NIO系列(二) 直接缓冲DirectByteBuffer
1. 介绍
ByteBuffer底层是通过byte数组的方式来存储数据的,所谓直接缓冲是指byte数组是通过堆外存存储的,并没有存在jvm堆上,不受jvm垃圾回收的约束。
2. 直接缓冲和堆缓冲的创建方式
ByteBuffer的创建有两种方式,allocate和allocateDirect,其中通过allocate创建出来的是HeapByteBuffer(堆缓冲),源码如下:
// 创建堆缓冲,返回HeapByteBuffer
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
HeapByteBuffer继承ByteBuffer,在ByteBuffer中有byte数组来存储数据
public abstract class ByteBuffer extends Buffer
implements Comparable<ByteBuffer> {
// 存储数据的byte数组
final byte[] hb; // Non-null only for heap buffers
ByteBuffer(int mark, int pos, int lim, int cap, // package-private
byte[] hb, int offset) {
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
....
}
通过allocateDirect创建出来的是DirectByteBuffer(直接缓冲),源码如下:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
在创建DirectByteBuffer过程中,存储数据的空间通过native方法来进行内存分配和初始化,最终通过一个内存地址将DirectByteBuffer和存储数据的数组关联在一起。源码如下:
DirectByteBuffer(int cap) {
....
base = unsafe.allocateMemory(size); // 分配内存空间
....
unsafe.setMemory(base, size, (byte) 0); // 内存空间初始化
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1)); // 获取内存空间地址
} else {
address = base;
}
....
}
3. 为什么需要直接缓冲
如果使用堆缓冲,java堆属于用户空间,以IO输入为例,首先是用户空间进程向内核请求某个磁盘空间数据,然后内核将磁盘数据读取到内核空间的buffer中,然后用户空间的进程再将内核空间buffer中的数据读取到自身的buffer中,然后进程就可以访问使用这些数据,如下图: 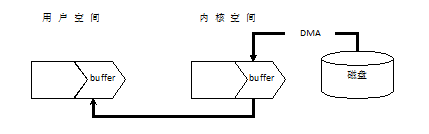
在上述过程中,有了一次数据拷贝,在高并发的场景下,必定有性能的损耗,直接缓冲就解决了此问题。目前的操作系统,用户空间和内核空间的区分一般采用虚拟内存来实现,因此用户空间和内存空间都是在虚拟内存中。使用虚拟内存无非是因为其两大优势:一是它可以使多个虚拟内存地址指向同一个物理内存;二是虚拟内存的空间可以大于物理内存的空间。对于第一点在进行IO操作时就可以将用户空间的buffer区和内核空间的buffer区指向同一个物理内存。这样用户空间的程序就不需要再去内核空间再取回数据,而是可以直接访问,避免了数据拷贝,提升性能。

再补充一个知识点,使用HeapByteBuffer时,为什么从磁盘读取数据到buffer需要做一次copy,为什么不能直接从磁盘copy到buffer。这个copy过程从jdk源码也有体现,如下:
/**
* var0: 文件描述符,表示将要读取数据的文件句柄
* var1: 我们创建出来的ByteBuffer,将要把文件的数据写入此buffer
*/
static int read(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) throws IOException {
// 如果时只读buffer直接报错
if (var1.isReadOnly()) {
throw new IllegalArgumentException("Read-only buffer");
} else if (var1 instanceof DirectBuffer) {
// 如果是DirectBuffer,那么直接把文件内容写入buffer
return readIntoNativeBuffer(var0, var1, var2, var4);
} else {
// 如果是HeapByteBuffer,那么先创建一个DirectByteBuffer
ByteBuffer var5 = Util.getTemporaryDirectBuffer(var1.remaining());
int var7;
try {
// 先把文件内容写入DirectByteBuffer
int var6 = readIntoNativeBuffer(var0, var5, var2, var4);
var5.flip();
if (var6 > 0) {
// 再把DirectByteBUffer内容写入我们传入的HeapByteBuffer
var1.put(var5);
}
var7 = var6;
} finally {
Util.offerFirstTemporaryDirectBuffer(var5);
}
return var7;
}
}
从源码看到,确实做了一次copy,这么做其实是在迁就OpenJDK里的HotSpot VM的一点实现细节。HeapByteBuffer存储对象的byte数组在java堆上,而HotSpot VM里的GC除了CMS之外都是要移动对象的,是所谓“compacting GC”。如果要把一个Java里的 byte[] 对象的引用传给native代码,让native代码直接访问数组的内容的话,就必须要保证native代码在访问的时候这个 byte[] 对象不能被移动,也就是要被“pin”(钉)住。可惜HotSpot VM出于一些取舍而决定不实现单个对象层面的object pinning,要pin的话就得暂时禁用GC——也就等于把整个Java堆都给pin住。HotSpot VM对JNI的Critical系API就是这样实现的。这用起来就不那么顺手。所以 Oracle/Sun JDK / OpenJDK 的这个地方就用了点绕弯的做法。它假设把 HeapByteBuffer 背后的 byte[] 里的内容拷贝一次是一个时间开销可以接受的操作,同时假设真正的I/O可能是一个很慢的操作。于是它就先把 HeapByteBuffer 背后的 byte[] 的内容拷贝到一个 DirectByteBuffer 背后的native memory去,这个拷贝会涉及 sun.misc.Unsafe.copyMemory() 的调用,背后是类似 memcpy() 的实现。这个操作本质上是会在整个拷贝过程中暂时不允许发生GC的,虽然实现方式跟JNI的Critical系API不太一样。(具体来说是 Unsafe.copyMemory() 是HotSpot VM的一个intrinsic方法,中间没有safepoint所以GC无法发生)。然后数据被拷贝到native memory之后就好办了,就去做真正的I/O,把 DirectByteBuffer 背后的native memory地址传给真正做I/O的函数。这边就不需要再去访问Java对象去读写要做I/O的数据了。
4. 直接缓冲的优缺点
4.1 优点
前面已经分析了,在进行IO操作时,例如文件读写,或者socket读写,少了一次copy性能有提升。
注意,仅限于有IO操作的场景下
4.2 缺点
在非IO操作的场景下,例如仅仅做数据的编解码,不和机器硬件打交道,那么即使使用了HeapByteBuffer也不会产生copy动作,如果此时仍然在使用DirectByteBuffer,由于数据存储部分在堆外存,内存空间的分配和释放比堆内存更加复杂一些,性能也稍慢一些,在netty中是通过buf池的方案来解决的,后续的netty博客会深入讲解。
基于此我们可以总结一下HeapByteBuffer和DirectByteBuffer的使用场景:对于后端业务的编解码操作,使用HeapByteBuffer,对于IO通信,使用DirectByteBuffer。