10. 基于近似的on-policy控制方法--阅读笔记【Reinforcement Learning An Introduction 2nd】
文章目录
- 基于近似的on-policy控制方法
-
- 前言
- 1. episodic半梯度控制
- 2.半梯度n-step sarsa
- 3.平均奖励:针对连续任务的一种新的回报形式
- 4.弃用折扣设置deprecating the discounting setting
- 5. 微分半梯度n-step sarsa算法
- 总结
基于近似的on-policy控制方法
前言
本章将讲解控制问题,也就是如何找到一个优化策略。结合上一节参数化的方法,动作值函数的拟合函数 q ^ ( s , a , w ) ≈ q ∗ ( s , a ) \hat{q}(s,a,\mathbf{w})\approx q_{*}(s, a) q^(s,a,w)≈q∗(s,a),其中 w ∈ R d \mathbf{w} \in \mathbb{R}^{d} w∈Rd.目前我们主要采用on-policy的方法。并且本章将重点关注半梯度Sarsa算法,是基于上一节的半梯度TD(0)扩展而来的。对于episodic task来说,半梯度Sarsa是很自然的,但是对于continuing task来说,就需要回到折扣化的最优策略定义重新进行分析。本章先从episodic task入手,先将之前的关于状态值函数的近似延伸为动作值函数的近似;然后再探讨基于GPI模式和greedy的控制方法。把n-step 线性Sarsa在mountain car环境上进行测试,最后扩展到continuing task。
1. episodic半梯度控制
episodic半梯度Sarsa预测
首先将之前的半梯度预测方法扩展到动作值函数,这样才可以得到半梯度控制方法。主要有以下几个变化:估计目标发生变化 ,现在我们要估计的是 q ^ ( s , a , w ) \hat{q}(s,a,w) q^(s,a,w)。之前对于值函数估计的样本形式是 S t ↦ U t S_{t} \mapsto U_{t} St↦Ut,现在对于动作值函数估计的样本形式就变为了 S t , A t ↦ U t S_{t},A_{t} \mapsto U_{t} St,At↦Ut。这里的 U t U_{t} Ut可以是任意一种对于 q π ( S t , A t ) q_{\pi}(S_t,A_t) qπ(St,At)的近似。比如MC的回报 G t G_t Gt,或者是n-step Sarsa。
G t : t + n ≐ R t + 1 + γ R t + 2 + . . . + γ n − 1 R t + n + γ n q t + n − 1 ( S t + n , A t + n , w t ) , n ≥ 1 , 0 ≤ t < T − n G_{t:t+n} \doteq R_{t+1}+\gamma R_{t+2}+...+\gamma^{n-1}R_{t+n}+\gamma^{n}q_{t+n-1}(S_{t+n},A_{t+n},w_t),n≥1,0≤t
所以基于半梯度的权重更新公式为
w t + 1 ≐ w t + α [ U t − q ^ ( S t , A t , w t ) ] ∇ q ^ ( S t , A t , w t ) \mathbf{w}_{t+1} \doteq \mathbf{w}_{t}+\alpha\left[U_{t}-\hat{q}\left(S_{t}, A_{t}, \mathbf{w}_{t}\right)\right] \nabla \hat{q}\left(S_{t}, A_{t}, \mathbf{w}_{t}\right) wt+1≐wt+α[Ut−q^(St,At,wt)]∇q^(St,At,wt)
当更新方式采用的是one-step Sarsa时,更新公式就可以写作:
w t + 1 ≐ w t + α [ R t + 1 + γ q ^ ( S t + 1 , A t + 1 , w t ) − q ^ ( S t , A t , w t ) ] ∇ q ^ ( S t , A t , w t ) \mathbf{w}_{t+1} \doteq \mathbf{w}_{t}+\alpha\left[R_{t+1}+\gamma \hat{q}\left(S_{t+1}, A_{t+1}, \mathbf{w}_{t}\right)-\hat{q}\left(S_{t}, A_{t}, \mathbf{w}_{t}\right)\right] \nabla \hat{q}\left(S_{t}, A_{t}, \mathbf{w}_{t}\right) wt+1≐wt+α[Rt+1+γq^(St+1,At+1,wt)−q^(St,At,wt)]∇q^(St,At,wt)
这个式子对应的算法就叫做episodic 半梯度单步sarsa算法。对于一个固定的策略来讲,该算法可以保证要估计的动作值函数渐进收敛到真实的动作值函数。
episodic半梯度Sarsa控制
按照传统的GPI的思路,在得到动作值函数的预测之后再配合一定的策略提升,就可以逐渐收敛到一个最优策略上。但是对于连续动作空间或者很大的离散动作空间来讲,目前还没有有效的技术可以进行动作选择。对于离散的不太大的动作空间,可以借助之前的方法计算出每个动作的 q ^ ( S t , a , W t ) \hat{q}(S_t,a,W_t) q^(St,a,Wt),然后再通过贪婪策略选择值最大的对应的动作即可。

example:mountain car
任务描述:让一个动力不足的小车按照一定策略越过山顶某个goal。看下图所示。
因为动力不足,所以小车必须先向左边开,积累一定的势能之后再加上自身现有的动力才能到达目标点。小车到达goal则episode结束,如果超过左边的边界就重置task。
状态空间:二维连续空间。-1.2≤ x t + 1 x_{t+1} xt+1≤0.5,-0.07≤ v t + 1 v_{t+1} vt+1≤0.07,位置和速度两个变量
动作空间:+1,-1, 0。分别表示正向马力全开,逆向马力全开,关闭引擎
模型:状态转移方程:
x t + 1 ≐ bound [ x t + x ˙ t + 1 ] x ˙ t + 1 ≐ bound [ x ˙ t + 0.001 A t − 0.0025 cos ( 3 x t ) ] \begin{array}{l} {x_{t+1} \doteq \text{bound}\left[x_{t}+\dot{x}_{t+1}\right]} \\ {\dot{x}_{t+1} \doteq \text{bound}\left[\dot{x}_{t}+0.001 A_{t}-0.0025 \cos \left(3 x_{t}\right)\right]} \end{array} xt+1≐bound[xt+x˙t+1]x˙t+1≐bound[x˙t+0.001At−0.0025cos(3xt)]
回报: -1/step
线性近似 :采用线性近似器来表示动作值函数。
q ^ ( s , a , w ) ≐ w ⊤ x ( s , a ) = ∑ i = 1 d w i ⋅ x i ( s , a ) \hat{q}(s, a, \mathbf{w}) \doteq \mathbf{w}^{\top} \mathbf{x}(s, a)=\sum_{i=1}^{d} w_{i} \cdot x_{i}(s, a) q^(s,a,w)≐w⊤x(s,a)=i=1∑dwi⋅xi(s,a)
其中x(s,a)是特征向量,借助上一章中提到的任意一种特征构造方法均可。这里采用tile-coding的方法,把连续状态编码为二值特征。
构造堆编码特征 :采用8个tilings,每个tiling有64个tile,tiling之间采用非对称偏移方式。对于每个状态来说就是一个8维的表征向量。这个8维向量中的每个值就是每个tiling中落在对应状态上的tile的地址/索引。因为要返回索引,所以一般采用哈希表存储。具体关于堆编码的使用,查看:http://incompleteideas.net/tiles/tiles3.html
学习的目标函数是值函数的负数(因为一般的提供的都是梯度下降法,要求一个最小值,如果值函数的负数最小那就意味着值函数本身最大)


2.半梯度n-step sarsa
上一节中我们提到了半梯度单步sarsa预测方法,实际上就是通过单步自举来估计 U t U_t Ut,那么对于n-step sarsa来说就是自举到n步。
G t : t + n ≐ R t + 1 + γ R t + 2 + ⋯ + γ n − 1 R t + n + γ n q ^ ( S t + n , A t + n , w t + n − 1 ) , t + n < T G_{t : t+n} \doteq R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{n-1} R_{t+n}+\gamma^{n} \hat{q}\left(S_{t+n}, A_{t+n}, \mathbf{w}_{t+n-1}\right), \quad t+n
当t+n>T时, G t : t + n G_{t : t+n} Gt:t+n就等价于MC的计算方式。
因此对于半梯度n-step Sarsa预测方法来讲,就是用上式计算 G t : t + n G_{t : t+n} Gt:t+n代替之前的 U t U_t Ut即可。
w t + n ≐ w t + n − 1 + α [ G t : t + n − q ^ ( S t , A t , w t + n − 1 ) ] ∇ q ^ ( S t , A t , w t + n − 1 ) , 0 ≤ t < T \mathbf{w}_{t+n} \doteq \mathbf{w}_{t+n-1}+\alpha\left[G_{t : t+n}-\hat{q}\left(S_{t}, A_{t}, \mathbf{w}_{t+n-1}\right)\right] \nabla \hat{q}\left(S_{t}, A_{t}, \mathbf{w}_{t+n-1}\right), \quad 0 \leq t

基本的计算流程与上一节一样,只是计算 U t U_t Ut的方式变了。同时,这个流程与第七章中表格型的计算方法也完全一样,仅仅是把查表转换成了计算线性近似器 q ^ ( S , A , w t ) \hat{q}(S,A,w_t) q^(S,A,wt)
比较n=1和n=8时算法的学习速度:

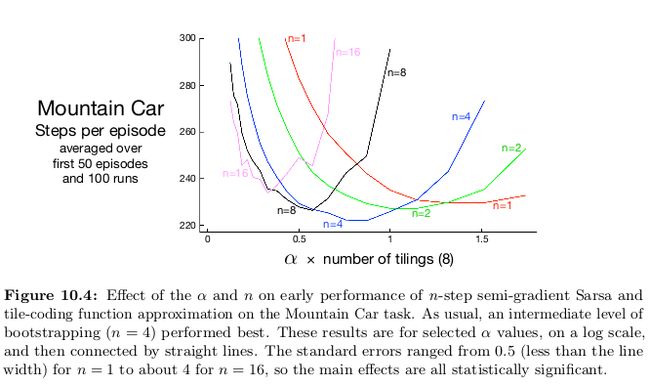
3.平均奖励:针对连续任务的一种新的回报形式
对于continuing task来说,在采用值函数近似的方法中需要定义一种新的值函数----平均回报,平均回报是没有折扣因子的,所以所有后续回报对当前状态的值都有等价值的影响作用。下一节我们会讨论为什么折扣的累积回报在带有拟合器的方法中是不合适的,平均回报则表现不错。
平均回报
定义如下:
r ( π ) ≐ lim h → ∞ 1 h ∑ t = 1 h E [ R t ∣ S 0 , A 0 : t − 1 ∼ π ] = lim t → ∞ E [ R t ∣ S 0 , A 0 : t − 1 ∼ π ] = ∑ s μ π ( s ) ∑ a π ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) r \begin{aligned} r(\pi) & \doteq \lim _{h \rightarrow \infty} \frac{1}{h} \sum_{t=1}^{h} \mathbb{E}\left[R_{t} | S_{0}, A_{0 : t-1} \sim \pi\right] && \\ &=\lim _{t \rightarrow \infty} \mathbb{E}\left[R_{t} | S_{0}, A_{0 : t-1} \sim \pi\right] && \\ &=\sum_{s} \mu_{\pi}(s) \sum_{a} \pi(a | s) \sum_{s^{\prime}, r} p\left(s^{\prime}, r | s, a\right) r \end{aligned} r(π)≐h→∞limh1t=1∑hE[Rt∣S0,A0:t−1∼π]=t→∞limE[Rt∣S0,A0:t−1∼π]=s∑μπ(s)a∑π(a∣s)s′,r∑p(s′,r∣s,a)r
其中 μ π ( s ) ≐ lim t → ∞ P r { S t = s ∣ A 0 : t − 1 ∼ π } \mu_{\pi}(s) \doteq \lim_{t \rightarrow \infty} Pr\left\{S_{t}=s | A_{0:t-1} \sim \pi\right\} μπ(s)≐limt→∞Pr{ St=s∣A0:t−1∼π}表示的是状态的稳态分布。假设这个分布一定存在,且和初始状态S0无关,这一特性在MDP中叫做各态遍历性。其含义就是无论MDP从哪个状态开始或者agent早期采取什么样的决策,仅仅只会产生瞬时的影响,长远来看,处于某个状态的概率只与策略和转移概率有关。
能够使得上式 r ( π ) r(\pi) r(π)最大化的策略就是最优策略。 μ π ( s ) \mu_\pi(s) μπ(s)叫做稳态分布的含义就是,无论在policy下采取什么样的action或者状态之间如何进行转移,最终状态的分布依然不变:
∑ s μ π ( s ) ∑ a π ( a ∣ s ) p ( s ′ ∣ s , a ) = μ π ( s ′ ) \sum_{s} \mu_{\pi}(s) \sum_{a} \pi(a | s) p\left(s^{\prime} | s, a\right)=\mu_{\pi}\left(s^{\prime}\right) s∑μπ(s)a∑π(a∣s)p(s′∣s,a)=μπ(s′)
微分值函数
有了上述平均回报的定义,根据这个回报定义一个continuing task对应的新的回报,表示为每步立即回报的值与平均回报之间的差值的和:
G t ≐ R t + 1 − r ( π ) + R t + 2 − r ( π ) + R t + 3 − r ( π ) + ⋯ G_{t} \doteq R_{t+1}-r(\pi)+R_{t+2}-r(\pi)+R_{t+3}-r(\pi)+\cdots Gt≐Rt+1−r(π)+Rt+2−r(π)+Rt+3−r(π)+⋯
这个回报叫做微分/差分回报 ,对应的值函数叫做微分/差分值函数 。其状态值函数和动作值函数的表示为:
v π ( s ) ≐ E π [ G t ∣ S t = s ] q π ( s , a ) ≐ E π [ G t ∣ S t = s , A t = a ] v_{\pi}(s) \doteq \mathbb{E}_{\pi}\left[G_{t} | S_{t}=s\right] \\ q_{\pi}(s, a) \doteq \mathbb{E}_{\pi}\left[G_t|S_{t}=s, A_{t}=a\right] vπ(s)≐Eπ[Gt∣St=s]qπ(s,a)≐Eπ[Gt∣St=s,At=a]
微分值函数对应的贝尔曼方程和最优贝尔曼方程为 :
v π ( s ) = ∑ a π ( a ∣ s ) ∑ r , s ′ p ( s ′ , r ∣ s , a ) [ r − r ( π ) + v π ( s ′ ) ] q π ( s , a ) = ∑ r , s ′ p ( s ′ , r ∣ s , a ) [ r − r ( π ) + ∑ a ′ π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) ] v ∗ ( s ) = max a ∑ r , s ′ p ( s ′ , r ∣ s , a ) [ r − max π r ( π ) + v ∗ ( s ′ ) ] , q ∗ ( s , a ) = ∑ r , s ′ p ( s ′ , r ∣ s , a ) [ r − max π r ( π ) + max a ′ q ∗ ( s ′ , a ′ ) ] \begin{array}{l} {v_{\pi}(s)=\sum_{a} \pi(a | s) \sum_{r, s^{\prime}} p\left(s^{\prime}, r | s, a\right)\left[r-r(\pi)+v_{\pi}\left(s^{\prime}\right)\right]} \\ {q_{\pi}(s, a)=\sum_{r, s^{\prime}} p\left(s^{\prime}, r | s, a\right)\left[r-r(\pi)+\sum_{a^{\prime}} \pi\left(a^{\prime} | s^{\prime}\right) q_{\pi}\left(s^{\prime}, a^{\prime}\right)\right]} \\ {v_{*}(s)=\max _{a} \sum_{r, s^{\prime}} p\left(s^{\prime}, r | s, a\right)\left[r-\max _{\pi} r(\pi)+v_{*}\left(s^{\prime}\right)\right], \text { }} \\ {q_{*}(s, a)=\sum_{r, s^{\prime}} p\left(s^{\prime}, r | s, a\right)\left[r-\max _{\pi} r(\pi)+\max _{a^{\prime}} q_{*}\left(s^{\prime}, a^{\prime}\right)\right]} \end{array} vπ(s)=∑aπ(a∣s)∑r,s′p(s′,r∣s,a)[r−r(π)+vπ(s′)]qπ(s,a)=∑r,s′p(s′,r∣s,a)[r−r(π)+∑a′π(a′∣s′)qπ(s′,a′)]v∗(s)=maxa∑r,s′p(s′,r∣s,a)[r−maxπr(π)+v∗(s′)], q∗(s,a)=∑r,s′p(s′,r∣s,a)[r−maxπr(π)+maxa′q∗(s′,a′)]
这里没有了折扣系数并且r也发生了变化。
对应微分形式的TD error可以表示为:
δ t ≐ R t + 1 − R ‾ t + v ^ ( S t + 1 , w t ) − v ^ ( S t , w t ) δ t ≐ R t + 1 − R ‾ t + q ^ ( S t + 1 , A t + 1 , w t ) − q ^ ( S t , A t , w t ) \delta_{t} \doteq R_{t+1}-\overline{R}_{t}+\hat{v}\left(S_{t+1}, \mathbf{w}_{t}\right)-\hat{v}\left(S_{t}, \mathbf{w}_{t}\right) \\ \delta_{t} \doteq R_{t+1}-\overline{R}_{t}+\hat{q}\left(S_{t+1}, A_{t+1}, \mathbf{w}_{t}\right)-\hat{q}\left(S_{t}, A_{t}, \mathbf{w}_{t}\right) δt≐Rt+1−Rt+v^(St+1,wt)−v^(St,wt)δt≐Rt+1−Rt+q^(St+1,At+1,wt)−q^(St,At,wt)
其中 R ‾ t \overline{R}_{t} Rt是t时刻的平均回报 r ( π ) r(\pi) r(π)。结合上面的定义,之前所讲过的所有算法和结论都可以适用于平均回报的情况,例如微分形式的半梯度sarsa算法只需要把 w t + 1 ≐ w t + α δ t ∇ q ^ ( S t , A t , w t ) \mathbf{w}_{t+1} \doteq \mathbf{w}_{t}+\alpha \delta_{t} \nabla \hat{q}\left(S_{t}, A_{t}, \mathbf{w}_{t}\right) wt+1≐wt+αδt∇q^(St,At,wt)中的 δ t \delta_{t} δt换成对应的微分形式的求解方式即可。
微分形式的半梯度sarsa预测方法伪代码:(注意 R ‾ t \overline{R}_{t} Rt的求解过程)

example:
来自:https://blog.csdn.net/u013695457/article/details/91353072

4.弃用折扣设置deprecating the discounting setting
对于基于表格的问题,之前介绍的折扣方法会取得较好的结果,但是对于采用近似拟合器的情况这种办法就会有一些问题。
假设对于一个没有始终的无穷序列,那么没有明确定义的状态,状态只能用特征向量来表示,假设特征向量不变。我们需要利用回报序列和动作序列来评价策略的好坏。由于没有明确定义的状态,所以无法给出每个状态的值。那么我们可以计算从当前时刻起很长区间的折扣累积回报,但是不同时间的累积折扣汇报不同,所以可以算不同时刻的累积回报的均值,以此作为序列好坏的衡量标准。最终得到的结果实际上是 r ( π ) / ( 1 − γ ) r(\pi)/(1-\gamma) r(π)/(1−γ),折扣因子实际上没有任何意义。
证明:
J ( π ) = ∑ s μ π ( s ) v π γ ( s ) (其中 v π γ 是折扣价值函数) = ∑ s μ π ( s ) ∑ a π ( a ∣ s ) ∑ s ′ ∑ r p ( s ′ , r ∣ s , a ) [ r + γ v π γ ( s ′ ) ] (Bellman 方程) = r ( π ) + ∑ s μ π ( s ) ∑ a π ( a ∣ s ) ∑ s ′ ∑ r p ( s ′ , r ∣ s , a ) γ v π γ ( s ′ ) = r ( π ) + γ ∑ s ′ v π γ ( s ′ ) ∑ s μ π ( s ) ∑ a π ( a ∣ s ) p ( s ′ ∣ s , a ) = r ( π ) + γ ∑ s ′ v π γ ( s ′ ) μ π ( s ′ ) = r ( π ) + γ J ( π ) = r ( π ) + γ r ( π ) + γ 2 J ( π ) = r ( π ) + γ r ( π ) + γ 2 r ( π ) + γ 3 r ( π ) + ⋯ = 1 1 − γ r ( π ) \begin{aligned} J(\pi) &=\sum_{s} \mu_{\pi}(s) v_{\pi}^{\gamma}(s) & \text { (其中 } v_{\pi}^{\gamma} \text { 是折扣价值函数) } \\ &=\sum_{s} \mu_{\pi}(s) \sum_{a} \pi(a | s) \sum_{s^{\prime}} \sum_{r} p\left(s^{\prime}, r | s, a\right)\left[r+\gamma v_{\pi}^{\gamma}\left(s^{\prime}\right)\right] &\text {(Bellman 方程)} \\ &=r(\pi)+\sum_{s} \mu_{\pi}(s) \sum_{a} \pi(a | s) \sum_{s^{\prime}} \sum_{r} p\left(s^{\prime}, r | s, a\right) \gamma v_{\pi}^{\gamma}\left(s^{\prime}\right) & \\ &=r(\pi)+\gamma \sum_{s^{\prime}} v_{\pi}^{\gamma}\left(s^{\prime}\right) \sum_{s} \mu_{\pi}(s) \sum_{a} \pi(a | s) p\left(s^{\prime} | s, a\right) & \\ &=r(\pi)+\gamma \sum_{s^{\prime}} v_{\pi}^{\gamma}\left(s^{\prime}\right) \mu_{\pi}\left(s^{\prime}\right) & \\ &=r(\pi)+\gamma J(\pi) \\ &=r(\pi)+\gamma r(\pi)+\gamma^{2} J(\pi) \\ &=r(\pi)+\gamma r(\pi)+\gamma^{2} r(\pi)+\gamma^{3} r(\pi)+\cdots \\ &=\frac{1}{1-\gamma} r(\pi) \end{aligned} J(π)=s∑μπ(s)vπγ(s)=s∑μπ(s)a∑π(a∣s)s′∑r∑p(s′,r∣s,a)[r+γvπγ(s′)]=r(π)+s∑μπ(s)a∑π(a∣s)s′∑r∑p(s′,r∣s,a)γvπγ(s′)=r(π)+γs′∑vπγ(s′)s∑μπ(s)a∑π(a∣s)p(s′∣s,a)=r(π)+γs′∑vπγ(s′)μπ(s′)=r(π)+γJ(π)=r(π)+γr(π)+γ2J(π)=r(π)+γr(π)+γ2r(π)+γ3r(π)+⋯=1−γ1r(π) (其中 vπγ 是折扣价值函数) (Bellman 方程)
对于近似的方法,我们计算的是value error关于参数的导数,也就是说我们关注的是策略整体性能的好坏,并不是所有状态值函数的加权均值。所以折扣因子并不影响策略的相对好坏,对于连续任务来说,使用平均回报就可以取得很好的效果。但是我们最初基于表格化的方法是针对每个状态下的策略单独进行考虑的,不同策略之间并不会相互影响,因此不必看成一个整体。所以可以使用折扣值函数定义。
从理论上分析,是因为近似拟合器的引入导致了策略提升理论失效。所以对于单个状态值函数的提升就无法导致整体策略提升。因为单个状态值函数的变化在近似拟合器上会影响其他状态。
实际上,对于episodic task,使用平均回报依然无法保证策略有所提升。因为拟合器类方法在理论上没有保证。后续会介绍策略梯度理论,该理论类似与策略提升,在该理论下可以保证策略有所改善。
5. 微分半梯度n-step sarsa算法
之前的内容我们介绍了半梯度n-step sarsa算法以及微分回报形式,本节介绍的微分半梯度sarsa算法实际上就是把之前半梯度n-step sarsa算法中计算回报 G t G_t Gt的方式改为微分回报形式即可。
G t : t + n ≐ R t + 1 − R ‾ t + n − 1 + ⋯ + R t + n − R ‾ t + n − 1 + q ^ ( S t + n , A t + n , w t + n − 1 ) G_{t : t+n} \doteq R_{t+1}-\overline{R}_{t+n-1}+\cdots+R_{t+n}-\overline{R}_{t+n-1}+\hat{q}\left(S_{t+n}, A_{t+n}, \mathbf{w}_{t+n-1}\right) Gt:t+n≐Rt+1−Rt+n−1+⋯+Rt+n−Rt+n−1+q^(St+n,At+n,wt+n−1)
注意这里的 R ‾ \overline{R} R是需要进行估计的。完整的TD error表达式为:
δ t ≐ G t : t + n − q ^ ( S t , A t , w ) \delta_{t} \doteq G_{t : t+n}-\hat{q}\left(S_{t}, A_{t}, \mathbf{w}\right) δt≐Gt:t+n−q^(St,At,w)
算法的伪代码如下:注意计算 R ‾ \overline{R} R的方式:

核心步骤就是:求微分形式的TD error;更新平均回报的估计;沿梯度方向更新权重
总结
本章主要在第九章的基础上介绍了如何使用半梯度方法求策略。对于episodic task来说直接采用GPI模式扩展即可。对于continuing task来说,引入了一个新的问题形式化方法,平均回报 ,通过比较平均回报来评价策略的好坏。基于这个平均回报,定义了一种新的回报形式,微分回报以及对应的微分值函数、贝尔曼方程等等。