not randomly eliminate units), but keep the 1/keep_prob factor in the calculations used in training.
- You do not apply dropout (do not randomly eliminate units) and do not keep the 1/keep_prob factor in the calculations used in training
- You apply dropout (randomly eliminating units) but keep the 1/keep_prob factor in the calculations used in training.
- Increasing the parameter keep_prob from (say) 0.5 to 0.6 will likely cause the following: (Check the two that apply)
- Increasing the regularization effect
- Reducing the regularization effect
- Causing the neural network to end up with a higher training set error
- Causing the neural network to end up with a lower training set error
- Which of these techniques are useful for reducing variance (reducing overfitting)? (Check all that apply.)
- Data augmentation
- Gradient Checking
- Exploding gradient
- L2 regularization
- Dropout
- Vanishing gradient
- Xavier initialization
- Why do we normalize the inputs x?
- It makes it easier to visualize the data
- It makes the parameter initialization faster
- Normalization is another word for regularization–It helps to reduce variance
- It makes the cost function faster to optimize
Regularization
ipynb
Initialization
ipynb
Gradient_Checking
ipynb
第二周 优化算法
Optimization algorithms
- Which notation would you use to denote the 3rd layer’s activations when the input is the 7th example from the 8th minibatch?
- a[8]{3}(7)
- a[3]{7}(8)
- a[8]{7}(3)
- a[3]{8}(7)
- Which of these statements about mini-batch gradient descent do you agree with?
- Training one epoch (one pass through the training set) using minibatch gradient descent is faster than training one epoch using batch gradient descent.
- One iteration of mini-batch gradient descent (computing on a single mini-batch) is faster than one iteration of batch gradient descent.
- You should implement mini-batch gradient descent without an explicit for-loop over different mini-batches, so that the algorithm processes all mini-batches at the same time(vectorization).
- Why is the best mini-batch size usually not 1 and not m, but instead something in-between?
- If the mini-batch size is m, you end up with batch gradient descent, which has to process the whole training set before making progress.
- If the mini-batch size is m, you end up with stochastic gradient descent, which is usually slower than mini-batch gradient descent.
- If the mini-batch size is 1, you lose the benefits of vectorization across examples in the mini-batch.
- If the mini-batch size is 1, you end up having to process the entire training set before making any progress.
- Suppose your learning algorithm’s cost , plotted as a function of the number of iterations, looks like this:

Which of the following do you agree with?
- Whether you’re using batch gradient descent or mini-batch gradient descent, this looks acceptable.
- If you’re using mini-batch gradient descent, this looks acceptable. But if you’re using batch gradient descent, something is wrong.
- Whether you’re using batch gradient descent or mini-batch gradient descent, something is wrong.
- If you’re using mini-batch gradient descent, something is wrong. But if you’re using batch gradient descent, this looks acceptable.
- Suppose the temperature in Casablanca over the first three days of January are the same:
Jan 1st: θ1=10∘C θ 1 = 10 ∘ C
Jan 2nd: θ2=10∘C θ 2 = 10 ∘ C
(We used Fahrenheit in lecture, so will use Celsius here in honor of the metric world.)
Say you use an exponentially weighted average with β=0.5 β = 0.5 to track the temperature: v0=0,vt=βvt−1+(1−β)θt v 0 = 0 , v t = β v t − 1 + ( 1 − β ) θ t . If v2 v 2 is the value computed after day 2 without bias correction, and vcorrected2 v 2 c o r r e c t e d is the value you compute with bias correction. What are these values? (You might be able to do this without a calculator, but you don’t actually need one. Remember what is bias correction doing.)
- v2=7.5,vcorrected2=7.5 v 2 = 7.5 , v 2 c o r r e c t e d = 7.5
- v2=10,vcorrected2=7.5 v 2 = 10 , v 2 c o r r e c t e d = 7.5
- v2=10,vcorrected2=10 v 2 = 10 , v 2 c o r r e c t e d = 10
- v2=7.5,vcorrected2=10 v 2 = 7.5 , v 2 c o r r e c t e d = 10 True
- Which of these is NOT a good learning rate decay scheme? Here, t is the epoch number.
- α=11+2∗tα0 α = 1 1 + 2 ∗ t α 0
- α=etα0 α = e t α 0 True
- α=0.95tα0 α = 0.95 t α 0
- α=1t√α0 α = 1 t α 0
- You use an exponentially weighted average on the London temperature dataset. You use the following to track the temperature: vt=βvt−1+(1−β)θt v t = β v t − 1 + ( 1 − β ) θ t . The red line below was computed using β=0.9 β = 0.9 . What would happen to your red curve as you vary β β ? (Check the two that apply)

- Decreasing β β will shift the red line slightly to the right.
- Increasing β β will shift the red line slightly to the right.
- Decreasing β β will create more oscillation within the red line.
- Increasing β β will create more oscillations within the red line.
- Consider this figure:

These plots were generated with gradient descent; with gradient descent with momentum ( β β = 0.5) and gradient descent with momentum ( β β = 0.9). Which curve corresponds to which algorithm?
- (1) is gradient descent with momentum (small β β ). (2) is gradient descent. (3) is gradient descent with momentum (large β β )
- (1) is gradient descent. (2) is gradient descent with momentum (large β β ) . (3) is gradient descent with momentum (small β β )
- (1) is gradient descent. (2) is gradient descent with momentum (small β β ). (3) is gradient descent with momentum (large β β )
- (1) is gradient descent with momentum (small β β ), (2) is gradient descent with momentum (small β β ), (3) is gradient descent
- Suppose batch gradient descent in a deep network is taking excessively long to find a value of the parameters that achieves a small value for the cost function J(W[1],b[1],...,W[L],b[L]) J ( W [ 1 ] , b [ 1 ] , . . . , W [ L ] , b [ L ] ) . Which of the following techniques could help find parameter values that attain a small value for J J ? (Check all that apply)
- Try initializing all the weights to zero
- Try tuning the learning rate α α
- Try better random initialization for the weights
- Try using Adam
- Try mini-batch gradient descent
- Which of the following statements about Adam is False?
- Adam should be used with batch gradient computations, not with mini-batches.
- We usually use “default” values for the hyperparameters and in Adam ( β1=0.9 β 1 = 0.9 , β2=0.999 β 2 = 0.999 , ε=10−8 ε = 10 − 8 )
- The learning rate hyperparameter α α in Adam usually needs to be tuned.
- Adam combines the advantages of RMSProp and momentum
第三周 超参数调试、Batch正则化和程序框架
Hyperparameter tuning, Batch Normalization, Programming Frameworks
- If searching among a large number of hyperparameters, you should try values in a grid rather than random values, so that you can carry out the search more systematically and not rely on chance. True or False?
- True
- False
- Every hyperparameter, if set poorly, can have a huge negative impact on training, and so all hyperparameters are about equally important to tune well. True or False?
- True
- False
- During hyperparameter search, whether you try to babysit one model (“Panda” strategy) or train a lot of models in parallel (“Caviar”) is largely determined by:
- Whether you use batch or mini-batch optimization
- The presence of local minima (and saddle points) in your neural network
- The amount of computational power you can access
- The number of hyperparameters you have to tune
- If you think β β (hyperparameter for momentum) is between on 0.9 and 0.99, which of the following is the recommended way to sample a value for beta?
- Code1
python
r = np.random.rand()
beta = r*0.09 + 0.9
- Code2
python
r = np.random.rand()
beta = 1-10**(- r - 1)
- Code3
python
r = np.random.rand()
beta = 1-10**(- r + 1)
- Code4
python
r = np.random.rand()
beta = r*0.9 + 0.09
- Code1
- Finding good hyperparameter values is very time-consuming. So typically you should do it once at the start of the project, and try to find very good hyperparameters so that you don’t ever have to revisit tuning them again. True or false?
- True
- False
- In batch normalization as presented in the videos, if you apply it on the l l th layer of your neural network, what are you normalizing?
- z[l] z [ l ] True
- W[l] W [ l ]
- a[l] a [ l ]
- b[l] b [ l ]
- In the normalization formula z(i)norm=z(i)−μσ2+ε√ z n o r m ( i ) = z ( i ) − μ σ 2 + ε , why do we use epsilon?
- To have a more accurate normalization
- To avoid division by zero
- In case μ is too small
- To speed up convergence
- Which of the following statements about γ γ and β β in Batch Norm are true?
- They can be learned using Adam, Gradient descent with momentum, or RMSprop, not just with gradient descent.
- β and γ are hyperparameters of the algorithm, which we tune via random sampling.
- They set the mean and variance of the linear variable z[ l] of a given layer.
- There is one global value of γ∈R γ ∈ R and one global value of β∈R β ∈ R for each layer, and applies to all the hidden units in that layer.
- The optimal values are γ = σ2+ε−−−−−√ σ 2 + ε , and β
- After training a neural network with Batch Norm, at test time, to evaluate the neural network on a new example you should:
- Use the most recent mini-batch’s value of μ and σ2 to perform the needed normalizations
- If you implemented Batch Norm on mini-batches of (say) 256 examples, then to evaluate on one test example, duplicate that example 256 times so that you’re working with a mini-batch the same size as during training.
- Perform the needed normalizations, use μ and σ2 estimated using an exponentially weighted average across mini-batches seen during training.
- Skip the step where you normalize using and since a single test example cannot be normalized.
- Which of these statements about deep learning programming frameworks are true? (Check all that apply)
- Even if a project is currently open source, good governance of the project helps ensure that the it remains open even in the long term, rather than become closed or modified to benifit only one company.
- A programming framework allows you to code up deep learning algorithms with typically fewer lines of code than a lower-level language such as Python.
TensorFlow Tutorial
ipynb