使用Logstash将MySQL同步到Elasticsearch
一、环境准备
搭建es和kibana,可以参考我前面写的文章
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
二、环境搭建
将logstash安装包上传到Linux服务器下,安装logstash-input-jdbc和logstash-output-elasticsearch两个插件。
具体步骤如下:
### 上传logstash的安装包到/usr/local目录下
### 解压
tar -zxvf logstash-6.4.3.tar.gz
cd logstash-6.4.3
### 安装插件
bin/logstash-plugin install logstash-input-jdbc
bin/logstash-plugin install logstash-output-elasticsearch
### 在/usr/local目录下新建sql文件夹
mkdir /usr/local/sql
### 将mysql驱动jar包上传到该文件夹下
在SQL目录下新建文件
vi mysql_user.conf
input {
jdbc {
jdbc_driver_library => "/usr/local/sql/mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.1.102:3306/test"
jdbc_user => "root"
jdbc_password => "123456"
schedule => "* * * * *"
statement => "SELECT * FROM user WHERE update_time >= :sql_last_value"
use_column_value => true
tracking_column_type => "timestamp"
tracking_column => "update_time"
last_run_metadata_path => "syncpoint_table"
}
}
output {
elasticsearch {
# ES的IP地址及端口
hosts => ["192.168.112.150:9200"]
# 索引名称 可自定义
index => "user"
# 需要关联的数据库中有有一个id字段,对应类型中的id
document_id => "%{id}"
document_type => "user"
}
stdout {
# JSON格式输出
codec => json_lines
}
}
配置文件说明:
jdbc_driver_library: jdbc mysql 驱动的路径,在上一步中已经下载
jdbc_driver_class: 驱动类的名字,mysql 填 com.mysql.jdbc.Driver 就好了
jdbc_connection_string: mysql 地址
jdbc_user: mysql 用户
jdbc_password: mysql 密码
schedule: 执行 sql 时机,类似 crontab 的调度
statement: 要执行的 sql,以 “:” 开头是定义的变量,可以通过 parameters 来设置变量,这里的 sql_last_value 是内置的变量,表示上一次 sql 执行中 update_time 的值,这里 update_time 条件是 >= 因为时间有可能相等,没有等号可能会漏掉一些增量
use_column_value: 使用递增列的值
tracking_column_type: 递增字段的类型,numeric 表示数值类型, timestamp 表示时间戳类型
tracking_column: 递增字段的名称,这里使用 update_time 这一列,这列的类型是 timestamp
last_run_metadata_path: 同步点文件,这个文件记录了上次的同步点,重启时会读取这个文件,这个文件可以手
sql脚本:
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`update_time` timestamp(0) NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP(0),
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
启动logstash
cd /usr/local/logstash-6.4.3
./bin/logstash -f /usr/local/sql/mysql_user.conf

在user表中插入一条数据:

logstash打印出了日志:
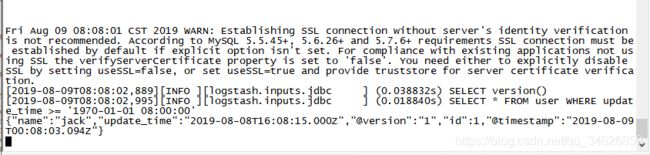
使用kibana查询:

logstash-input-jdbc原理
使用 logstash-input-jdbc 插件读取 mysql 的数据,这个插件的工作原理比较简单,就是定时执行一个 sql,然后将 sql 执行的结果写入到流中,增量获取的方式没有通过 binlog 方式同步,而是用一个递增字段作为条件去查询,每次都记录当前查询的位置,由于递增的特性,只需要查询比当前大的记录即可获取这段时间内的全部增量,一般的递增字段有两种,AUTO_INCREMENT 的主键 id 和 ON UPDATE CURRENT_TIMESTAMP 的 update_time 字段,id 字段只适用于那种只有插入没有更新的表,update_time 更加通用一些,建议在 mysql 表设计的时候都增加一个 update_time 字段
多文件方式同步ES数据
一个 logstash 实例可以借助 pipelines 机制同步多个表,只需要写多个配置文件就可以了,假设我们有两个表 user和 student,对应两个配置文件 mysql_user.conf 和 mysql_student.conf,在 config/pipelines.yml 中配置即可。
user表和mysql_user.conf文件如同上文
sql脚本:
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`update_time` timestamp(0) NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP(0),
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
mysql_student.conf文件
vi /user/local/sql/mysql_student.conf
input {
jdbc {
jdbc_driver_library => "/usr/local/sql/mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.1.102:3306/test"
jdbc_user => "root"
jdbc_password => "123456"
schedule => "* * * * *"
statement => "SELECT * FROM student WHERE update_time >= :sql_last_value"
use_column_value => true
tracking_column_type => "timestamp"
tracking_column => "update_time"
last_run_metadata_path => "syncpoint_table"
}
}
output {
elasticsearch {
# ES的IP地址及端口
hosts => ["192.168.112.150:9200"]
# 索引名称 可自定义
index => "student"
# 需要关联的数据库中有有一个id字段,对应类型中的id
document_id => "%{id}"
document_type => "student"
}
stdout {
# JSON格式输出
codec => json_lines
}
}
修改config/pipelines.yml文件
cd /usr/local/logstash-6.4.3
vi config/pipelines.yml
在最下面加上配置即可

启动logstash
cd /usr/local/logstash-6.4.3
./bin/logstash
启动成功之后,往user表和student表都插入数据


可以看到logstash输出的日志:

使用kibana查看:
