jupyter notebook使用心得
- 下列语句可以输出代码默认的保存路径:
import os
print(os.path.abspath('.'))
- 常用的快捷键是:
Ctrl + Enter: 执行单元格代码
Shift + Enter: 执行单元格代码并且移动到下一个单元格
Alt + Enter: 执行单元格代码,新建并移动到下一个单元格
- 文件默认存储路径怎么改?
- 第一步:找到配置文件
菜单中打开Anaconda Prompt
输入命令 jupyter notebook --generate-config
根据上面运行处的路径打开C:\Users\HS\.jupyter\jupyter_notebook_config.py文件
- 第二步:更改配置
找到 #c.NotebookApp.notebook_dir = '',去掉该行前面的“#”;在打算存放文件的位置先新建一个文件夹(很重要,最好是英文的),然后将新的路径设置在单引号中,保存配置文件
重新启动Jupyte Notebook即可
- pip安装sklearn
pip install -U scikit-learn
它就会帮你下载新的scipy、numpy、scikit-learn,并且卸载原有的。
- pip安装pandas
- pip3 install pandas 安装,注意是pip3
- pip show pandas 查看当前环境是否有pandas
- 通过Anaconda安装Graphviz
先安装graphviz程序才行,参考博客:https://blog.csdn.net/HNUCSEE_LJK/article/details/86772806
在终端窗口一次输入:
conda install graphvizpip install graphviz
添加环境变量
找到Graphviz的安装路径,然后添加到环境变量中即可。我的安装路径是
C:\Users\linxid\Anaconda3\Library\bin\graphviz
- Jupyter notebook查看函数(方法)用法快捷键
光标直接放上面再按快捷键
Shift+Tab就可以
- Jupyter notebook快捷键总结
tab键,整个块就会缩进
按下 shift + tab 就会反向缩进
1. Jupyter Notebook有两种mode
- Enter:进入edit模式
- Esc:进入command模式
2. Command命令快捷键:
- A:在上方增加一个cell
- B:在下方增加一个cell
- X:剪切该cell
- C:复制该cell
- V:在该cell下方粘贴复制的cell
- Shift-V:在该cell上方粘贴复制的cell
- L:隐藏、显示当前cell的代码行号
- shift-L:隐藏/显示所有cell的代码行号
- O:隐藏该cell的output
- DD:删除这个cell
- Z:撤销删除操作
- Y:转为code模式
- M:转为markdown模式
- R:转为raw模式
- H:展示快捷键帮助
- Shift-Enter:运行本单元,选中下个单元 新单元默认为command模式
- Ctrl-Enter 运行本单元
- Alt-Enter 运行本单元,在其下插入新单元 新单元默认为edit模式
- OO:重启当前kernal
- II:打断当前kernal的运行
- shift+上/下:向上/下选中多个代码块
- 上/下:向上/下选中代码块
- F:查找替换
3. Edit命令快捷键:
- Tab:代码补全
- ctrl]或Tab:缩进(向右)
- ctrl[或shift-Tab:反缩进(向左)
- ctrl A:全选
- ctrl D:删除整行
- ctrl Z:撤销
Jupyter Notebook里command模式快捷键H,查看所有快捷键
-
Jupyter Notebook路径输入方式
- 反斜杠:/
- 双斜杠:\\
- 使用短路径
- 不要使用粘贴路径, 手工录入完整路径
注意:如果是绝对路径的写法:D:\\download\\train.csv,千万别掉了D后面的":",切记。
- %matplotlib inline写法含义
使用%matplotlib命令可以将matplotlib的图表直接嵌入到Notebook之中,或者使用指定的界面库显示图表,它有一个参数指定matplotlib图表的显示方式。inline表示将图表嵌入到Notebook中。Python提供了许多魔法命令,使得在IPython环境中的操作更加得心应手。魔法命令都以%或者%%开头,以%开头的成为行命令,%%开头的称为单元命令。行命令只对命令所在的行有效,而单元命令则必须出现在单元的第一行,对整个单元的代码进行处理。博客
- 安装matplotlib命令
python -m pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
- 安装xgboost
pip install xgboost -i https://pypi.tuna.tsinghua.edu.cn/simple
- 安装lightgbm
pip install lightgbm
LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架(实现 GBDT 算法的框架,支持高效率的并行训练)。可用于排序,分类,回归以及很多其他的机器学习任务中。在竞赛题中,我们知道XGBoost算法非常热门,它是一种优秀的拉动框架,但是在使用过程中,其训练耗时很长,内存占用比较大。在2017年年1月微软在GitHub的上开源了一个新的升压工具--LightGBM。在不降低准确率的前提下,速度提升了10倍左右,占用内存下降了3倍左右。具体细节:参考博客。
- 安装catboost
pip install catboost -i https://pypi.tuna.tsinghua.edu.cn/simple
一个超级简单并且又极其实用的boosting算法包Catboost,据开发者所说这一boosting算法是超越Lightgbm和XGBoost的又一个神器。具体细节:参考博客。
- python的Tqdm模块
pip install tqdm
导入:from tqdm import tqdm
- 改变jupyter notebook的主题背景颜色
安装jupter notebook的自定义主题
pip install --upgrade jupyterthemes查看安装的这几个自定义主题的名称
jt -l选择一个主题名换皮肤
jt -t 主题名 -T -NTqdm 是一个快速,可扩展的Python进度条,可以在 python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)。参考博客1、参考博客2
- python的cv2(OpenCV,opencv-python)模块
pip3 install opencv-python
使用cv2.imwrite(image_path, image)保存图片到指定路径,千万注意路径中不能含有中文。
- pip安装seaborn
pip install seaborn
关于使用seaborn库对数据集进行关联分析,这个库讲的比较。
官网,也有参数介绍。
关于参数讲的比较好,博客Link
plt.figure(figsize=(10, 10))--->这句话必须放在上面一行
sns.heatmap(train_df.corr(), annot=True, fmt=".2f",linewidths='5')
- 解决打印不能显示dataframe的全部数据,中间的数据用省略号表示。
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows',None)#设置value的显示长度为100,默认为50
# pd.set_option('display.max_colwidth',10)
pd.set_option('display.max_rows',20)
- pandas统计属性个数
train_df['indoorAtmo'].value_counts().sort_values(ascending=False)
tensorflow2.0cpu版本的安装
我的python版本是3.7.7
第一步;安装tensorflow
pip install tensorflow-cpu == 2.2.0 -i https://pypi.douban.com/simple/
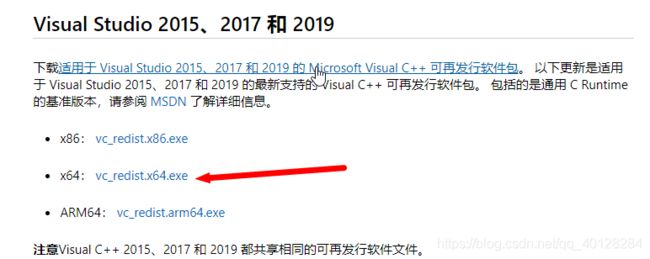
第二步:安装Visual C++ 可再发行软件包
地址:https://support.microsoft.com/zh-cn/help/2977003/the-latest-supported-visual-c-downloads
数据预处理:
当测试或实际应用需要设置空值缺失值时可以用None 、np.nan 、pd.NaT
处理空值异常值有两种办法,一种是将空值行/列删除,一种是将替代空值
- 如何对空值计数
a=df.isnull()
b=a[a==True]
b.count()#用来计算nan数量
- 删除的方法
将nan的行全部删除
df.dropna()
print(‘dropna’,df.dropna())#将带nan的行删除 axis=1删除列
- 填充
df.fillna(10) 自动按10填充
df.Age.fillna(df.Age.mean(),inplace = True) 用平均值来填充 print(‘ffill’,df.fillna(method=‘ffill’))#上面的值覆盖下面的值
print(‘dfill’,df.fillna(method=‘bfill’))#下面的值覆盖上面的值
print(‘replace’,df.replace({np.nan:‘aa’}))#对应的填充替换细节参考博客:https://blog.csdn.net/weixin_38168620/article/details/79596819
- reset_index()主要用于重置索引
博客
pandas.cut(df,20, duplicates='drop')方法
用来把一组数据分割成离散的区间。比如有一组年龄数据,可以使用pandas.cut将年龄数据分割成不同的年龄段并打上标签。作用在一个属性上,可以使一个连续属性分割成20分,并将每行数据都对应到这个区间上。
-
Numpy知识点补充:np.vstack()&np.hstack()
np.vstack:按垂直方向(行顺序)堆叠数组构成一个新的数组
np.hstack:按水平方向(列顺序)堆叠数组构成一个新的数组
- DataFrame多条件筛选
df[(df.c1==1) & (df.c2==1)],注意中间是&,而不是and,这就很奇怪。
- DataFrame去掉某一列
data_df = data_df.drop(['temperature'],axis=1)
- DataFrame添加一列’c‘
data['c'] = '0'
- DataFrame中查询含有空值的item
df[df.isnull().T.any()]
- DataFrame中合并2个dataframe
datas_df = pd.concat([haveTem_train_df,notTem_train_df],axis = 0)
- 如何条件遍历筛选numpy的ndarray数据
法一(注意np.where(x>4)]返回的是符合的元素的index):
import numpy as np
x=np.arange(1,10,1)
x=x[np.where(x>4)]
print(x)
法二:
import numpy as np
x=np.arange(1,10,1)
x=x[x>4]
print(x)
- 缺失值处理
这篇博客写的比较好。
- opencv显示图片
#显示该张图片
img = cv2.imread("D:/me.jpg")
cv2.imshow("mnist",img)
#一定要延时,否则不能正常显示
cv2.waitKey()
cv2.destroyAllWindows()- 看Tensorflow的版本
tf.__version__
- pd.read_csv()
pd.read_csv()方法中header参数,默认为0,标签为0(即第1行)的行为表头。若设置为-1,则无表头。
- 查看jupyter notebook保存的文件在哪
jupyter notebook --generate-config
- 查看DataFrame数据的信息:
df_info()
- 画出箱形图:
p=pd.DataFrame(train_df["indoorAtmo"]).boxplot(return_type='dict')
x=p['fliers'][0].get_xdata()
y=p['fliers'][0].get_ydata()
y.sort()
for i in range(len(x)):
if i>0:
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i]+0.05-0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i]+0.08,y[i]))
plt.show()
- pandas中在使用groupby()后
如何打印每一个分组中有多少数据:
pre_train_df.groupby(["month","day","hour"]).count()
打印索引:pre_train_df.groupby(["month","day","hour"]).count().index
打印每个索引对应的数据:pre_train_df.groupby(["month","day","hour"]).count().values
#按A列进行分组,得到分组后的(没有重复行)groupby对象
df_group= df.groupby("A")
#得到分组的总长度
lenth = len(df_group.count())
#得到分组后ID(行名称)对应的数量
id_name = df_group.size().values
#得到分组后的ID(行名称)
id_num = df_group.size().index
#迭代取key和value
for i, j in df_group:
print(i,j)
#根据组的key取值
df_group.get_group("xxxx")
#判断是否有某个分组key
"xxxx" in df_group.size().index进行groupby()后agg({'mean'})、apply()处理与transform('mean')处理的区别?
1. agg():
调用时要指定字段,apply默认传入整个Dataframe
2. apply():
参数可以是自定义函数,包括简单的求和函数以及复制的特征间的差值函数等。apply不能直接使用python的内置函数,比如sum、max、min。
2. transform():
参数不能是自定义的特征交互函数,因为transform是针对每一元素(即每一列特征操作)进行计算。使用transform要注意:
- 它只能对每一列进行计算,所以在groupby之后,transform之前是要指定操作的列,这点与apply有很大的不同
- 由于是对每一列进行计算,所以方法通用性性比apply就局限了很多,例如,只能求列的最大值,最小值,均值,方差,分箱等操作。
agg()与transform()的区别:
transform必须返回与组合相同长度的序列,而agg()返回的长度等于分组个数。
- 将DataFrame/Series转换成ndarray类型:
直接(DataFrame/Series).values
- reset_index()
reset_index()可以给DataFrame重新设置索引。
- pandas的DataFrame的append方法:
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
功能说明:向dataframe对象中添加新的行,如果添加的列名不在dataframe对象中,将会被当作新的列进行添加
other:DataFrame、series、dict、list这样的数据结构
ignore_index:默认值为False,如果为True则不使用index标签
verify_integrity :默认值为False,如果为True当创建相同的index时会抛出ValueError的异常
sort:boolean,默认是None,该属性在pandas的0.23.0的版本才存在。
- dataframe的merge操作
dataframe的merge是按照两个dataframe共有的column进行连接,两个dataframe必须具有同名的column。
具体细节参照:https://blog.csdn.net/sinat_35930259/article/details/79887021
- dataframe选择多列:
data_df[["dt","hour"]]
- 如何拿到DataFrame的索引:
df.index
- 合并2个ndarray
numpy.vstack()函数与numpy.hstack()函数
- Python函数中参数前带*是什么意思?
参数前面加上* 号 ,意味着参数的个数不止一个,另外带一个星号(*)参数的函数传入的参数存储为一个元组(tuple),带两个(*)号则是表示字典(dict),简单来说,将传过来的参数分别用元祖、字典存储起来了。
def t1(param1, *param2):
print(param1)
print(param2)
t1(1,2,3,4)
# 1
# (2,3,4)def t2(param1, **param2):
print param1
print param2
t2(1,a=2,b=3)
# 1
# {a:2, b:3}- python中变量e前面加星号,即*e:
列表或元组前面加星号作用是将列表解开成两个独立的参数,传入函数:
def add(x,y):
return x+y
b = [1,4]
e = (2,3)
add(*e)
add(*b)
>>> 5
>>> 5字典前面加两个星号,是将字典的值解开成独立的元素作为形参:
def add(x,y):
return x+y
d= {'a' : 2, 'b' : 3}
add(**data)
>>> 5- tf.control_dependencies的作用:
x_plus_1 = tf.assign_add(x, 1)
""
control_dependencies的意义是,在执行with包含的内容(在这里就是 y = x)前
先执行control_dependencies中的内容(在这里就是 x_plus_1)
""
with tf.control_dependencies([x_plus_1]):
y = x
- print(y.eval()):
相当于sess.run(y)
- tf.assign_add():
#返回一个op,表示给变量x加1的操作 x_plus_1 = tf.assign_add(x, 1)
- TensorFlow笔记—— tf.group(), tf.tuple 和 tf.identity()
博客:https://blog.csdn.net/liuweiyuxiang/article/details/79953259
- tf.assign()用法:
我们知道w.assign(10)等价于w = w+10,但是W.assign(100) 并不会给W赋值,assign()是一个op,所以它返回一个op object,需要在Session中run这个op object,才会赋值给W.
- Tensorflow保存模型、加载模型:
保存模型:
import tensorflow as tf
saver = tf.train.Saver()
with tf.Session() as sess:
#保存模型
saver.save(sess,"net/my_net.ckpt")会在当前目录/net下生成一些文件:

加载保存的模型:
import tensorflow as tf
saver = tf.train.Saver()
with tf.Session() as sess:
#保存模型
saver.restore(sess,"net/my_net.ckpt")
使用sess预测测试集-
安装requests包:
- pip install requests
- os.path.join用法:
os.path.join(inception_pretrain_model_dir,filename)---->拼接路径
- requests.get()方法:
res = requests.get(url,headers=headers) 向网站发起请求,并获取响应对象,具体细节,参考博客:https://www.cnblogs.com/LXP-Never/p/11361393.html
原始响应内容
在罕见的情况下,你可能想获取来自服务器的原始套接字响应,那么你可以访问 r.raw。 如果你确实想这么干,那请你确保在初始请求中设置了 stream=True。具体你可以这么做:
>>> r = requests.get('https://github.com/timeline.json', stream=True)
>>> r.raw
>>> r.raw.read(10)
'\x1f\x8b\x08\x00\x00\x00\x00\x00\x00\x03' 但一般情况下,你应该以下面的模式将文本流保存到文件:
with open(filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size):
fd.write(chunk)使用 Response.iter_content 将会处理大量你直接使用 Response.raw 不得不处理的。 当流下载时,上面是优先推荐的获取内容方式。
- tarfile.open().extractall()方法:
tarfile.open(filepath, ‘r:gz’).extractall(dest_directory),open返回一个tarfile对象,调用tarfile的extreactall方法将压缩文件解压到目标目录。
-
tf.gfile.FastGFile()
tf.gfile.FastGFile(path,decodestyle)
函数功能:实现对图片的读取。
函数参数:(1)path:图片所在路径 (2)decodestyle:图片的解码方式。(‘r’:UTF-8编码; ‘rb’:非UTF-8编码)
- plt.figure():
plt.figure(1)是新建一个名叫 Figure1的画图窗口,plt.plot(x,c)是在画图窗口里具体绘制横轴为x 纵轴为c的曲线
import matplotlib.pyplot as plt
plt.figure("image1")
plt.hist(range(1,10))
plt.show()
plt.figure("image2")
plt.hist(range(1,10))
plt.show()
- tf.Graph()函数
tf.Graph() 函数非常重要,主要体现在两个方面:
- 它可以通过tensorboard用图形化界面展示出来流程结构
- 它可以整合一段代码为一个整体存在于一个图中
参考博客:https://blog.csdn.net/qq_36653505/article/details/85255046
其实 Graph_def是Graph的序列化表示。
- 保存图结构
writer = tf.summaty.FileWriter(log_dir,sess.graph)
- 打开tensorboard
loception_log是一个目录。
tensorboard --logdir=D:\GoogleNet\loception_log
- with ... as 语句
博客:https://blog.csdn.net/lantian_123/article/details/101518240
- 数据预处理,Lag特征添加,滑动窗口的设计:
博客:https://www.jianshu.com/p/4ece90357020
- 时间序列模型中平稳分布:
链接:https://v.youku.com/v_show/id_XNDU2MTczMTQwMA==
- pandas统计特征
pds = pd.DataFrame([[1,2,3],[4,6,6],[7,8,9]])
pds
pds.mean(axis = 1)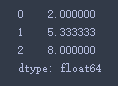
- statsmodels模块可以用于检测一个序列是否是平稳分布
pip install statsmodels
- 查看一个分布是否为平稳分布:
#开始导入adfuller函数
from statsmodels.tsa.stattools import adfuller
adfuller(train_df['temperature'].values,autolag="AIC")结果如下:

- 箱型图:
- matplotlib显示一张图片:
plt.imshow(train_image[1])

-
python3 print不换行
python3中print函数中的参数end默认值为'\n',表示换行,给end赋值为空,就不会换行了,例如:
print (123,end=" " )
print (456,end=" ")
- jupyter notebook中调用pip语句:
!pip *****
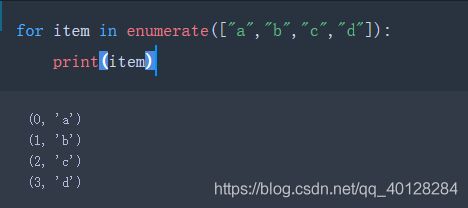
- enumerate(可迭代对象)的用法:
- IPython.display显示图片:
#导入库
import IPython.display as display
display.display(display.Image("图片路径", width=100, height=100))
- DataFrame类型的数据以csv格式的文件保存到磁盘上:
data.to_csv('E://data_for_tree.csv', index=0)
Pandas中的Series类型的数据可以调用plot直接绘画出来:
Train_data['power'].plot.hist()
- sklearn 中preprocessing模块:
导入:from sklearn import preprocessing
1)标准化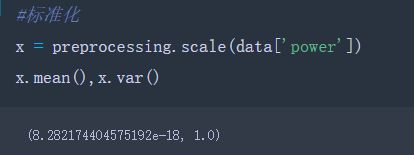
链接:https://www.cnblogs.com/lvdongjie/p/11349701.html
- lgb使用模板:
lgb参数介绍文档:https://lightgbm.apachecn.org/#/docs/6
""
trn_x、val_x、train_x:为我们切分好DataFrame类型的数据集,不含有Lable那一列
trn_y、val_y、train_y:我们对label进行分片得到的series
""
train_matrix = lgb.Dataset(trn_x, label=trn_y)
valid_matrix = lgb.Dataset(val_x, label=val_y)
data_matrix = lgb.Dataset(train_x, label=train_y)
params = {
#弱分类器使用gbdt
'boosting_type': 'gbdt',
#损失函数使用均方误差
'objective': 'mse',
#为了防止过拟合,该节点的信息增益如果小于该值就不在往下分裂
'min_child_weight': 5,
#为了防止过拟合,设定的没棵树叶子节点数目
'num_leaves': 2 ** 8,
""
feature_fraction 小于 1.0, LightGBM 将会在每次迭代中随机选择部分特征. 例如, 如果设置
为 0.8, 将会在每棵树训练之前选择 80% 的特征
""
'feature_fraction': 0.5,
#但是它将在不进行重采样的情况下随机选择部分数据
'bagging_fraction': 0.5,
#每几次迭代执行bagging
'bagging_freq': 1,
#学习率
'learning_rate': 0.001,
#种子,这个在比赛的时候可能会改
'seed': 2020
}
#训练5000次,1000次早停
model = lgb.train(params, train_matrix, 50000, valid_sets=[train_matrix, valid_matrix],
verbose_eval=500,
early_stopping_rounds=1000)
model2 = lgb.train(params, data_matrix, model.best_iteration)
#模型训练完成,开始预测label
val_pred = model.predict(val_x, num_iteration=model2.best_iteration).reshape(-1, 1)
test_pred = model.predict(test_x, num_iteration=model2.best_iteration).reshape(-1, 1)
- xgb使用模板:
#使用Xgboost自带的读取格式DMatrix(),并忽略np.nan数据
train_matrix = xgb.DMatrix(trn_x, label=trn_y, missing=np.nan)
valid_matrix = xgb.DMatrix(val_x, label=val_y, missing=np.nan)
test_matrix = xgb.DMatrix(test_x, missing=np.nan)
#mae 均方根误差
params = {'booster': 'gbtree',
'eval_metric': 'mae',
'min_child_weight': 5,
'max_depth': 8,
'subsample': 0.5,
'colsample_bytree': 0.5,
'eta': 0.001,
'seed': 2020,
'nthread': 36,
'silent': True,
}
watchlist = [(train_matrix, 'train'), (valid_matrix, 'eval')]
model = xgb.train(params, train_matrix, num_boost_round=50000, evals=watchlist,
verbose_eval=500,
early_stopping_rounds=1000)
val_pred = model.predict(valid_matrix, ntree_limit=model.best_ntree_limit).reshape(-1, 1)
test_pred = model.predict(test_matrix, ntree_limit=model.best_ntree_limit).reshape(-1, 1)
- cat使用模板:
params = {'learning_rate': 0.001,
'depth': 5,
'l2_leaf_reg': 10,
'bootstrap_type': 'Bernoulli',
'od_type': 'Iter',
'od_wait': 50,
'random_seed': 11,
'allow_writing_files': False}
model = cat(iterations=20000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),cat_features=[],use_best_model=True,verbose=500)
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
- SGDRegressor(随机梯度下降回归)使用模板:
params = {
'loss': 'squared_loss',
'penalty': 'l2',
'alpha': 0.00001,
'random_state': 2020,
}
model = SGDRegressor(**params)
model.fit(trn_x, trn_y)
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
- ridge(岭回归)使用模板:
params = {
'alpha': 1.0,
'random_state': 2020,
}
model = Ridge(**params)
model.fit(trn_x, trn_y)
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)