深度学习:pyTorch实战计算机视觉
pyTorch深度学习框架:基于动态图计算的特性,基于静态图计算深度学习框架相比,更多的优势,速度快,强大的包可调用。
一、人工智能
1、人工智能:强人工智能: 智能 弱人工智能:人工
2、人工智能的三起两落:
- 1956年提出人工智能概念
- 1980 专家系统:指解决特定领域问题的能力已达到该领域的专家能力水平,其核心运用专家多年积累的丰富经验和专业知识,不断模拟专家解决问题的思维,处理只有专家才能解决的问题
- 1990 机器学习 深度学习
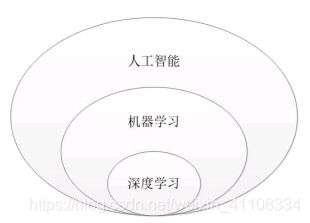
机器学习=统计学习方法(统计学原理)
3、1957 单层计算单元神经网络模型==感知机 perceptron 分类问题,二分类线性模型。
+1 -1 分离超平面 优点:容易处理线性可分,不能处理异或问题,也就是不能处理非线性问题。
4、多层神经网络模型,输入层 隐藏层 输出层
5、计算机视觉:机器能否对视觉信息进行收集,处理和分析,是机器智能一个重要的体现用途,让机器拥有人类一样的视觉能力也是计算机视觉诞生的初衷。 计算机视觉分为信息的收集,信息的分析,信息的处理。
6、图片分类,图像目标识别,图像语义分割(对识别的类别使用同一种像素进行标识打上标签)
7、自动驾驶
8、图像风格迁移Neural style
二、相关数学知识
1、矩阵运算
标量:独立存在的数
向量:一维:一列按顺序排列的元素
矩阵matrix:二维数组结构
张量:数组的维度超过了二维,高维数组
矩阵的加法 减法 乘法。
2、导数求导
一阶导数的几何意义:斜率
复合链式求导法则
三、深度学习网络基础
| 监督学习 | 无监督学习 | 半监督学习 | 弱监督学习 |
| 回归问题(连续) | 聚类 | ||
| 分类问题(离散) |
| 过拟合 | 增加数据 | dropout | 采用正则化方法(L0.L1L2) | |
| 欠拟合 | 增加特征项 | 构造复杂多项式 | 减少正则化参数 |
1、向后传播
2、损失函数
| 均方误差函数 mse | 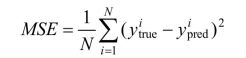 |
| 均方根误差函数 RMSE |  |
| 平均绝对误差函数 |  |
3、优化算法
相关参数的初始化,参数以何种形式调优,取适合的学习率
梯度: 偏导,向后传播中对各个参数求得的偏导数

| 一阶 优化函数 | |
| GD 梯度下降 gradient descent | 全局梯度下降 训练的样本的总数,学习率,容易出现局部最优和抖动 J(θ) 是总体 |
| SGD 随机梯度下降 | stochastic gradient descent J(θ) 是选取随机一部分数据集包含随机个样本数量 ,因为是随机容易发生局部最优解 |
| BGD 批量梯度下降 | batch gradient descent J(θ) 是一个batch |
| Momentum | |
| adgrad | |
| Adam | adaptive moment estimation 通过让每个参数获得自适应的学习率,大损失大学习率 小损失小学习率,避免出现局部最优解,优点收敛快,学习效果好,对学习速率消失,收敛过慢,高方差的参数更新等损失值波动,adam有很好的解决方案。 |
4、激活函数
如果没有激活函数,构造神经网络模型过程中,一直就是 线性模型 ,线性模型在对非线性问题的时候有这很大的局限,激活函数,引入非线性因素,非线性模型处理更加复杂的问题
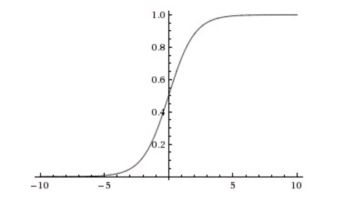
| sigmoid |
sigmoid 的导数取值是0-0.25
缺点:在正无穷和负无穷的时候会出现梯度消失。 反向传播过程中,最大0.25 ,如果模型到达一定的深度,那么反向传播的梯度就会越来越小 sigmoid 函数的输出值恒大于0,优化过程中收敛变慢。增加时间成本, 取参使用零中心,zero-centered 数据。 |
| tanh |
tanh函数输出结果是零中心数据,解决激活函数过程中收敛速度变慢的问题,但是导数0-1之间,仍然不够大。 |
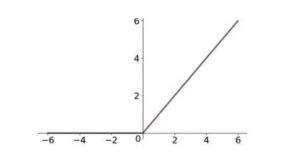
| relu 修正线性单元 | f(x)=max(0,x)
收敛速度快, ReLu 的输出不是零数据中心, 有些神经元永远不会被更新,模型参数初始化使用全正或者全负的值,后向传播速度太快, 合理学习率使用Adam. leaky-relu,r-relu. 优点: sigmoid 和tanh 计算指数 非饱和性,解决梯度消失的问题 单侧抑制,提供网络的稀疏性表达能力。 |

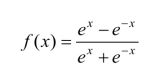

5、GPU/CPU
CPU:中央处理器 计算处理核心,负责计算机的控制命令处理和核心运算输出 串行
GPU:图像处理器,主机的显示处理核心,主要负责对计算机中的图形和图像的处理与运算 并行
深度学习张量、矩阵 并行计算
四、卷积神经网络 convolutional neural network cnn
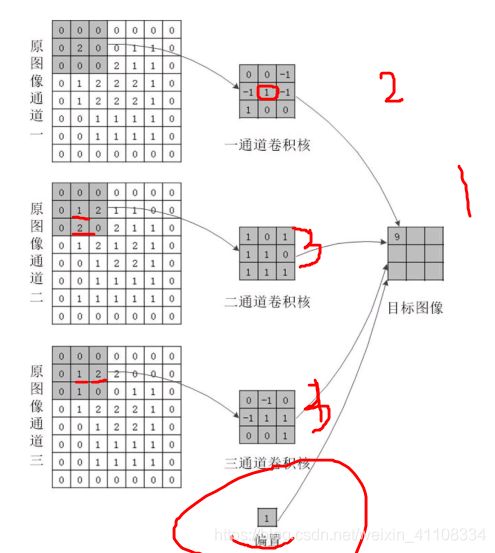
1、卷积核:特征的提取,卷积核,卷积边界像素填充:same:最外层指定层数的值全为0的像素边界, valid 直接对输入图像进行卷积。
卷积通用公式 s 步长,p padding


三通道卷积
2、池化 卷积神经网络中的一种提取输入数据特征的方式,压缩数据。减少参与模型计算的参数。
max 、average

3、全连接层 特征压缩完成模型的分类功能。
4、经典网络模型:lenet, alexnet,vggnet goolenet,resnet
https://blog.csdn.net/weixin_41108334/article/details/83827332
五、python入门
https://mp.csdn.net/postedit/85873680
九、多模型融合
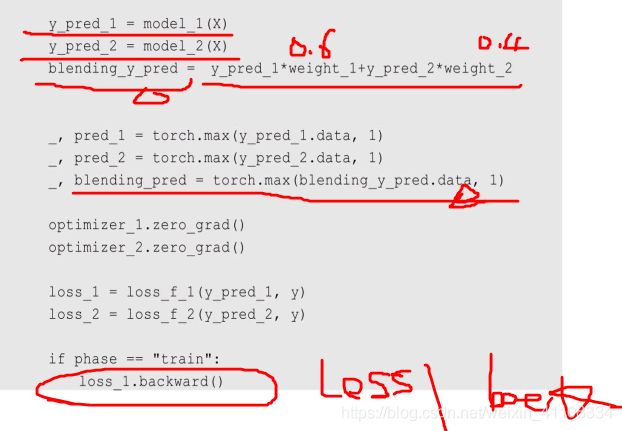
集百家之长 :宗旨:通过科学的方法融合各个模型的优势,以获得对未知问题的更强的解决能力。
结果融合:针对模型的输出结果进行融合,主要包括结果多数表决,结果直接平均 和 结果加权平均这三个主要的类型。
十、循环神经网络
recurrent neural network 处理序列 sequences
循环卷积 循环单元可以随意的控制输入输入和输出的数量,具有非常大的灵活性
RNN --->LSTM(长短期记忆, 如果近期的数据发生变化,则对输出结果产生重大影响,)
RNN 手写体识别 分类任务


模型变成rnn 其他的 loss和优化算法 准确度等同
RNN--》自然语言处理领域, 视频数据
十一、自动编码器 autoencoder
无监督学习的神经网络 1、核心特征提取的编码部分,2、 实现数据重构的解码部分
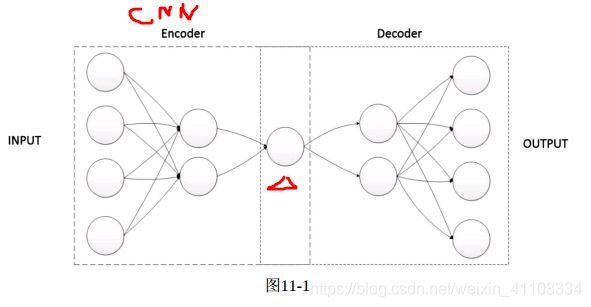
自动编码: 用途实现输入数据的清洗, 除去数据中的噪声数据,对输入数据的某些关键特征进行增强和放大

上采样
