数据库查询优化之索引的使用详解
背景
当我们使用select * from table where propertyName = ‘?’时的时候(主键除外),在数据比较少的情况下,还是可以很快的运行完成,但在万级以上的时就会发现,运行速度慢了很多很多。那么怎么解决这问题呢?其实方法有很多,我们这主要讲用索引,关于为什么用索引可以提升速度,到时具体写一篇关于索引的工作原理的。
测试
以下都用mysql上进行测试
我们先创建一个学生表:
CREATE TABLE `student_table` (
`idstudent` int(11) NOT NULL AUTO_INCREMENT,
`student_name` varchar(45) NOT NULL,
`student_sex` varchar(45) NOT NULL,
`student_age` int(11) NOT NULL,
PRIMARY KEY (`idstudent`)
)现在加入大量数据
(使用存储过程的方法,比较粗糙)
注:这种插入方法很慢,建议每次批量添加1000个,一次批量100000个很可能电脑就死机了
(关于如何加速插入速度网上也有很多方法,主要是修改mysql.ini配置,及用事务的方法,这里先不把重点放在优化插入)
创建存储过程:
在创建之前最好调用:
use 数据库名;delimiter $$ #自定义终结符
create procedure loop_add_data() #存储过程函数名
begin #存储过程开启
declare i int;
set i = 1;
repeat #循环
insert into student_table(student_name,student_sex,student_age) values("ke",'男',i);
set i=i+1;
until i>=1000 #直至i>=1000循环结束
end repeat;
end $$ #存储过程结束调用存储过程:
call loop_add_data(); #调用存储过程如果在调用存储过程这步报错的话,使用以下方法:
use 数据库名;
call loop_add_datask();连续调用几次后直至有了万以上的数据。(为了看到效果,数据弄大多点)
并且插入一个特殊的:
insert into student_table(student_name,student_sex,student_age) values('kek','男',4);现在在没有使用索引的情况下搜素
先看总的数据数:
select count(*) FROM student_table;
总共有20万多的数据
SELECT * FROM test.student_table where student_name='kek' ;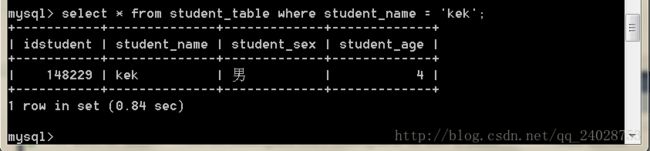
在没有索引的情况下用了 0.84秒
现在创建个普通索引:
create index student_table_name_index on student_table(student_name);再次运行:
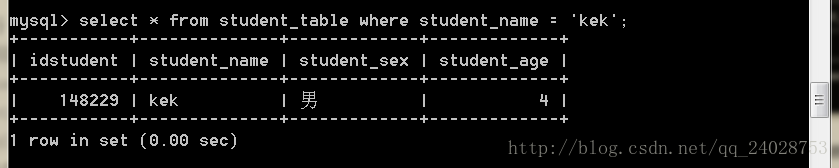
只用了0.00秒(这里只显示了小数点后两位,但说明查询所用的时间很短)
可知加了索引查询速度有大幅度的提升
创建索引
目前我们只是对表的student_name属性创建了索引,但当查询条件不是student_name的时候这时并不能提升查询的速度。
先插入一个别的字段的特殊数据:
insert into student_table(student_name,student_sex,student_age) values('liu','女',4);再进行查询操作:
SELECT * FROM test.student_table where student_sex='女';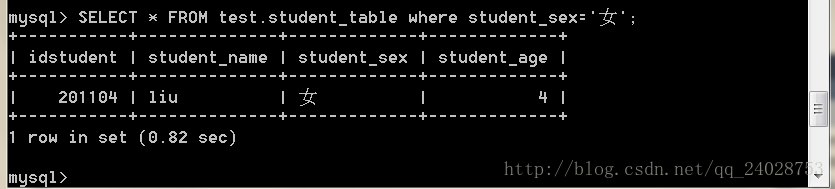
速度为0.84与上面没有用索引的速度类似,说明此处并没有用到索引查询。
前面用的只是普通索引方式
创建索引的方法
1. 创建索引,例如 create index <索引的名字> on table_name (列的列表);
2. 修改表,例如 alter table table_name add index[索引的名字] (列的列表);
3. 创建表的时候指定索引,例如create table table_name ( […], INDEX [索引的名字] (列的列表) );
查看表中索引的方法:
show index from table_name; 查看索引
修改表中的索引:
alter table tablename drop primary key,add primary key(fileda,filedb)
删除索引
drop index 索引名 on 索引所在的表名;
索引名->命名规范:表名+对应的字段名+index
#如有个表名为student(name ,age )
#创建针对name的索引名 student_name_index
#创建针对name,age的索引名 student_name_age_index索引的类别:
主键索引
它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引。
直接用主键进行查询:
SELECT * FROM test.student_table where idstudent=4;
查询速度为0.09与之前的0.07差不多,说明实际上设了主键的,会自带有主键索引,但主键是一种特殊的索引。
普通索引
这是最基本的索引,它没有任何限制。创建方式:
create index student_table_name_index on student_table(student_name);
#通用方法:create index 索引名 on 表名(表的属性名) 表示针对哪个字段进行普通索引唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。创建方式:
create unique index student_table_age_index on student_table(student_age);先看在没有创建唯一索引的情况下查询:
SELECT * FROM test.student_table where student_age=2;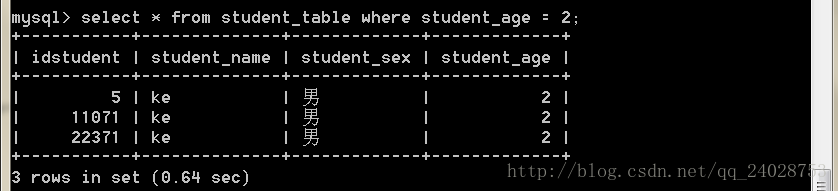
现在针对student_age建立了唯一索引:

唯一索引创建失败,原因是有重复值 可知:唯一索引只有在列值没有重复的情况下创建,那么可推唯一索引跟主键索引类似,但主键索引无需写索引创建语句
复合索引
联合索引又叫复合索引。对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c)。 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
两个或更多个列上的索引被称作复合索引。
利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引 不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知 道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
创建方式:
create index student_table_name_and_age_index on student_table(student_name,student_age);先删除之前的student_name的索引
drop index student_table_name_index on student_table;创建复合索引:name与age的复合索引
create index student_table_name_and_age_index on student_table(student_name,student_age);查询name:
SELECT * FROM test.student_table where student_name='kek';
查询name and age:
SELECT * FROM test.student_table where student_name='ke' and student_age=2;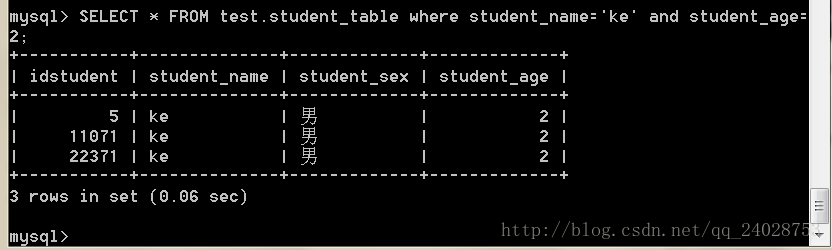
查询 age:
SELECT * FROM test.student_table where student_age=2;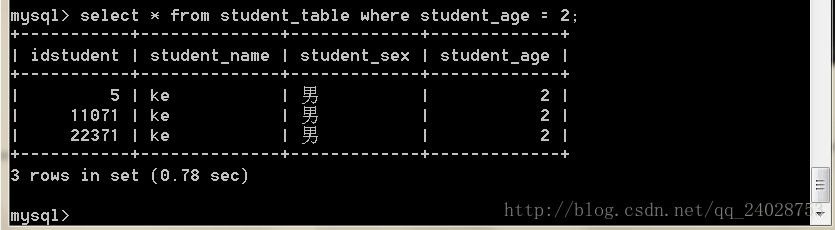
查询速度为0.78
可知当查询最右的age时并没有用到索引
综上可得: MySQL复合索引为“最左前缀”的结果,简单的理解就是只从最左面的开始组合。
感谢评论区@咀嚼- 提供的观点:加上一条:组合索引 index_b(列1,列2),如果列1没有在where查询条件中被使用,索引失效。
再次测试(便于测试创建三个字段的复合索引):
建立针对顺序为name,sex,age的复合索引
create index student_table_name_sex_age_index on student_table(student_name,student_sex,student_age);插入一个特殊列:
insert into student_table(student_name,student_sex,student_age) values("liu",'无',1);搜索sex
SELECT * FROM test.student_table where student_sex='无';
运行时间为0.30秒,与使用索引的情况下0.00秒(只保留两位小数)相差很多,可知这种情况没有用到索引。
搜索 age
SELECT * FROM test.student_table where student_age=1;
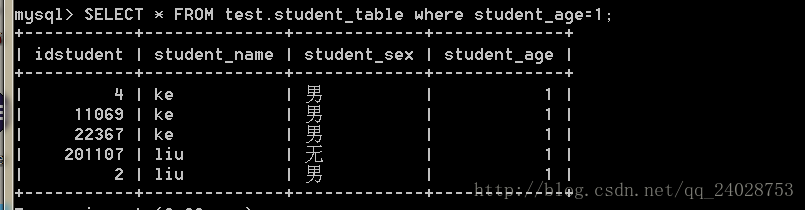
用时0.09秒,看似很快,比以上没有索引快一点主要原因跟他的字段类型有关,现在我们建立一个普通age的索引,再进行搜索
create index student_table_age_index on student_table(student_age);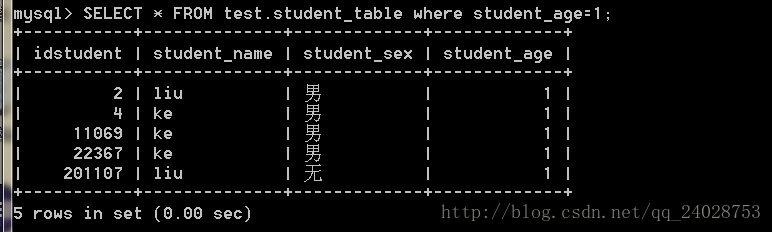
用时0.00秒,可知之前的的搜索age并没有用到索引。
现在先删除age的普通索引
drop index student_table_age_index on student_table;搜索sex,age:
SELECT * FROM test.student_table where student_sex='无' and student_age = 1;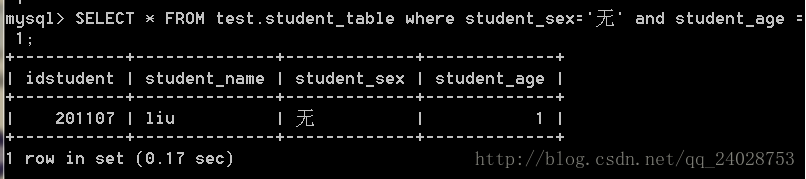
用时0.17与在索引的情况下0.00比,可知也没用到索引
搜索name , sex
SELECT * FROM test.student_table where student_name='liu' and student_sex='无';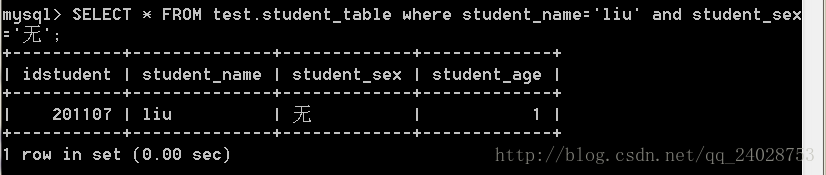
用时0.00秒,对比可知用到索引
搜索name,age
SELECT * FROM test.student_table where student_name='liu' and student_age=1;
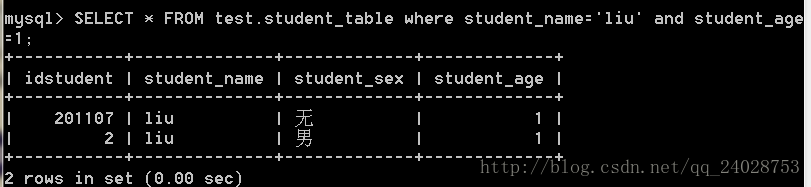
用时0.00秒,可知用到索引
搜索name,sex,age
SELECT * FROM test.student_table where student_name='liu' and student_sex='无' and student_age=1;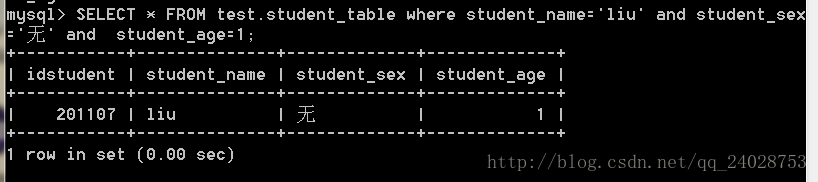
可知用到了索引。
现在再次证明,含有第一列有关索引where 的顺序问题:
直接上图了:
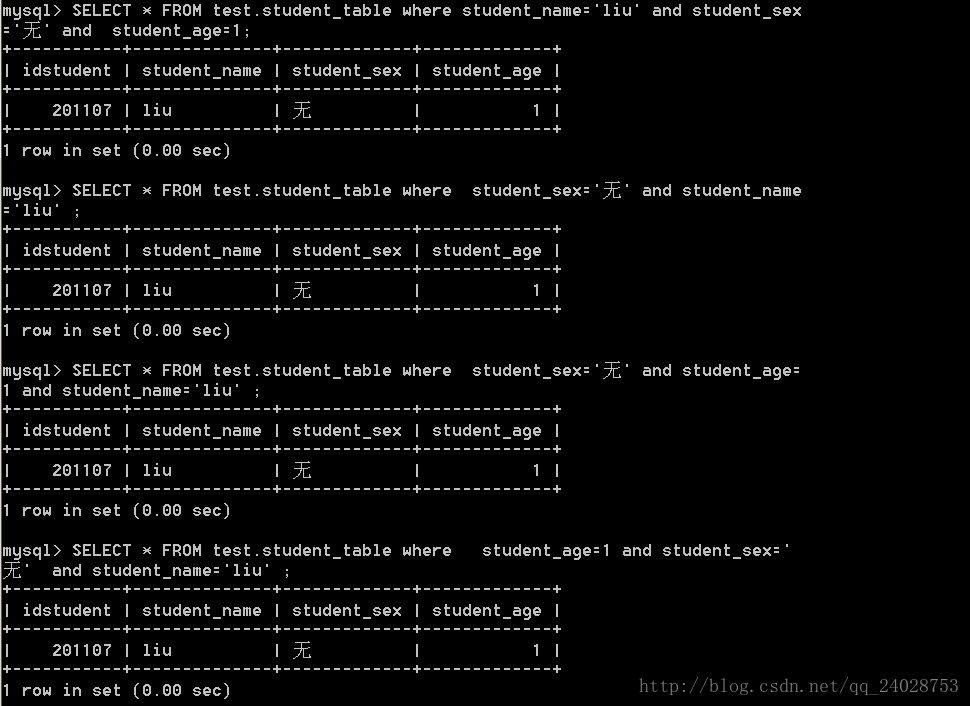
可知不管索引的where顺序,只要where中有列1,就会用到索引,这里提示只是说明会不会用到索引,但where的顺序还是会影响到索引的查询速度,最好是把列一放where首位。
从上可推,如果列1没有在where查询条件中被使用,索引失效。
再次感谢评论区@咀嚼- 提供的观点
全文索引
这是目前搜索引擎使用的一种关键技术,它能够利用「分词技术「等多种算法智能分析出文本文字中关键字词的频率及重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。
众所周知,在数据库中进行模糊查询是使用LIKE关键字进行查询,例如:
SELECT * FROM article WHERE content LIKE ‘%查询字符串%’但它在数据大的情况下查询速度十分缓慢,全文索引就是为解决这个问题而出发的,关于全文索引到时独立写一篇详解。
索引优缺点
优点
这是因为,创建索引可以大大提高系统的性能。
第一、通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二、可以大大加快 数据的检索速度,这也是创建索引的最主要的原因。
第三、可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四、在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五、通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点
第一、创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二、索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间。如果要建立聚簇索引,那么需要的空间就会更大。
第三、当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
测试
创建一个索引时的耗时:
create index student_table_name_index on student_table(student_name);
创建一个普通索引就用了4秒的时间,可知的确是十分耗时的操作
在有创建索引的情况下插入数据:
insert into student_table(student_name,student_sex,student_age) values('kek','男',4);

删除索引后插入:

综上可知: 在没有索引的情况下插入速度更快,原因主要是在有索引的时候插入也要改变索引表的结构。
(那么根据这两点,就可以推出,并不是索引建得越多越好,索引越多插入速度越慢,所以第一点索引不要建很多个,第二点在查询比较多的地方,插入,删除,修改比较少的地方,用索引是很好的选择)
索引创建场景
什么样的字段适合创建索引:
索引是建立在数据库表中的某些列的上面。因此,在创建索引的时候,应该仔细考虑在哪些列上可以创建索引,在哪些列上不能创建索引。
一般来说,应该在这些列上创建索引,例如:
第一、在经常需要搜索的列上,可以加快搜索的速度;
第二、在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
第三、在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
第四、在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
第五、在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
第六、在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
什么样的字段不适合创建索引:
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比 例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四,当修改性能远远大于检索性能时,不应该创建索 引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
参考文献 : http://blog.csdn.net/superit401/article/details/51291603