python 爬虫案例:爬取百度贴吧图片
文章更新于:2020-04-24
注1:打包后的程序(无需python环境)下载参见:https://ww.lanzous.com/ibvwref
注2:更多爬虫案例参见:https://github.com/amnotgcs/SpiderCase
一、分析
1.1、程序流程分析
1、从用户接收一个字符串
2、判断是否存在该贴吧
3、如果存在解析总页数,并接收两个数字作为提取图片的页数
4、循环保存图片
1.2、技术分析
1、贴吧超链接为 https://tieba.baidu.com/f?ie=utf-8&kw=关键字&pn=页数x50
2、所以我们从用户接收关键字、页数即可。
3、进入贴吧后,我们可以查看源码发现每页有 50 个帖子,超连接为 https://tieba.baidu.com/p/页面ID
4、所以我们从当前页面检索出所有的页面 ID ,然后自己构造 URL 进行访问即可。
5、进入帖子页面后,我们可以发现图片的超连接都在 BDE_Image 类的 a 标签里面
6、所以我们直接提取这个 a 标签的 href 属性使用 urllib.request.urlretrieve 进行保存即可。
7、其他细节根据需要进行完善。
二、源代码
import requests
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
from os import mkdir
def setKeyword():
# 构造带参 URL
url_prefix = "https://tieba.baidu.com/f?"
# 确定是否存在该吧
print("\n\n\t\t欢迎使用百度贴吧图片检索程序 v1.0")
print("\n\n\t\t程序更新于:2020-04-24 by amnotgcs")
keyword = input("\n\n\t\t请输入你要检索的贴吧名:")
url = "%sid=utf-8&kw=%s"%(url_prefix, urllib.parse.quote(keyword))
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
confirmName = soup.find('a', class_ = 'card_title_fname')
if confirmName:
# 输出贴吧名
print("\t\t已匹配:",confirmName.string.strip())
else:
print("\t\t该吧不存在")
return None
maxPage = soup.find('a', class_ = "last pagination-item")['href'].split("=")[-1]
maxPage = int(maxPage) // 50 +1
print("\n\t\t总共检索到 %d 页"%maxPage)
pageNum = int(input("\t\t请输入你想要获取的开始页数:"))
pageNumEnd = int(input("\t\t请输入你想要获取的结束页数:"))
pageList = []
if pageNumEnd - pageNum >= 0:
while pageNumEnd >= pageNum:
params = {
'ie':'utf-8',
'kw': keyword,
'pn': (pageNum-1)*50
}
url = url_prefix + urllib.parse.urlencode(params)
pageList.append(url)
pageNum += 1
return pageList
else:
return None
def get_html(url = ""):
if not url:
return None
# 获取网页源码
response = requests.get(url)
html_doc = response.text
# 调用解析函数
logString = "\n" + "-"*30 + "\n下面是:%s\n"%url + "-"*30 + "\n"
To_log(logString)
analyseHtml(html_doc)
def analyseHtml(html_doc = ""):
if not html_doc:
return None
# 进行解析
soup = BeautifulSoup(html_doc, 'html.parser')
entries = soup.find_all('a')
entries = soup.find_all('a', class_ = 'j_th_tit')
print("\n\n帖子位置:\t\t 主题:")
for item in entries:
logString = "\n%s\t%s"%(item['href'],item.string)
To_log(logString)
entryUrl = "https://tieba.baidu.com" + item['href']
# 定义图片名使用的前缀,防止覆盖
pageID = item['href'].split("/")[-1]
getImage(entryUrl, pageID)
def getImage(url, pageID):
if not url:
return None
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
except:
print("\n", url, "好像出错了哦~")
return None
# 定位图片
tags = soup.find_all('img', class_ = 'BDE_Image')
if len(tags):
logString = "\t\t||||||||||发现目标: %d 个图片"%len(tags)
To_log(logString)
else:
return None
global imgCount
for item in tags:
try:
urllib.request.urlretrieve(item['src'], r"./tiebaImg/%s_%d.jpg"%(pageID, imgCount))
except:
print("\n此图片保存失败", end = "")
imgCount += 1
def To_log(data):
with open('tiebaImg/result.txt', 'a', encoding = 'utf-8')as file:
file.write(data)
print(data, end = "")
def main():
global imgCount
imgCount = 0
try:
with open("tiebaImg/result.txt", 'w', encoding = 'utf-8')as file:
file.write("程序正常开始")
except:
mkdir("tiebaImg")
print("已经创建 tiebaImg 文件夹")
pageList = setKeyword()
if pageList:
for page in pageList:
get_html(page)
print("\n", "="*60, "\n\t\t共获取 %d 图片"%imgCount)
print("\t\t图片保存在程序所在目录 tiebaImg 文件夹内!")
else:
print("\t\t好像发现了什么奇怪了东西~")
end = input("\n\t\t按回车键结束关闭窗口~")
if __name__ == '__main__':
main()
三、运行截图
3.1、运行截图:
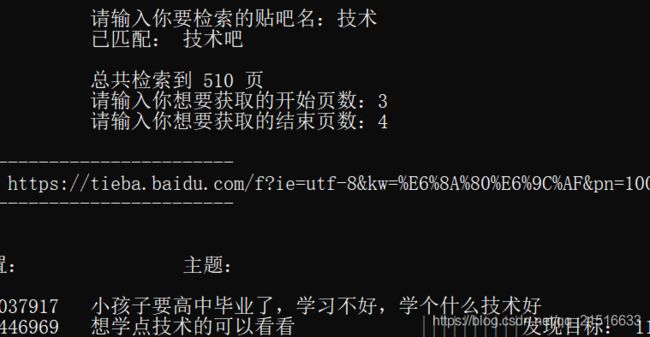
3.2、运行结果: