淘宝电商用户行为分析-python
淘宝电商用户行为分析-python
1.项目介绍
基于阿里云天池某数据集分析电商用户行为,从以下四个角度进行:
(数据集来源:https://tianchi.aliyun.com/dataset/dataDetail?dataId=649)
1)以PV、UV、平均浏览量、跳失率等指标,分析用户最活跃的日期及活跃时段,了解用户行为习惯
2)从成交量、人均购买次数、复购率等指标,探索用户对商品的购买偏好,了解商品的销售规律
3)从收藏转化率、购物车转化率、成交转化率,对用户行为从浏览到购买进行漏斗分析
4)参照rfm模型,对用户进行分类,找到高价值用户群
2.数据集概况
本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括pv、cart、fav、buy)。数据集的每一行表示一条用户行为,由user_id、item_id、category_id、behavior、timestamp组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 列 | 说明 |
|---|---|
| user_id | 整数类型,序列化后的用户ID |
| item_id | 整数类型,序列化后的商品ID |
| category_id | 整数类型,序列化后的商品所属类目ID |
| behavior | 整数类型,序列化后的商品ID |
| timestamps | 行为发生的时间戳 |
分析步骤
提出问题------理解数据------数据清洗------构建模型
(一)提出问题
1、用户最活跃在哪些日期及时段
2、用户对商品有哪些购买喜好,什么样的商品销售最多
3、用户行为间的转化情况
4、用户分类,哪些是有价值的用户
(二)理解数据
- 查看数据基本信息
import pandas as pd
user = pd.read_csv('/Users/cheng/Desktop/艾小丫的数据/阿里云/电商用户行为/UserBehavior.csv')
#原始数据没有列名,加上列名
user.columns = ['user_id', 'item_id', 'category_id', 'behavior', 'timestamps']
#查看数据信息
user.info()
RangeIndex: 3835330 entries, 0 to 3835329
Data columns (total 5 columns)
Column Dtype
0 user_id int64
1 item_id int64
2 category_id int64
3 behavior object
4 timestamps float64
dtypes: float64(1), int64(3), object(1)
memory usage: 146.3+ MB
(三)数据清洗
- 查看是否有缺失值并处理
#查看是否有缺失值
print(user.count())
#将时间戳这一列的数据缺失值进行填充
user['timestamps'] =user['timestamps'].fillna(user['timestamps'].median())
user_id 3835330
item_id 3835330
category_id 3835330
behavior 3835330
timestamps 3835329
dtype: int64
- 对时间戳列进行格式转换和异常值处理
#将时间戳格式转换为时间格式
user['time-stamps'] = pd.to_datetime(user['timestamps'] .apply(lambda x:time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(x))))
#添加日期、时间
user['date'] =user['time-stamps'].dt.date
user['time'] =user['time-stamps'].dt.time
user['hour'] =user['time-stamps'].dt.hour
user['weekdayname']=user['time-stamps'].dt.day_name()
print(user.head(20))
#查看日期是否有异常值
print(user['date'].value_counts())
#本数据集包含了2017年11月25日至2017年12月3日之间的数据,对其他日期的数据删除处理
user=user[(user['time-stamps']>='2017-11-25 00:00:00') & (user['time-stamps']<'2017-12-04 00:00:00')]
print(user['date'].value_counts())#查看处理结果
发现日期有异常值,进行处理
[20 rows x 10 columns]
2017-12-02 532774
2017-12-03 528928
2017-12-01 417977
2017-11-26 406793
2017-11-30 400366
2017-11-25 395033
2017-11-29 390885
2017-11-27 382304
2017-11-28 378326
2017-11-24 1507
2017-11-23 181
2017-11-22 53
2017-11-19 33
2017-11-21 25
2017-11-20 20
2017-11-18 19
2017-11-17 18
2018-08-28 16
2017-11-03 14
2017-11-16 10
2017-12-04 6
2017-11-14 6
2017-11-13 6
2017-11-11 5
2017-11-15 4
2017-12-06 3
2017-11-12 2
2017-07-03 2
2017-09-16 2
2017-11-10 2
2017-10-31 1
2017-11-02 1
2017-10-10 1
2015-02-06 1
2037-04-09 1
2017-11-04 1
2017-09-11 1
2017-11-05 1
1970-01-01 1
2017-11-06 1
Name: date, dtype: int64
(四)模型构建
1、用户购物情况分析
1、
这9天里PV(浏览量):3431905
这9天里UV(用户数),返回结果是:37376
#查看pv,浏览量
print(user['behavior'].value_counts())
#发现behavior列有一个拼写错误的值,将其修正
user['behavior']=user['behavior'].replace('p','pv')
print(user['behavior'].value_counts())
发现behavior列有一个拼写错误的值,将其修正
pv 3431904
cart 213634
fav 111140
buy 76707
p 1
Name: behavior, dtype: int64
#查看uv,此处将用户ID数量作为uv,访客量
uv=len(user['user_id'].unique())
print(uv)
平均浏览量是: 3431905/37376=91.8
即每个用户平均访问了92个页面。
2、
跳失率计算(跳失率:只有点击行为的用户/总用户数)
stay=['cart','fav','buy']
lostnum1=uv-len(user[user['behavior'].isin(stay)]['user_id'].unique())
print(lostnum1)
跳失率=2196/37376=0.0587,跳失率不高,说明店铺的商品详情页还是能吸引到用户的进行下一步行为
3、
每天浏览量情况、每天访客量情况
day_pv=user[user['behavior']=='pv']['behavior'].groupby(user['date']).value_counts()
#对不同日期的用户ID去重处理
user1=user.drop_duplicates(['user_id','date'])
day_uv=user1['user_id'].groupby(user['date']).count()
print(day_pv)
print(day_uv)
#作图
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10, 5))#调整画布大小
plt.tick_params(labelsize=10)#调整标签字体大小
sns.countplot(x='date',data=user[user['behavior']=='pv'],color='lightblue')
plt.show()
plt.figure(figsize=(10, 5))
plt.tick_params(labelsize=10)#调整标签字体大小
sns.countplot(x='date',data=user1,color='lightblue')
plt.show()
每天浏览量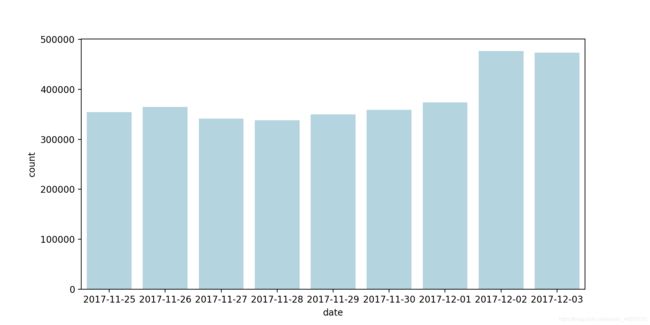
每天访客量

可以看出,浏览量和访客量的高峰都主要集中于周末的俩天,而浏览量在起始的俩天也略高于其他日期。
4、
每个时段浏览量、访客数
hour_pv=user[user['behavior']=='pv']['behavior'].groupby(user['hour']).value_counts()
print(hour_pv)
#作图
plt.figure(figsize=(10, 5))#调整画布大小
plt.tick_params(labelsize=10)#调整标签字体大小
ax1 = sns.countplot(x='hour',data=user[user['behavior']=='pv'],color="lightblue",label ='hour_pv')
plt.legend(loc='center',bbox_to_anchor=(1.15,0.95))
ax2 = ax1.twinx()
sns.countplot(x='hour',data=user1,facecolor=(0, 0, 0, 0),linewidth=0.5,edgecolor='darkblue',
ax=ax2,label ='hour_uv')
plt.legend(loc='center',bbox_to_anchor=(1.15,0.86))
plt.show()
每小时浏览量、访客量

可以看出:
1)访客数与浏览量在1-6时(大多数人处于睡眠休息阶段时)都较低
2)浏览量19 - 22时达到高峰,猜测是下班后,用户浏览时间长,浏览购物网站放松
3)访客量高峰出现在7-13时和0-1时,但该阶段浏览量不高,或许是用户上班休息时间打开了淘宝店铺,但没时间大量浏览和购买商品
5、
不同时段成交量
user[user['behavior']=='buy']['behavior'].groupby(user['hour']).count()
plt.figure(figsize=(10, 5))#调整画布大小
plt.tick_params(labelsize=10)#调整标签字体大小
sns.countplot(x='hour',data=user[user['behavior']=='buy'],color="lightblue")
plt.show()

可以看出,成交量在10-16时、20-22时较高,基本上于浏览量高峰和访客量高峰契合。
2、商品购买情况分析
1、
不同日期成交量
user[user['behavior']=='buy']['behavior'].groupby(user['date']).count()
plt.figure(figsize=(10, 5))#调整画布大小
plt.tick_params(labelsize=10)#调整标签字体大小
sns.countplot(x='date',data=user[user['behavior']=='buy'],color="lightblue",order =
['2017-11-25','2017-11-26','2017-11-27','2017-11-28','2017-11-29','2017-11-30',
'2017-12-01','2017-12-02','2017-12-03'])
plt.show()

可以看出,2017年12月2日和2017年12月3日成交量较高,刚好是周六和周日。猜测是由于活动影响或者周末人们空闲时间较多,网购下单量更高。
2、
人均购买次数=购买的用户数/购买单数=3.0200
#人均购买次数=购买单数/用户数
avg_buy=len(user[user['behavior']=='buy'])/len(user[user['behavior']=='buy']['user_id'].unique())
print(avg_buy)
3、
复购率=购买2次及以上用户数/总购买用户数=16712/25400=0.6579
#购买2次以上用户数
a = user[user['behavior']=='buy'].groupby('user_id').count()>1
rebuy = a[a['behavior'] == True].index
print(len(rebuy))
#复购率
repurchase_rate=len(rebuy)/len(user[user['behavior']=='buy']['user_id'].unique())
print(repurchase_rate)
可以看出,用户人均购买3次,复购率达到65.79%,店铺用户整体忠诚度尚可。
4、
重复被购买得最多次的商品、重复购买次数最多的用户
#重复被购买得最多次的商品
top_item=user[user['behavior']=='buy']['item_id'].value_counts().head(10)
print(top_item)
#重复购买次数最多的客户
top_user=user[user['behavior']=='buy']['user_id'].value_counts().head(10)
print(top_user)
重复被购买得最多次的商品top 10
3122135 58
3031354 32
2964774 27
2560262 26
1910706 25
1116492 23
257772 23
1042152 23
3964583 22
3189426 22
Name: item_id, dtype: int64
重复购买次数最多的用户top 10
234304 84
107932 72
122504 69
128379 65
242650 61
190873 61
1008380 57
165222 51
140047 47
1003983 43
Name: user_id, dtype: int64
可以看出,item_id=3122135的商品购买次数达到58次,可对top商品进行规律探寻,打造更多明星商品;
对购买次数多的用户应该参照rfm模型的建模结果进行用户价值分层,建立用户资料库。
3、用户行为转化漏斗分析
1、
按总量计算的漏斗模型
sns.countplot(y='behavior',data=user,color="lightblue",order=['pv','cart','fav','buy'])
plt.show()
未去重的行为数量
pv 3431905
cart 213634
fav 111140
buy 76707
Name: behavior, dtype: int64
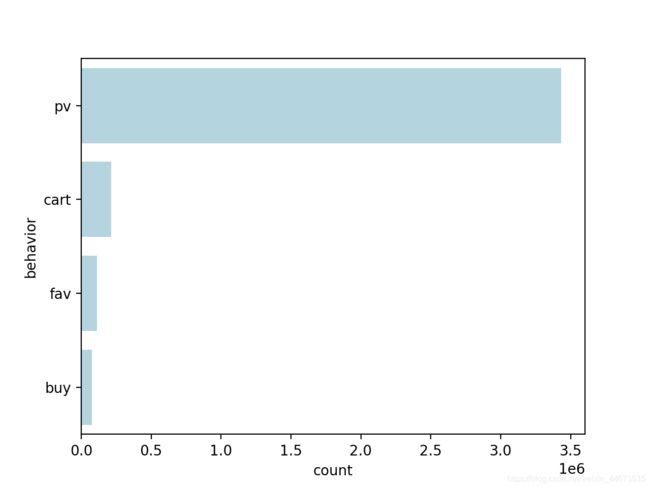
可以看出,每个流程的使用量都在减少。真正转化为购买的只有76707/3431905=2.2%,用户在浏览商品详情页后出现了大量的流失。
2、
查看每个行为用户数
user2=user.drop_duplicates(['user_id','behavior'])#对不同行为的用户ID去重处理
print(user2['behavior'].value_counts())
对user_id、behavior去重后的行为数量
pv 37223
cart 28122
buy 25400
fav 14943
Name: behavior, dtype: int64从浏览
浏览-购买
购买总用户数为25400,而先浏览后购买的总用户数=17817<25400,说明有可能在统计时段前浏览,再进行加购或收藏、购买等操作。
浏览-购买
# 查看是否有只购买未浏览的用户
user_pv_buy=pd.merge(user[user['behavior']=='pv'],user[user['behavior']=='buy'],on=['user_id','item_id','category_id'])#同一用户同一商品既浏览又购买数据
user_pv_buy1=user_pv_buy[user_pv_buy['timestamps_x']<user_pv_buy['timestamps_y']]#同一用户先浏览后加购的用户数
pv_buy=len(user_pv_buy['user_id'].unique())#浏览并且购买的用户
pv_first_buy=len(user_pv_buy1['user_id'].unique())#先浏览后购买的用户
print(pv_buy)#=21069
print(pv_first_buy)#=17817
从浏览到购买,每一个环节的转化率
因为加入购物车和收藏商品并没有行为的先后性,也就是说,购物路线可以有俩条:
第一条线路:浏览—加入购物车—购买
第二条线路:浏览—添加收藏—购买
按照线路一来购买
从浏览到加入购物车到购买之间的转化率:
#线路1--浏览-加购-购买;
user_cart_buy1=user[user['behavior']=='cart'] #加购数据
user_cart_buy2=user[user['behavior']=='buy'] #购买数据
user_cart_buy=pd.merge(user_cart_buy1,user_cart_buy2,on=['user_id','item_id','category_id'])#同一用户同一商品既加购又购买数据
user_cart_buy.info()
print(user_cart_buy.head())
cart_buy=len(user_cart_buy['user_id'].unique())#加购并且购买的用户数
print(cart_buy)#=8812
user_cart_buy3=user_cart_buy[user_cart_buy['timestamps_x']<user_cart_buy['timestamps_y']]#同一用户先加购后购买
cart_first=len(user_cart_buy3['user_id'].unique())#同一用户先加购后购买的用户数
print(cart_first)#=8503
user_pv_cart=pd.merge(user[user['behavior']=='pv'],user[user['behavior']=='cart'],on=['user_id','item_id','category_id'])#同一用户同一商品既浏览又加购数据
user_pv_cart1=user_pv_cart[user_pv_cart['timestamps_x']<user_pv_cart['timestamps_y']]#同一用户先浏览后加购的用户数
pv_cart=len(user_pv_cart['user_id'].unique())#浏览并且加购的用户
pv_first_cart=len(user_pv_cart1['user_id'].unique())#先浏览后加购的用户
print(pv_cart)#=23366
print(pv_first_cart)#=15311
去重后的新行为数量
pv 37223
cart 28122
buy 25400
fav 14943
Name: behavior, dtype: int64
购物车转化率=加入购物车后购买的用户数/加入购物车的用户数=8503/28122=30.2%,约为30%,加入购物车的用户中,有30%会进行购买。
用户浏览到加入购物车的转化率=浏览后加入购物车的用户数/用户浏览数=15311/37223=41.13%
按照线路二来购买
从浏览到收藏到购买之间的转化率:
#2、线路2:浏览-收藏-购买
user_pv_fav=pd.merge(user[user['behavior']=='pv'],user[user['behavior']=='fav'],on=['user_id','item_id','category_id'])#同一用户同一商品既浏览又收藏数据
user_pv_fav1=user_pv_fav[user_pv_fav['timestamps_x']<user_pv_fav['timestamps_y']]#同一用户先浏览后收藏的用户数
pv_fav=len(user_pv_fav['user_id'].unique())#浏览并且收藏的用户
pv_first_fav=len(user_pv_fav1['user_id'].unique())#先浏览后收藏的用户
print(pv_fav)#=11139
print(pv_first_fav)#=6857
user_fav_buy=pd.merge(user[user['behavior']=='fav'],user[user['behavior']=='buy'],on=['user_id','item_id','category_id'])#同一用户同一商品既收藏又购买数据
user_fav_buy1=user_fav_buy[user_fav_buy['timestamps_x']<user_fav_buy['timestamps_y']]#同一用户先收藏后购买的用户数
fav_buy=len(user_fav_buy['user_id'].unique())#收藏并且购买的用户
fav_first_buy=len(user_fav_buy1['user_id'].unique())#先收藏后购买的用户
print(fav_buy)#=3404
print(fav_first_buy)#=3233
收藏转化率=添加收藏后购买的用户数/添加收藏的用户数=3233/14943=21.64%
用户浏览到收藏的转化率=浏览后收藏的用户数/用户浏览数=6875/37223=18.42%
综述
1、浏览用户(37223)的41%(15311)转换成了加购用户(28122),加购用户的30%(8503)转换成了购买用户(25400)
浏览用户(37223)的18%(6857)转换成了收藏用户(14943),收藏用户的21%(3233)转换成了购买用户(25400)
用户在浏览后,相对于收藏行为(18%),会更倾向于添加到购物车(41%)。
而且购物车转化率为30%,收藏转化率为21%,购物车转化率比收藏转化率高,也就是说,用户更偏向于购物车购买。
推测原因:加入购物车后可以直接下单购买,而加入收藏后并没有可以下单的页面,如果需要购买必须重新点击商品进入详情页才能下单,多了一个步骤,所以,在这个步骤里可能用户就流失了部分。
2、非加购、收藏后购买的购买用户可能来源于直接购买、统计时段前加购或收藏等
3、未转换成加购、收藏用户的浏览用户可能不买了或不加购收藏直接购买
4、有一些加购、收藏用户之前未有浏览行为,浏览行为可能发生在统计时段之前或由于淘宝的浏览机制定义,不计入浏览也可进行加购收藏
4、参照RFM模型,对用户进行分类找出有价值的用户
RFM模型是衡量客户价值和客户创利能力的重要工具。该模型通过客户的最近交易行为(Recency)、交易频率(Frequency)以及交易金额(Monetary)三项指标来描述该客户的价值状况。一般来说,会将这三项指标分成几个区间进行评分,通过计算评分找到有价值的用户,并对用户进行分类。
最近一次消费(Recency):是指最近一次消费距离上一次消费之间的时间长短。它反映了客户对产品的态度以及对品牌价值的信任度,它关乎消费者的存留状况。
消费频率(Frequency):是指某个特定时间内消费的次数。它直接反映了客户的忠诚度,消费频率越高,忠诚度就越高;忠诚度越高的客户数量越多,公司的竞争优势越强,市场份额越大。
消费金额(Monetary):是指一定时间内消费某产品金额。它反映的是客户的价值,价值越高,给公司创造的利益就更大。
因为数据源里没有金额相关的信息,所以只通过R和F来对客户价值进行评分。
R(Recency)最近的购买行为:
数据集里时间范围是从11月25到12月3日,我将11月25日,设为参数对照日期,即以距离11月25日的天数划分区间,其中0-2天,3-4天,5-6天,7-8天,分别对应为1-4分。
user3=user[user['behavior']=='buy']#购买数据
print(user3.head())
user3['purchasedays']=np.floor((user3['timestamps']-1511539200)/(60*60*24))#购买日期距离2017年11月25日的天数
print(user3.head())
对购买天数打分:
#购买天数与R评分的对应关系函数
def R(n):
if n in [0,1,2]:
return 1
elif n in [3,4]:
return 2
elif n in[5,6]:
return 3
else:
return 4
user3['R']=user3['purchasedays'].map(lambda x: R(x))
print(user3.head(20))#查看前20条数据以检验
不同R评分的用户数统计:
df=user3.drop_duplicates(['user_id'])
print(df['R'].value_counts())
1 12369
2 5240
3 4094
4 3697
Name: R, dtype: int64
F(Frequency)购买频率:
从上面对复购用户的分析中,我们得知购买频率最高的能达到84次。所以,我们将1-84从低到高,划分为4个档次。1-21,22-42,43-63,64-84分别对应为1-4分。
#购买次数与F评分的对应关系函数
def F(n):
if 1<=n<=21:
return 1
elif 22<=n<=42:
return 2
elif 43<=n<=63:
return 3
else:
return 4
rebuydata=pd.DataFrame(user3['user_id'].value_counts())#用户购买次数分类计数并划为dataframe结构
print(rebuydata)
rebuydata.columns=['num_rebuy']#更改列名
rebuydata['user_id'] = rebuydata.index #重建用户ID列
print(rebuydata)
user3=pd.merge(rebuydata,user3,on='user_id')
user3['F']=user3['num_rebuy'].map(lambda x: F(x))
print(user3.head())
df=user3.drop_duplicates(['user_id'])
print(df['F'].value_counts())
通过上面两个步骤,从两个维度:最近购买时间及购买频率,分别给用户进行了评分。接下来用这两项的每一项平均值作为判断高于还是低于,比如重要价值用户,必须是两项的分值都比平均值要高,才能作为重要价值的用户。
下面对用户进行分类
R高F高:重要价值用户(最近购买且购买频率高)
R高F低:重要保持用户(最近购买且购买频率低)
R低F高:重要发展用户(很久没买了购买频率高)
R低F低:一般价值用户(很久没买了购买频率低)
#查看R和F的均值,并以其为基准进行价值划分
r=user3['R'].mean()
f=user3['F'].mean()
print(r)
print(f)
user3['user_class']=np.select([(user3['R']>r) & (user3['F']>f),(user3['R']>r) & (user3['F']<=f),
(user3['R']<r) & (user3['F']>f), (user3['R']<r) & (user3['F']<=f)],
['重要价值用户','重要保持用户','重要发展用户','一般价值用户'])
print(user3.head())
df=user3.drop_duplicates(['user_id'])
print(df['user_class'].value_counts())
一般价值用户 17542
重要保持用户 7790
重要发展用户 67
重要价值用户 1
Name: user_class, dtype: int64
可以看出,重要价值用户(1),他们是最优质的用户,需要重点关注并保持, 应该提高满意度,增加留存;
对于重要保持用户(7790),他们最近有购买,但购买频率不高,可以通过活动等提高其购买频率;
对于重要发展用户(67),他们虽然最近没有购买,但以往购买频率高,可以做优惠券或活动触达,以防止流失;
对于一般价值用户,他们最近没有购买,以往购买频率也不高,特别容易流失,所以应该赠送优惠券或推送活动信息,唤醒购买意愿。
总结:
1.12月2日与12月3日,相对于其他日期,流量增长明显,推测是活动影响或与周末有关。
2.访客数与浏览量在1-6时都较低,19 - 22时达到浏览量高峰,猜测是下班后浏览购物网站放松。访客量高峰出现在7-13时和0-1时,但该阶段浏览量不高。20到22时,是一天当中成交量最高的时段。
3.这段时间,人均购买次数为3,复购率达到66%,说明店铺产品对用户吸引力比较大,用户忠诚度尚可。
4.被重复购买得比较频繁的商品是item_id为3122135等商品。
5.用户ID为234304 等的用户是重复购买次数最多的用户。建议对于这些忠实用户,建议组建VIP客户群等,结合用户价值分群,针对这些用户的购买偏好推送更精准的销售方案。
6.用户行为购买转化率只有2%,有98%的用户行为是没有转化为成交的,用户在浏览商品详情页后出现了大量的流失。
7.从浏览到加入购物车的转化有41%,加入购物车到真正购买的只有30%,有70%的用户加入购物车后却并没有进一步购买。建议在用户加入购物车后能有促进用户下单的利益“诱导”,如赠送优惠券或采用倒计时购物车增加客户购买紧近感。
8.从收藏到购买的转化率为21%。相对于购物车30%的转化率,收藏转化率稍低。同样建议在用户添加收藏后能提示优惠或促销等时限信息,促使用户尽早下单。
9.参照RFM模型对用户进行分类后,可知重要价值用户比较少,用户类型主要还是集中于重要保持用户和一般价值用户。