图形渲染及优化—Unity合批技术实践
在前面的文章中我介绍了Batch对于渲染效率的影响,这次来说说在Unity开发过程中常用的几种合批技术。
Resource Merging
我们可以在美术资源生产的过程中做很多渲染批次方面的优化。通常我们可以将一些使用相同材质的物体模型合并成一个模型,在游戏渲染的时候一次提交给渲染API进行绘制,降低了Draw call的数量。但是这样带来了一个问题,所有合并的模型必须一次全部绘制。哪怕这个模型只有一个边边角角在摄像机的视野里面,引擎的场景管理系统也要将整个模型提交给渲染API进行绘制。虽然管线中后续的计算会剔除不可见三角形,但是这样还是造成了一定的计算资源浪费。
对于场景中摆放位置非常相近的一些物体,这些物体通常可以被摄像机同时看到,我们可以通过合并模型的方法来达到降低Draw call数量的目的而不会带来不必要的计算代价。
如果一些模型引用的材质除了Texture其他参数都相同,我们可以将这些模型引用的Texture进行合并,将它们合并成一张更大的Texture。这样所有的模型都可以引用相同的材质,然后通过只设置一次渲染状态进行绘制了。虽然Draw call数量没有减少,但是避免了渲染状态的切换,同样达到了合批渲染的目的(原理请参看上一篇文章《图形渲染及优化—Batch》)。这项技术称为Texture atlasing,这是美术工作中最常用的方法,具体做法有大量内容可查。

Unity引擎内建了两种合批渲染技术:Static batching(静态合批)和Dynamic batching(动态合批)。
Static Batching
如果我们的游戏场景中有一些共享同一材质的模型存在,并且这些模型一直都不会移动、旋转和缩放。我们可以将这些模型设置为Static:

在Build的时候Unity会自动地提取这些共享材质的静态模型的Vertex buffer和Index buffer。根据其摆放在场景中的位置等最终状态信息,将这些模型的顶点数据变换到世界空间下,存储在新构建的大Vertex buffer和Index buffer中。并且记录每一个子模型的Index buffer数据在构建的大Index buffer中的起始及结束位置。

在后续的绘制过程中,一次性提交整个合并模型的顶点数据,根据引擎的场景管理系统判断各个子模型的可见性。然后设置一次渲染状态,调用多次Draw call分别绘制每一个子模型。
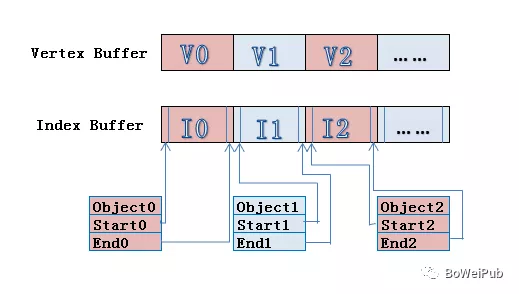
Static batching减少Draw call的数量(因为是通过index buffer控制的),但是由于我们预先把所有的子模型的顶点变换到了世界空间下,并且这些子模型共享材质,所以在多次Draw call调用之间并没有渲染状态的切换,渲染API会缓存绘制命令,起到了渲染优化的目的(原理请参看上一篇文章《图形渲染及优化—Batch》) 。另外,在运行时所有的顶点位置处理不再需要进行计算,节约了计算资源。一般的游戏场景中存在着大量的静态物体,所以我们可以尽量将不会移动、旋转和缩放的模型设置为“Static”来提高渲染的效率。
Static batching相比于我们前面说的,在美术资源生产阶段合并模型的办法更加灵活。我们可以在最终游戏场景设计阶段随意修改场景,并且在Unity中构建完各个场景之后,由Unity将模型打包合并。另外如果在美术资源生产阶段合并模型,后续在引擎里渲染的时候无法剔除不可见的子模型,造成了计算资源的浪费,这点Static batching根据可见性进行渲染,相对节省了计算资源。
Static batching也会带来一些性能的负面影响。Static batching会导致应用打包之后体积增大,应用运行时所占用的内存体积也会增大。见下图:

在很多不同的GameObject引用同一模型的情况下,如果不开启Static batching,GameObject共享的模型会在应用程序包内或者内存中只存在一份,绘制的时候提交模型顶点信息,然后设置每一个GameObjec的材质信息,分别调用渲染API绘制。
开启Static batching,在Unity执行Build的时候,场景中所有引用相同模型的GameObject都必须将模型顶点信息复制,并经过计算变化到最终在世界空间中,存储在最终生成的Vertex buffer中。这就导致了打包的体积及运行时内存的占用增大。
所以有时我们不得不对某些GameObject避免使用Static batching来节省一些运行时内存空间。
Dynamic Batching
Dynamic batching是专门为优化场景中共享同一材质的动态GameObject的渲染设计的。为了合并渲染批次,Dynamic batching每一帧都会有一些CPU性能消耗。如果我们开启了Dynamic batching,Unity会自动地将所有共享同一材质的动态GameObject在一个Draw call内绘制。
Dynamic batching的原理也很简单,在进行场景绘制之前将所有的共享同一材质的模型的顶点信息变换到世界空间中,然后通过一次Draw call绘制多个模型,达到合批的目的。模型顶点变换的操作是由CPU完成的,所以这会带来一些CPU的性能消耗。并且计算的模型顶点数量不宜太多,否则CPU串行计算耗费的时间太长会造成场景渲染卡顿,所以Dynamic batching只能处理一些小模型。
目前Unity限制能进行Dynamic batching的模型最高能有900个顶点属性。这里注意不是900个顶点,而是900个定点属性。如果我们在Shader中使用了Vertex Position,Normal and single UV,那么能够进行Dynamic batching的模型最多只能够有300个顶点。如果我们在Shader中使用了Vertex Position、Normal、UV0、UV1 and Tangent那么顶点的数量就减少到180个。这个顶点属性数量的要求是Unity自己设计的,未来随着硬件性能的提升,这个值也会调整。
Dynamic batching是否能够执行还有一些需要注意的地方:
1.Unity的文档中说,GameObject之间如果有镜像变换不能进行合批,例如,"GameObject A with +1 scale and GameObject B with –1 scale cannot be batched together"。
2.使用Multi-pass Shader的物体会禁用Dynamic batching,因为Multi-pass Shader通常会导致一个物体要连续绘制多次,并切换渲染状态。这会打破其跟其他物体进行Dynamic batching的机会。
3.Unity的Forward Rendering Path中如果一个GameObject接受多个光照那么光照的绘制会按照下面的流程进行:

如果一个GameObject接受一个以上的per-pixel light那么就会为每一个per-pixel light产生多余的模型提交和绘制。我们可以在Quality Settings中将的per-pixel light数量限制为1.

这样设置之后Unity通过各种条件判断只会选择出一个Light执行per-pixel lighting。GameObject的绘制在一个Pass内就可以完成,避免了附加的Pass,提高了可合批的概率。
4.在Unity的渲染管线中无论采用Forward Rendering或者是Deferred Rendering,半透明物体的渲染都要在最后采用Forward Rendering的方式渲染(Deferred Rendering无法支持半透明渲染)。所有的半透明物体在绘制之前要进行严格的排序,绘制操作按序执行。因为物体绘制的顺序被严格限定,所以物体间能够进行动态合批的概率很小。
5.我们知道能够进行合批的前提是多个GameObject共享同一材质,但是对于Shadow casters的渲染是个例外。仅管Shadow casters使用不同的材质,但是只要它们的材质中给Shadow Caster Pass使用的参数是相同的,他们也能够进行Dynamic batching。例如,场景中我们摆放了许多的箱子,他们的材质中引用的Texture不同, 但是在做Shadow Caster Pass渲染的时候Texture会被忽略,这些箱子是可以合批渲染的。这是因为Shadow渲染如果使用ShadowMap或其他的衍生算法,场景中的物体要绘制两遍。第一遍绘制Shadow pass要做一次深度渲染,只提取场景中Shadow casters物体的深度值。下面是Unity文档中的一段话:

Shadow Caster Pass在做Depth buffer渲染的时候我们不需要Fragment Shader关于颜色相关的结果,仅仅一个简单的能够输出深度值的Fragment Shader足以。而且对于几乎所有物体而言使用的Shadow Caster Pass又是相同的,所以这些Shadow caster物体就可以进行Dynamic batching了。
在目前比较主流的游戏引擎中,进行其他绘制之前都会首先执行一次Depth buffer渲染,尤其是在采用Deferred Rendering的时候。这一步不仅仅是为Shadow的绘制,更是为了后续执行其他像素计算相关Shader的时候能够在Early-Z阶段剔除不必要执行的Fragment计算,降低填充率,提高效率。
Dynamic batching在降低Draw call的同时会导致额外的CPU性能消耗,所以仅仅在合批操作的性能消耗小于不合批,Dynamic batching才会有意义。而新一代图形API( Metal、Vulkan)在批次间的消耗降低了很多,所以在这种情况下使用Dynamic batching很可能不能获得性能提升。Dynamic batching相对于Static batching不需要预先复制模型顶点,所以在内存占用和发布的程序体积方面要优于Static batching。但是Dynamic batching会带来一些运行时CPU性能消耗,Static batching在这一点要比Dynamic batching更加高效。所以我们在实践中可以根据具体的场景灵活地平衡两种合批技术的使用。
Static Batching In Runtime
Unity还提供了一种灵活度很高的运行时静态合批方法。我们可以在运行时调用StaticBatchingUtility.Combine实现将一些模型合并成一个完整模型。
这个函数的实现有两个版本:
// StaticBatchingUtility.Combine prepares all children of the staticBatchRoot for static batching.
// Once combined, children cannot change their Transform properties; however, staticBatchRoot can be moved.
public static void Combine(GameObject staticBatchRoot);
// StaticBatchingUtility.Combine prepares all gos for static batching.staticBatchRoot is treated as their parent.
// Once combined, gos cannot change their Transform properties; however, staticBatchRoot can be moved.
// The GameObject in gos must have MeshFilter components attached for this to work.
public static void Combine(GameObject[] gos, GameObject staticBatchRoot);
具体的使用方法上面的注释已经说的很清楚了,这里就不再讨论了。使用这种方法我们可以避免最终打包的应用体积增大,但是由于在运行时通过CPU做模型的合并,会到来一次性的运行时内存和CPU开销。
Bone Matrix Palette Batching
对于Skinned Mesh Unity通常是无法合批渲染的。但是我们可以借用Skinned Mesh的一些原理来实现对于动态GameObject的另外一种合批渲染技术。对于动态物体可能每一帧每个物体的Transform都不一样。我们可以模仿“Hardware Skinning”的渲染方式,但是让每个物体仅受一根骨骼影响,创建一个Transform matrix palette,其中存放的是我们打包的变换矩阵。我们将矩阵数据打包到两个float4中:
1.Axis / Angle
2.Translate / Uniform scale
在渲染时我们充分利用Shader的寄存器空间,一次将所有同批次物体的Transform传给Shader。渲染时顶点自动查找其引用的Transform进行顶点变换。
通过查询gl_MaxVertexUniformVectors可知OpenGL ES 3.0的各个实现至少应提供256个vertex uniform vector。我们假设实现只提供256个vertex uniform vector,每个物体的方位信息需要2个float4,那么我们最多可以一个Draw call合批渲染接近128个物体。
12年的时候我为公司的自研引擎开发物理引擎部分,当时有一个功能是Ragdoll。这个大家一定很熟悉,在很多追求真实物理效果的游戏中都会用到。在做Ragdoll的同时尝试了将身体各个部分肢解。是不是听起来有点残酷。。。
当我把身体各个部分肢解开,完全由身体绑定的刚体自由控制的时候,我突然想到每一个身体部分如果是一个原本就独立的物体,那么可以利用骨骼动画技术来做一些物体合批渲染。
这项技术比Static batching节约内存空间,又比Dynamic batching节约运算资源,在某些合适的场景里感兴趣的朋友可以试试。其实这种合批方式的本质跟我们下面介绍的Instancing渲染很像的。
GPU Instancing
这个特性是从OpenGL ES 3.0开始支持的,Unity5.4开始加入。具体的原理这里就不介绍了,如果介绍这个恐怕又得写一篇。。。 不了解的人可以去Google一下或者看一下Unity的文档。这里主要强调一下这个特性与Unity中的Static batching和Dynamic batching的关系:
1.Static batching的优先级要比Instancing的优先级高,如果一个GameObject被标记为static物体并且在Build阶段成功地执行了静态合批,那么如果这个物体还要使用Instancing Shader渲染的话,Instancing会失效。
2.Dynamic batching的优先级要低于Instancing。如果一个GameObject使用Instancing渲染的话,那么对于它的Dynamic batching会失效。
Unity Batch Debugging
很多时候我们需要Profile数据来查看我们渲染的场景的Draw call数量和Batch数量。Unity提供了Stats Pane、Profiler和Frame Debugger三个很方便的工具来帮助我们获得Batch相关数据。
Stats Pane
切换到Game视图,点击Stats会弹出Stats pane:
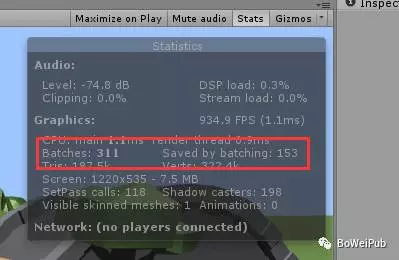
通过Stats pane我们可以获得两个数据:
1.Batches – 目前绘制场景可视区域的Batch数量。
2.Saved by batching – 通过合批渲染我们减少的Batch(Draw call)数量。
Profiler
通过Window -> Profiler或者Ctrl+7我们可以打开Unity Profiler工具。点击Rendering下面会出现我们需要的数据显示区域:

这里我们可以获得比Stats pane更加详细的数据。我们能够看到Static Batching和Dynamic Batching的具体执行情况,每种类型的合批技术处理的三角形及顶点的数量。
Frame Debugger
通过Window -> Frame Debugger我们可以打开Unity的Frame Debugger调试工具:

点击“Enable”按钮就可以开始调试场景的Frame渲染了。
通过Frame Debugger我们可以获得比Unity Profiler更加详细的批次渲染数据。我们可以查看每一个批次的渲染顺序,批次内合并了哪些内容,并且可以看出是什么因素导致了合批的失败而开启了一个新的批次。

我发布在这里的文章都是转至我的微信订阅号,如果你想及时获得最新发布的文章,可以关注我的微信订阅号。
