pyspider爬虫框架的基本使用
1.pyspider介绍
一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
- 功能强大的WebUI,包含脚本编辑器,任务监视器,项目管理器和结果查看器。
英文文档:http://docs.pyspider.org/
2.pyspider安装
建议在python3.6下安装,使用3.7的报错解决方法请往下看
pip install pyspider
安装pyspider后,打开cmd命令工具,执行命令来启动服务器
pyspider
或
pyspider all
现下图则启动服务成功,默认地址端口为127.0.0.1:5000
 如果出现报错,请参考我之前写的一篇博客https://blog.csdn.net/qq_43645530/article/details/104433340
如果出现报错,请参考我之前写的一篇博客https://blog.csdn.net/qq_43645530/article/details/104433340
输入地址127.0.0.1:5000,打开WebUI界面
 引用别的一个图片来进行简单的介绍
引用别的一个图片来进行简单的介绍
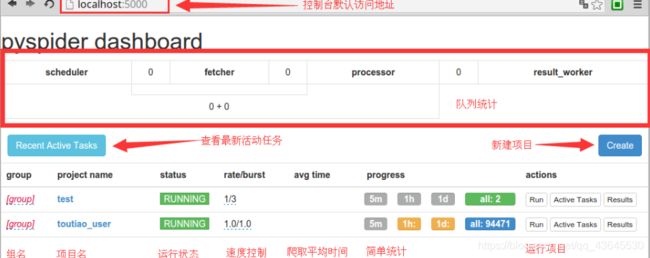
3.pyspider项目的创建

url可不填
 注意右侧,pyspider 已经帮我们生成了一段代码,代码如下所示:
注意右侧,pyspider 已经帮我们生成了一段代码,代码如下所示:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://travel.qunar.com/travelbook/list.htm', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),}
这里的 Handler 就是 pyspider 爬虫的主类,我们可以在此处定义爬取、解析、存储的逻辑。整个爬虫的功能只需要一个 Handler 即可完成。
接下来我们可以看到一个 crawl_config 属性。我们可以将本项目的所有爬取配置统一定义到这里,如定义 Headers、设置代理等,配置之后全局生效。
然后,on_start() 方法是爬取入口,初始的爬取请求会在这里产生,该方法通过调用 crawl() 方法即可新建一个爬取请求,第一个参数是爬取的 URL,这里自动替换成我们所定义的 URL。crawl() 方法还有一个参数 callback,它指定了这个页面爬取成功后用哪个方法进行解析,代码中指定为 index_page() 方法,即如果这个 URL 对应的页面爬取成功了,那 Response 将交给 index_page() 方法解析。
index_page() 方法恰好接收这个 Response 参数,Response 对接了 pyquery。我们直接调用 doc() 方法传入相应的 CSS 选择器,就可以像 pyquery 一样解析此页面,代码中默认是 a[href^=“http”],也就是说该方法解析了页面的所有链接,然后将链接遍历,再次调用了 crawl() 方法生成了新的爬取请求,同时再指定了 callback 为 detail_page,意思是说这些页面爬取成功了就调用 detail_page() 方法解析。这里,index_page() 实现了两个功能,一是将爬取的结果进行解析,二是生成新的爬取请求。
detail_page() 同样接收 Response 作为参数。detail_page() 抓取的就是详情页的信息,就不会生成新的请求,只对 Response 对象做解析,解析之后将结果以字典的形式返回。当然我们也可以进行后续处理,如将结果保存到数据库。
4.爬取https://travel.qunar.com/travelbook/list.htm
点击RUN。调用on_start()方法。生成新的请求(follows提示),点击follows,在点击小箭头。发起请求

如果报出关于证书的问题,在抓取函数中加入validate_cert=False就可以解决
这里同样的在self.crawl()最后加上validate_cert=False这个参数就完美解决了
可以点击web / html 预览页面和查看源代码
可以使用spider 提供的 CSS选择器来定位某个标签。来进行查找内容
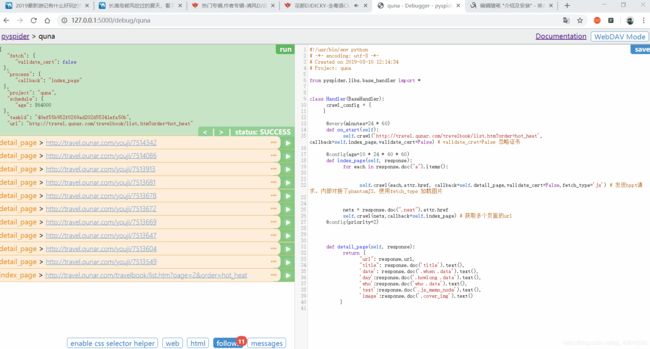 点击Save后。点击RUN,获取当前页面的所有URL(代码之前写好的。会出现不同现象)
点击Save后。点击RUN,获取当前页面的所有URL(代码之前写好的。会出现不同现象)
由于要获取多个页面的信息。所以在代码部分。需要添加,会看到最有最后一条是第二页的URL
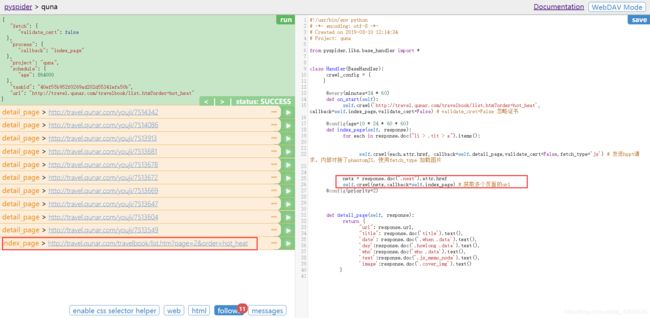 点击其中的某一条后的小箭头。点击RUN。返回详情页的信息
点击其中的某一条后的小箭头。点击RUN。返回详情页的信息
利用CSS选择器进行定位。在 detail_page 方法中进行获取详细信息
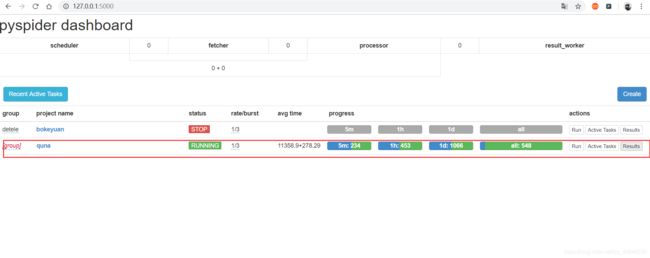
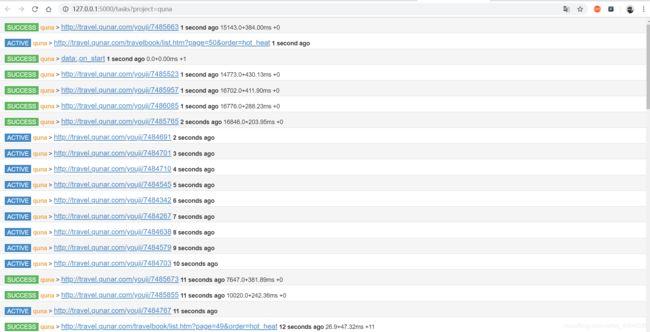
在项目首页中可以看到下面所展示
- group :定义分组。方便管理
- rate / burst :代表当前的爬取速率,rate代码一秒发出多少个请求,burst相当于流量控制中的令牌算法的令牌数量。rate / burst 越大。爬取速率越快。
- progress :5m / 1h / 1d 代表最近5分钟 / 1小时 / 一天内的请求情况。all 代表所有的请求情况,颜色不同代表不同的状态,蓝色代表等待被执行的请求,绿色代表成功的请求,黄色代表请求失败后等在重试的请求,红色代表失败次数过多而被忽略的请求
- run :执行
- Actice Tasks :查看最近请求的详细情况
- Result :查看爬取结果
 以上就是pyspider 的使用
以上就是pyspider 的使用