hadoop组件---面向列的开源数据库(十)--使用phoenix自带工具执行sql脚本以及批量导入数据到hbase中
我们在之前的文章中,记录了 在phoenix命令行工具中运行命令,使用java连接phoenix,使用图形界面化客户端连接phoenix。
hadoop组件—面向列的开源数据库(七)–phoenix查询hbase–映射和常用命令
hadoop组件—面向列的开源数据库(八)–java使用phoenix查询hbase
hadoop组件—面向列的开源数据库(九)–使用phoenix图形界面客户端查询hbase
这三种方式都可以对hbase的数据进行增删改查。
本章记录 使用phoenix自带的其他工具,进行复杂的脚本运行以及 导入数据。
Phoenix使用自带工具psql执行sql脚本
当我们有比较复杂的sql操作时,可以使用sql脚本运行。这样就不需要一条条命令进行粘贴运行了。
在任一目录创建sql脚本如下:
vi /data6/user.sql
输入内容如下:
-- create table user
create table if not exists user (id varchar primary key,account varchar ,passwd varchar);
-- insert data
upsert into user(id, account, passwd) values('001', 'admin', 'admin');
upsert into user(id, account, passwd) values('002', 'test', 'test');
upsert into user(id, account, passwd) values('003', 'zzq', 'zzq');
-- query data
select * from user;
并且给sql脚本相应的权限,让phoenix的psql工具能访问到,使用命令
chmod 777 /data6/user.sql
进入到phoenix的安装目录,比如我的目录是 /usr/local/phoenix-4.14.0/
cd /usr/local/phoenix-4.14.0/
执行命令运行脚本
./bin/psql.py 192.168.30.217:2181 /data6/user.sql
或者
./bin/psql.py 192.168.30.217,192.168.30.130:2181 /data6/user.sql
192.168.30.217,192.168.30.130:2181 对应的是hbase集群的zookeeper集群的ip和端口,多个ip使用逗号隔开。
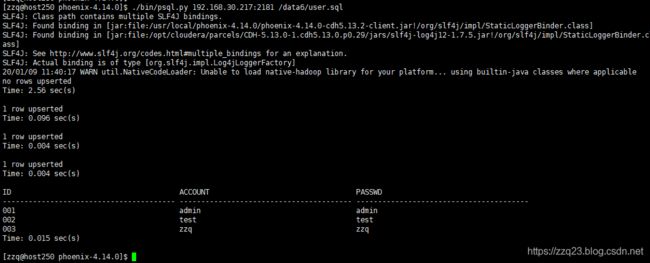
成功运行 输出如下:
[zzq@host250 phoenix-4.14.0]$ ./bin/psql.py 192.168.30.217:2181 /data6/user.sql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/phoenix-4.14.0/phoenix-4.14.0-cdh5.13.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
20/01/09 11:40:17 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
no rows upserted
Time: 2.56 sec(s)
1 row upserted
Time: 0.096 sec(s)
1 row upserted
Time: 0.004 sec(s)
1 row upserted
Time: 0.004 sec(s)
ID ACCOUNT PASSWD
---------------------------------------- ---------------------------------------- ----------------------------------------
001 admin admin
002 test test
003 zzq zzq
Time: 0.015 sec(s)
[zzq@host250 phoenix-4.14.0]$
Phoenix使用自带工具psql导入数据
在实际应用场景中可以会有一些格式比较规整的数据文件需要导入到HBase,Phoenix提供了两种方法来加载CSV格式的文件phoenix的数据表。
一种是使用单线程的psql工具进行小批量数据加载的方式,另一种是使用MapReduce作业来处理大批量数据的方式。
我们先来了解psql进行小批量的数据加载方式。
官方例子http://phoenix.apache.org/Phoenix-in-15-minutes-or-less.html
分步运行
创建表格
进入phoenix的命令行工具
[zzq@host250 bin]$ ./sqlline.py host217
在phoenix的命令行中使用命令:
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));

创建 us_population.csv文件使用命令:
vi /data6/us_population.csv
输入内容如下:
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
给该文件相应的权限
chmod 777 /data6/us_population.csv
在服务器的shell命令行中进入phoenix安装目录
cd /usr/local/phoenix-4.14.0/
运行导入
./bin/psql.py 192.168.30.217:2181 /data6/us_population.csv
导入成功输出如下:
[zzq@host250 phoenix-4.14.0]$ vi /data6/us_population.csv
[zzq@host250 phoenix-4.14.0]$ chmod 777 /data6/us_population.csv
[zzq@host250 phoenix-4.14.0]$
[zzq@host250 phoenix-4.14.0]$
[zzq@host250 phoenix-4.14.0]$ cd /usr/local/phoenix-4.14.0/
[zzq@host250 phoenix-4.14.0]$ ./bin/psql.py 192.168.30.217:2181 /data6/us_population.csv
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/phoenix-4.14.0/phoenix-4.14.0-cdh5.13.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
20/01/09 12:01:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
csv columns from database.
CSV Upsert complete. 10 rows upserted
Time: 0.052 sec(s)
[zzq@host250 phoenix-4.14.0]$

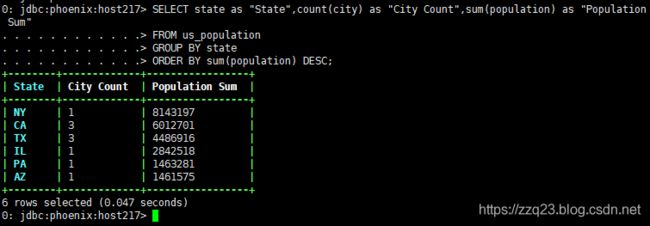
使用命令查询验证数据是否导入成功,使用命令:
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
输出如图:
多个脚本并列运行
psql工具也支持 多个sql脚本和导入数据csv并列运行.
例如我们创建table的语句放在us_population.sql文件中
使用命令
vi /data6/us_population.sql
输入内容
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
创建 us_population.csv文件使用命令:
vi /data6/us_population.csv
输入内容如下:
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
例如我们查询的语句放在us_population_queries.sql文件中
使用命令
vi /data6/us_population_queries.sql
输入内容
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
给这三个文件相应得访问权限如下:
chmod 777 /data6/us_population.sql
chmod 777 /data6/us_population.csv
chmod 777 /data6/us_population_queries.sql
进入phoenix安装目录:
cd /usr/local/phoenix-4.14.0/
运行命令如下:
./bin/psql.py 192.168.30.217:2181 /data6/us_population.sql /data6/us_population.csv /data6/us_population_queries.sql
效果同上。
Phoenix使用自带工具mapreduce.CsvBulkLoadTool导入数据
如果需要导入的数据量比较多,使用psql的方式会比较慢,因为psql是单线程的。针对大数据量的导入,phoenix提供了mapreduce的方式进行导入。使用步骤记录如下:
官方步骤示例 http://phoenix.apache.org/bulk_dataload.html
创建表格
进入phoenix的命令行工具
[zzq@host250 bin]$ ./sqlline.py host217
在phoenix的命令行中使用命令:
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));

准备数据
在服务器的shell命令行中创建 us_population.csv文件使用命令:
vi /data6/us_population.csv
输入内容如下:
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
注意,使用hadoop的mapreduce方式导入,输入文件需要在 hdfs文件系统中,不能使用服务器本机的路径。
所以 我们需要把 这个文件上传到hdfs的文件系统中。
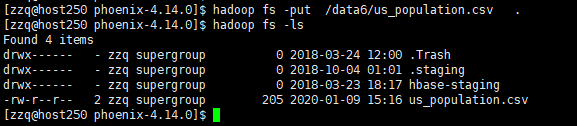
在服务器的shell命令行中运行命令:
hadoop fs -put /data6/us_population.csv .
可是使用命令查看是否上传成功
hadoop fs -ls
如图:
更多hdfs相关知识可参考
hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详解
hadoop基础----hadoop实战(二)-----hadoop操作hdfs—hdfs文件系统常用命令
运行导入命令,在phoenix安装目录运行
cd /usr/local/phoenix-4.14.0
phoenix4.0以下的版本使用命令行
hadoop jar phoenix--client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool --table us_population --input us_population.csv
phoenix4.0以上的版本使用命令行
HADOOP_CLASSPATH=/path/to/hbase-protocol.jar:/path/to/hbase/conf hadoop jar phoenix--client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool --table us_population --input us_population.csv
这里的/path/to/hbase-protocol.jar 以及 /path/to/hbase/conf 需要与自己安装的hadoop环境路径和版本对应。
需要明确一下路径。
如果不清楚在哪个路径在root账户或者sudo可以使用以下命令查找:
find / -name hbase-protocol
cdh版本的目录可参考:
hadoop基础----hadoop实战(十一)-----hadoop管理工具—CDH的目录结构了解
我的路径如下:
/opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol.jar
和
/etc/hbase/conf
所以使用的命令为:
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol.jar:/etc/hbase/conf hadoop jar phoenix-4.14.0-cdh5.13.2-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool --table us_population --input us_population.csv
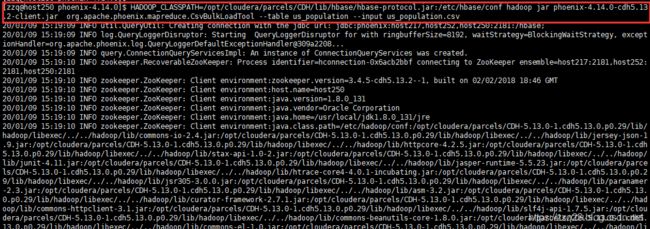
该作业会被提交到YARN由ResourceManager进行资源分配
运行成功输出如下:
20/01/09 15:19:17 INFO mapreduce.Job: The url to track the job: http://host250:8088/proxy/application_1566301006249_3059/
20/01/09 15:19:17 INFO mapreduce.Job: Running job: job_1566301006249_3059
20/01/09 15:19:28 INFO mapreduce.Job: Job job_1566301006249_3059 running in uber mode : false
20/01/09 15:19:28 INFO mapreduce.Job: map 0% reduce 0%
20/01/09 15:19:36 INFO mapreduce.Job: map 100% reduce 0%
20/01/09 15:19:43 INFO mapreduce.Job: map 100% reduce 100%
20/01/09 15:19:43 INFO mapreduce.Job: Job job_1566301006249_3059 completed successfully
20/01/09 15:19:43 INFO mapreduce.Job: Counters: 50
在phoenix的命令行中输入查询语句校验导入是否成功:
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
输出如下:
