关联规则
何为关联规则,关联规则是发现事物之间关联关系的分析过程,其典型的例子就是购物篮分析。购物篮分析就是确定顾客在一次购物过程中一起购买的商品,通过分析发现不同商品之间的购买习惯,发现顾客购买的行为习惯,从而发现它们之间的关联。(在一次购买商品时,发现购买尿不湿的人会购买啤酒)。
关联规则的一般表现为蕴含式规则形式:X->Y。
x称为关联规则的前提或先导条件。y称为关联规则的结果或后继。为了更好地定义和表示关联规则,我们在这里引入置信度和支持度。置信度,也称为可靠度,或置信水平、置信系数,指总体参数值落在样本统计值某一区内的概率 。 支持度:两种或两种事件同时出现的概率。
下面我以实例来对置信度和可信度进行分析:
总共有10000个消费者购买了商品,其中购买尿布的有1000人,购买啤酒的有2000人,购买面包的有500人, 同时购买尿布和啤酒的有800人,同时购买尿布的面包的有100人。
置信度:购买X的人,同时购买Y的概率,例如:购买尿布的人,同时购买啤酒的概率,而这个概率就是购买尿布时购买啤酒的置信度。
confidence(x->y) = 同时购买{x,y}的人数/购买X的人数
confidence(y->x) = 同时购买{x,y}的人数/购买Y的人数
(尿布->啤酒)的置信度 = 800 / 1000 =0.8
(啤酒->尿布) 的置信度 = 800 / 2000 =0.4
由于规则置信度并未提供这条关联关系在所有交易中所占的比例(覆盖程度很低),即包含在关联关系中的购买行为是普遍交易行为,还是个别行为不得而知。下面我们可以使用支持度这个统计量来度量。用支持度度量包含了关联关系中出现的属性值的交易占所有交易的百分比。
支持度:{X,Y}同时出现的概率,例如:{尿布,啤酒}同时出现的概率:support=同时购买{X,Y}的人数/总人数。
{尿布,啤酒}的支持度 = 800/10000 =0.08
{尿布,面包}的支持度 = 100/10000 = 0.01
注意:支持度没有先后顺序之分。
关联分析过程中设置置信度和支持度的阈值,当得到的关联关系达到置信度和支持度的阈值时,这样的关联关系被认为是有趣的,而保留下来应用到实际问题中。(阈值又叫临界值,是指一个效应能够产生的最低值或最高值)。
为了更好地研究关联分析,我们引入-Apriori算法。
(1)生成条目集(Item Sets)。条目集是符合一定的支持度要求的“属性-值”的组合。例如:所有购买尿布=1的集合。那些不符合支持度要求的“属性-值”组合被丢弃,因此,规则的生成过程可以在合理的时间内完成。 (2)使用生成的条目集创建一组关联规则。
例2:将表1作为数据集,使用Apriori算法进行关联分析,产生描述网络购买行为的关联规则。
表1网络购物交易记录表
| 序号 |
Book |
Sneaker |
Earphone |
DVD |
Juice |
| 1 |
1 |
1 |
1 |
1 |
1 |
| 2 |
1 |
1 |
1 |
1 |
0 |
| 3 |
0 |
1 |
1 |
0 |
0 |
| 4 |
0 |
1 |
0 |
1 |
1 |
| 5 |
0 |
0 |
1 |
1 |
0 |
| 6 |
1 |
0 |
1 |
1 |
0 |
| 7 |
1 |
0 |
1 |
1 |
1 |
| 8 |
0 |
1 |
0 |
1 |
1 |
| 9 |
0 |
0 |
1 |
1 |
1 |
| 10 |
1 |
0 |
0 |
0 |
1 |
利用Apriori算法步骤:
(1)设置支持度阈值为50%,创建第一个条目集表,包含单项条目。
| 条目集 |
条目个数 |
符合支持度要求 |
结果 |
| Book = 1 |
5 |
Yes |
保留 |
| Sneaker = 1 |
5 |
Yes |
保留 |
| Earphone = 1 |
7 |
Yes |
保留 |
| DVD = 1 |
8 |
Yes |
保留 |
| Juice = 1 |
6 |
Yes |
保留 |
| Book = 0 |
5 |
Yes |
保留 |
| Sneaker = 0 |
5 |
Yes |
保留 |
| Earphone = 0 |
3 |
No |
删除 |
| DVD = 0 |
2 |
No |
删除 |
| Juice = 0 |
4 |
No |
删除 |
(2)设置支持度阈值为40%,创建第二个条目集表,包含双项条目。
| 条目集 |
条目个数 |
符合支持度要求 |
结果 |
|
| Book =1 & Earphone = 1 |
4 |
Yes |
保留 |
|
| Book =1 & DVD = 1 |
4 |
Yes |
保留 |
|
| Book =0 & DVD = 1 |
4 |
Yes |
保留 |
|
| Sneaker =1 & DVD = 1 |
4 |
Yes |
保留 |
|
| Sneaker =0 & Earphone = 1 |
4 |
Yes |
保留 |
|
| Sneaker =0 & DVD = 1 |
4 |
Yes |
保留 |
|
| Earphone = 1& DVD = 1 |
6 |
Yes |
保留 |
|
| DVD = 1 & Juice =1 |
5 |
Yes |
保留 |
|
(3)仍将支持度阈值设置为40%,使用双项条目表中的“属性-值”组合生成三项条目集,有两条条目。 Book =1 & Earphone = 1& DVD = 1 Sneaker =0 & Earphone = 1 & DVD = 1 。
(4)再次将支持度阈值设置为40%,以三项条目集为基础,生成四项条目集,没有符合支持度要求的条目,条目集生成工作结束。
(5)以生成的条目集为基础创建关联规则。 首先设置置信度阈值为80%;然后从双项和三项条目集表中生成关联规则;最后,所有不满足置信度阈值的规则将被删除。
用Apriori算法输出的实验结果:
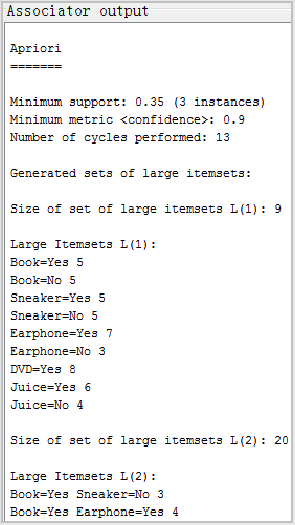
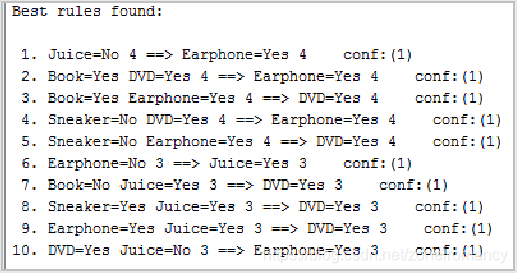
最后对关联规则的优缺点进行分析:
优势 关联规则不受因变量个数的限制,能够在大型数据库中发现数据之间的关联关系,所以其应用非常广泛。
局限性 一次关联分析输出的规则往往数量较多,且多数并无利用价值,所以对关联规则的解释和应用必须谨慎。