Fortran入门 - 基本语法一篇通
0.
前些日子为了准备汇报学了Fortran这个语言,最近又要用到发现有些些忘记了,所以写一篇博客整理记录学了些啥就当复习~
主要内容还是比较基本的语法,一些小细节等以后有机会来补上吧(下次一定.jpg)
【赶时间的话可以只看'简而言之'中的总结】
1.固定格式&自由格式

(图源自网络 侵删)
简而言之:
- 固定格式——比较老,老古董代码一般都是这种格式,需要读的时候能读懂就行,不用会写。
- 自由格式——目前的使用主流。
2.输入输出
入门一个语言从Helloworld开始!顺便熟悉一下Fortran的程序结构。

![]()
Fortran的程序通常都以program来开头,然后接一个自定义的程序名称。这个程序名称可以完全自定义,不需要与文件名有任何关系。程序结尾写上end。“implicit none”的功能是关闭默认类型,所有变量都要事先声明,因为Fortran会默认开头i,j,k,l,m,n的变量为整数型,其他的为浮点型。这行代码就是关闭这个功能,所有的变量都要声明后才能使用。防止手贱敲错代码编译器还不报错。
Fortran里的输出有两种,write和print。
- write,括号里有两个*号,第一个*号代表输出位置,默认是6,即屏幕。第二个*号代表输出格式化设定。
- print比write少一个*号,因为print是面向屏幕输出的。print的*号和write的第二个*号一样,代表输出的格式化设置。
一般习惯用write,毕竟功能多点。
Fortran里的输入:
- read,*的用法和write基本一致。
上文中提到的格式化:(具体的网上很多了,在这里只贴常用的“ I 、F、E、A、X ”这几个格式)
- Iw[.m] 以w个字符的宽度来输出整数,至少输出m个数字。如:write(*,“(I5)”) 100 输出:_ _100 ; 不足补空格 。
- Fw.d 以w个字符文本框来输出浮点数,小数部分占d个字符宽,输出文本框的设置不足显示*号。如:write(*,“(F9.3)”) 123.45 输出:_ _123.450 ; 不足补空格,小数不足补0。
- Ew.d[Ee] 用科学计数法,以w个字符宽来输出浮点数,小数部分占d个字符宽,指数部分最少输出e个数字。如:write(*,“(E15.7)” 123.45 输出:_ _0.1234500E+03 ; 不足部分补空格,小数部分不足补0。
- Aw 以w个字符宽来输出字符串。 如:write(*,“(A10)”) “Hello” 输出: _ _ _ _ _Hello。
- nX 输出位置向右移动n位。如:write(*,“(5X,I3)”) 100 输出:_ _ _ _ _100。
简而言之:
- 输出:
write(*,*)”hello”
print *,”hello”
- 输入:
read(*,*)a
- 格式化
Iw[.m] !以w个字符的宽度来输出整数,至少输出m个数字。
Fw.d !以w个字符文本框来输出浮点数,小数部分占d个字符宽,输出文本框的设置不足显示*号。输出不足补空格,小数不足补0。
Ew.d[Ee] !用科学计数法,以w个字符宽来输出浮点数,小数部分占d个字符宽,指数部分最少输出e个数字。
!输出不足部分补空格,小数部分不足补0。
Aw !以w个字符宽来输出字符串。
nX !输出位置向右移动n位。3.数据类型
其他的都是老生常谈,直接看简而言之里的就行了,提一提复数类型。Fortran是我知道的计算机语言里唯一一个直接提供复数类型以及计算的语言。下面是复数的声明、赋值、和一些基本的计算。


简而言之:
- 整数 integer
integer a
Integer :: a=10- 浮点数 real
real a
real(4) a- 字符 character
character a
character(len=10) b- 逻辑判断 logical
logical a
a=.true.- 复数 complex
complex :: a,b
a=(1.0,1.0)
b=(1.0,2.0)- 自定义类型 type(用%来访问)
type :: person
character(len=30) :: name
integer :: age
end type person !用%来访问,如a%age
4.数组
首先是声明,数组的声明方法有两种,常用的方法是直接在普通的变量声明后面括号内写上数组大小即可。
integer :: student(5) !一维数组
integer :: a(3,3) !二维数组
integer,dimension(3,3) :: a !另一种方法赋值可以直接顺序赋值,也可以像这样依靠一个隐式的循环来赋值。
integer :: a(5) = (/1,2,3,4,5/) !a(1)=1 a(2)=2 a(3)=2 a(4)=2 a(5)=5
integer :: a(5) = (/(I,I=1,5)/) !a(1)=1 a(2)=2 a(3)=3 a(4)=4 a(5)=5
integer :: a(2,2)=(/1,2,3,4/) !a(1,1)=1 a(2,1)=2 a(1,2)=3 a(2,2)=4
特别要注意的是最后一行二维数组的赋值结果,在Fortran中第一个维度是较低的维度,后面的是较高的维度,这和C语言是相反的。
Fortran一大特色是能够对数组进行直接操作,两个数组可以直接整体做加减,所以只要把矩阵放进二维数组中,就可以实现矩阵的加减。另外Fortran中也有原生函数可以实现矩阵相乘。也可以对数组的部分进行操作,比如这个例子,就是将数组d的第3个数到第5个数赋值为5。需要注意一下,Fortran中在没有特别赋值的情况下,数组的索引值是从1开始的。
integer :: a(3,3),b(3,3),c(3,3),d(5)
a=b+c !实现矩阵相加
a=b-c !实现矩阵相减
a=matmul(b,c) !实现矩阵相乘
d(3:5)=5 !对数组部分操作 d(3)=d(4)=d(5)=5

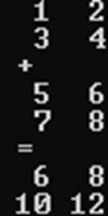
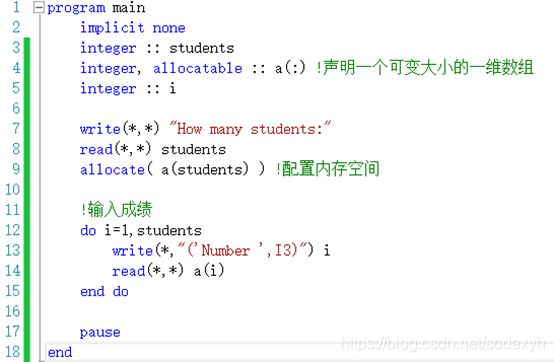
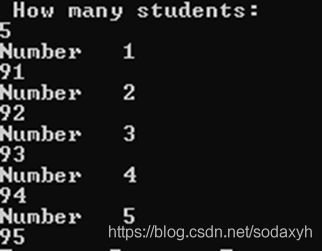
Fortran中可以声明可变大小的数组,只要在声明的时候加上allocatable的形容词,并注明是数组的维度,在后续需要确定大小的时候为数组配置内存空间即可。这里是一个可变数组的例子。
简而言之:
- 声明
datatype name(size) - 赋值
integer :: a(5) = (/1,2,3,4,5/) !a(1)=1 a(2)=2 a(3)=2 a(4)=2 a(5)=5 integer :: a(5) = (/(I,I=1,5)/) !a(1)=1 a(2)=2 a(3)=3 a(4)=4 a(5)=5 Integer :: a(2,2)=(/1,2,3,4/) !a(1,1)=1 a(2,1)=2 a(1,2)=3 a(2,2)=4 - 数组操作
integer :: a(3,3),b(3,3),c(3,3),d(5) a=b+c !实现矩阵相加 a=b-c !实现矩阵相减 a=matmul(b,c) !实现矩阵相乘 d(3:5)=5 !对数组部分操作 d(3)=d(4)=d(5)=5
5.逻辑判断
- if
if ( 逻辑判断式 ) then
……
end ifif ( 逻辑判断式 ) then
……
else
……
end ifif ( 逻辑判断式 ) then
……
else if ( 逻辑判断式2 ) then
……
end if
- select
在一些情况下,比如很多的else if对同一变量的判断的情况,可以简化代码量。
select case (变量)
case (数值1)
……
case (数值2)
……
case default
end select


简而言之:
- if
if ( 逻辑判断式 ) then
……
end ifif ( 逻辑判断式 ) then
……
else
……
end ifif ( 逻辑判断式 ) then
……
else if ( 逻辑判断式2 ) then
……
end if
- select
select case (变量)
case (数值1)
……
case (数值2)
……
case default
end select6.循环
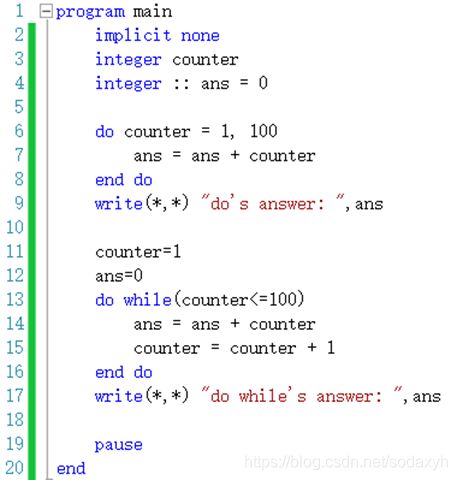
主要是do循环和do while循环两种,do循环用法比较类似c语言里的for循环,这三个量分别代表计数器,结束条件,计数器增量。
do循环:
do counter=1,lines,1
……
end do
do while循环:
do while ( 逻辑 )
……
end do下面这个例子是do循环和dowhile循环使用的一个展示。do循环计数器增量默认是1,这里可以省略。
![]()
另外循环中还有两个特殊控制字,cycle和exit,cycle的功能是直接进入下一次循环,exit是退出循环。
cycle 直接进入下一次循环
exit 退出循环
Fortran中循环可以署名,只要在前面加上名字即可,配合前面的cycle和exit可以实现多重循环中的跳跃。
outter:do i=1,3
inner:do j=1,3
……
end do inner
end do outter

简而言之:
! do循环
do counter=1,lines,1
……
end do
! do while循环
do while ( 逻辑 )
……
end do
! 两个特殊控制字
cycle !直接进入下一次循环
exit !退出循环
! 给循环署名(例outter)
outter:do i=1,3
inner:do j=1,3
……
end do inner
end do outter
7.函数
函数是自定义函数和子程序的总称。这个部分主要介绍自定义函数、子程序、全局变量、interface、特殊函数类型。
- 子程序
子程序的声明如下,subroutine 声明子程序并编写好内部的代码,在主程序中使用call来调用。
program main
……
call sub1()
……
end program main
subroutine sub1()
……
end subroutine sub1
需要注意的是,子程序中传递参数时是传址调用,也就是传递的是这个内存地址,在子程序中修改这个参数,主程序中的值也会变,可以看下面这个例子,a,b的初值是1和2,在调用add子程序之后,输出a,b来看,他们的值变成了2和3。


- 自定义函数
自定义函数的用法如下,先要在主程序里声明add是个函数而非变量,也就是加上external这个形容词。然后自定义函数里的定义要声明参数和函数名的数值类型,这个函数名就是函数返回的值。
和子程序不同的是,自定义函数的参数一般不改变,就好比一个函数的自变量,输出则是因变量。
program main
……
datatype,external :: add !声明add是个函数而非变量
……
end
function add(a,b)
datatype :: a,b
datatype :: add !声明返回数值类型
……
end
! 传给函数的参数一般不要改变。

![]()
- 全局变量
Fortran中的全局变量定义的是一块内存空间,采用的是地址对应。也就是说,比如你在主程序中定义了abc三个全局变量,在子程序中想要用,如果你只声明了一个,那对应的就是a,和你声明的名称无关,所以如果你要用第三个全局变量c,子程序里也必须要声明三个全局变量。这个麻烦可以通过分类解决,也就是给全局变量加上组别,这样声明的时候加上组别,就可以直接使用c了。
! 定义的是一块共享的内存空间。采用地址对应。
program main
implicit none
interger a,b,c
common a,b,c
……
end
subroutine sub()
implicit none
interger a,b,c
common a,b,c !假设只用第三个全局变量,也要声明前两个
end subroutine sub
! 通过分类解决这个麻烦
common /group1/ a,b
common /group2/ c关于common设置初值的方法,不能在主程序或者子程序里直接data设置,而是要单独写一个blockdata程序模块来设置初值。
block data
implicit none
integer a,b
common a,b
data a,b /1,2/
end block data- interface
interface是一段程序模块,用来说明所调用的函数的参数类型和返回值类型等等使用接口,一般来说是不必要的,不过这五种情况下是必须要使用interface的。
interface ! 定义函数func的接口
function random10(lbound, ubound)
implicit none
real :: lbound, ubound
real :: random10(10) ! 传回值是个数组
end function
end interface
1)函数返回值为数组时
2)指定参数位置来传递参数时
3)所调用的函数参数数目不固定(integer,optional :: b)
4)形参为数组片段时
5)函数返回值为指针时- 特殊函数类型
Fortran中特殊的函数类型需要特殊声明,比如说,递归函数,要加上recursive关键字和返回结果result。
内部函数,定义某些函数只能在某些特定的函数中被调用,在contains后面写内部函数的内容。
还有pure函数和elemental函数等,主要是配合并行运算来使用。
! 递归
recursive integer function fact(n) result(ans)
! 内部函数
program main
……
contains
subroutine localsub
end subroutine localsub
end program
! pure函数
配合并行运算使用
! elemental函数
配合并行运算使用,可以用来做数组的设置
简而言之:
- 子程序
program main
call sub1()
end program main
subroutine sub1()
…
end subroutine sub1
- 自定义函数
program main
datatype,external :: add !声明add是个函数而非变量
end
function func()
datatype :: add !声明返回数值类型
end
! 传给函数的参数一般不要改变。
- 全局变量
! 定义的是一块共享的内存空间。采用地址对应。假设在子程序中使用时只用第三个全局变量,也要声明前两个。
common a,b,c
! 通过分类解决这个麻烦。
common /group1/ a,b
common /group2/ c
! 在block data块中进行common初始化。- interface
interface ! 定义函数func的接口
function random10(lbound, ubound)
implicit none
real :: lbound, ubound
real :: random10(10) ! 传回值是个数组
end function
end interface- 特殊函数类型
递归 recursive
内部函数 contains
pure函数 pure 配合并行运算使用
elemental函数 elemental 配合并行运算使用,可以用来做数组的设置
8.文件
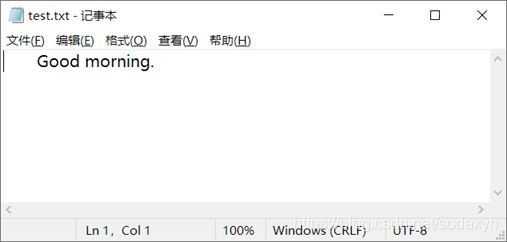
文件的最基本的语法,加一行open的语句,指明文件和文件id即可。write和read第一个星号的位置改成文件的id,就可以实现指定文件的输入输出了。
open(unit=10,file=‘test.txt’)
![]()
简而言之:
open(unit=10,file=‘test.txt’)*Fortran 90之后才加入的指针和面向对象,如果是为了读古董代码而学Fortran就没必要往下看了。(有兴趣的话就了解一下~)
9.指针
指针的作用:方便使用高维数组中的某一部分元素。或者是实现串行结构,比如说链表,树状数组之类的。
- 指针
这里是指针的基本用法,第一种,需要被指向的变量声明时要加上target形容词,指针声明时加上pointer形容词,然后就可以将指针p指向变量a的地址了。
integer, target :: a=1
integer, pointer :: p
p=>a
第二种方法是,声明一个指针p,再通过allocate给它分配内存,需要注意要记得释放内存。
integer, pointer :: p
allocate(p)
deallocate(p)
示例:

![]()
- 指针数组
指针也可以指数组,方法是一样的。
integer, pointer :: a(:)
integer, target :: b(5)=(/1,2,3,4,5/)
a=>binteger, pointer :: a(:)
allocate(a(5))
a=(/1,2,3,4,5/)
deallocate(a)示例:

![]()
10.面向对象
- module
可以通过module实现面向对象编程。比如下面这个例子。module里面的数据和函数都可以通过private和public命令来区分公开使用和私下使用。
module bank
implicit none
private money
public LoadMoney, SaveMoney, Report
integer :: money = 1000000
contains
subroutine LoadMoney(num)
implicit none
integer :: num
money=money-num
return
end subroutine
subroutine SaveMoney(num)
implicit none
integer :: num
money=money+num
return
end subroutine
subroutine Report()
implicit none
write(*,"('银行目前库存',I,'元')") money
end subroutine
end module
program main
use bank
implicit none
call LoadMoney(100)
call SaveMoney(1000)
call Report()
stop
end在外部要使用module里面的东西,需要使用use命令。
- 继承
继承的实现,只要在moduleA中使用moduleB,就可以理解为moduleA继承了moduleB公开的数据和函数,可以在此基础上继续编写新的功能。
- 重载
重载的实现,是在module中使用interface,来定义一个虚拟的函数名称,在外部使用这个虚拟的函数名称就可以了。
interface show ! 虚拟的函数名称show
module procedure show_int ! 等待选择的函数show_int
module procedure show_character ! 等待选择的函数show_character
end interface- 自定义操作符
自定义操作符,也是通过interface的帮助,比如这个例子,实现了对加号的重载。
interface operator(+)
module procedure add
end interface