Java集合:List、Set和Map需要注意的5个问题
前言
Java集合中的List、Set和Map作为Java集合食物链的顶级,可谓是各有千秋。本文将对于List、Set和Map之间的联系与区别进行介绍,以及这三者衍生出来的问题进行介绍(若无特地说明,jdk版本皆为1.8):
- List、Set和Map的联系和区别是什么?
- List、Set和Map的使用场景有哪些?
- List与Set之间的怎么转换?
- Set是怎么保证元素不重复?
- 如何在遍历的同时删除ArrayList中的元素?
1. List、Set和Map的联系和区别

List和Set是Collection的实现类,而Map与Collection是属于“同级“。
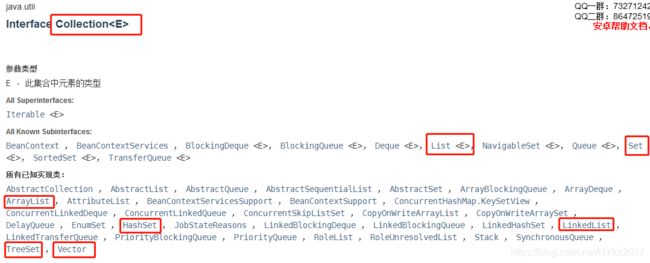
List

List的特性:
- List允许插入重复元素;
- List允许插入多个null元素;
- List作为有序集合,保证了元素按照插入的顺序进行排列;
- List提供ListIterator迭代器,可以提供双向访问的功能;
- List常用的实现类有:可随意访问元素的ArrayList、应用于增删频繁的LinkedList、利用synchronized关键字实现线程安全的Vector等。
Set
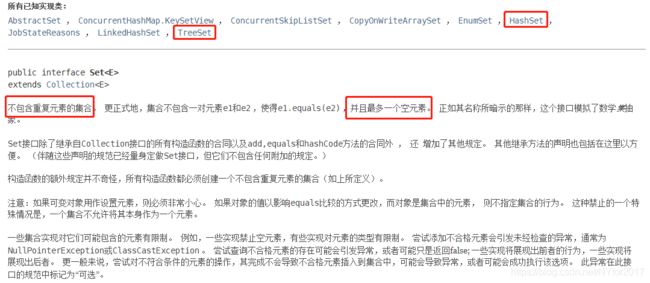
Set的特性:
- Set不包含重复元素;
- Set只允许一个null元素的存在;
- Set接口较为流行的实现类有:基于HashMap实现的HashSet、实现SortedSet接口且能更具compare()和compareTo()的定义进行排序的TreeSet等。
Map
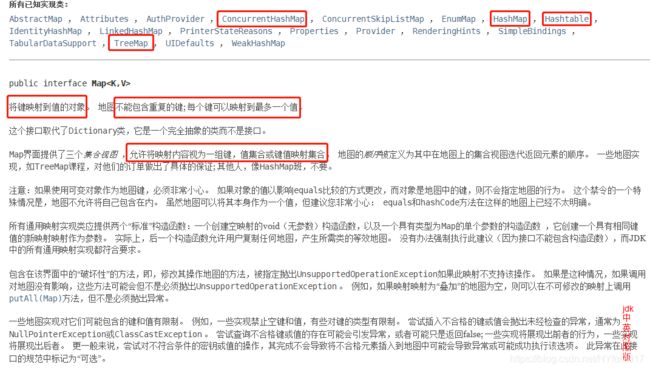
Map的特性:
- 存储结构是键值对,一个键对应一个值;
- 不允许包含重复的键,Map可能会持有相同的值对象,但键对象必须是唯一的;
- 在Map中可以有多个null值,但最多只能有一个null键;
- Map不是Collection的子接口或实现类**,Map是跟Collection“同级”的接口**;
- Map中比较流行的实现类是采用散列函数的HashMap、以及利用红黑树实现排序的TreeMap等。
2. List、Set和Map的使用场景
上文我们介绍完了List、Set和Map之间的联系和区别,接下来我们来看下这三者在使用场景上的差异。
List
如果经常使用索引来访问元素,或者是需要能够按照插入顺序进行存储,List会是不错的选择。
- 需要使用索引来访问容器的元素,ArrayList可以提供更快速的访问(底层是数组实现);
- 需要经常增删元素,LinkedList则会是最佳的选择(底层是链表实现);
- 数据量不大,并且有线程安全(synchronized关键字)的要求,可以选择Vector;
- 有线程安全(ReentrantLock实现)和性能的要求,读多写少的情况,CopyOnWriteArrayList会是更好的选择。
Set
想要保证插入元素的唯一性,可以选择Set的实现类。
- 需要快速查询元素,可以使用HashSet(采用散列函数);
- 如果有排序元素的需要,可以使用TreeSet(采用红黑树的树结构排序元素);
- 急需要加快查询速度,还需要按插入顺序来存储数据,LinkedHashSet是最好的选择(采用散列函数的同时,还使用链表维护元素的次序)。
Map
如果需要按键值对
- 需要快速查询键值元素,可以使用HashMap(采用散列函数);
- 如果需要将键进行排序,可以使用TreeMap(按照红黑树对键进行排序);
- 在存储数据少,不允许有null值,又有线程安全(synchronized关键字)的要求,可以选择Hashtable(父类是Dictionary);
- 如果需要线程安全(Node+CAS+Synchronized),且有数据量和性能要求,ConcurrentHashMap是最佳的选择。
3. List与Set之间的转换
因为List和Set都实现了Collection接口中的addAll(Collection c)方法,而且List和Set也提供了Collection c为参数的构造函数,所以可以采用构造函数的形式,完成List和Set的互相转换。
addAll(Collection c)方法
public boolean addAll(Collection<? extends E> c) {
boolean modified = false;
for (E e : c)
if (add(e))
modified = true;
return modified;
}
以Set接口的实现类HashSet为例,其提供了Collection c为参数的构造函数。
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
以List接口的实现类ArrayList为例,也可以看到它提供了Collection c为参数的构造函数。
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
.......
}
所以我们可以得到Set与List之间的转换方式:
Set<Integer> set = new HashSet<>(list); //List转Set
List<Integer> list = new ArrayList<>(set); //Set转List
4. Set是怎么保证元素不重复?
我们以Set接口最流行的实现类HashSet为例,对Set保证元素不重复的原因进行介绍。
private transient HashMap<E,Object> map;
public boolean add(E e) {
//如果return true,则表示不包含此元素
return map.put(e, PRESENT)==null;
}
从上可知,HashSet是依赖HashMap得以实现,其中添加的元素作为HashMap的键来存储。所以接下来就是在介绍“HashMap是怎么保证不允许有相同的键存在”了。
public V put(K key, V value) {
//倒数第二个参数为false,表示允许旧值替换
//最后一个参数为true,表示HashMap不处于创建模式
return putVal(hash(key), key, value, false, true);
}
在这里,我们可以看到在进行putVal()方法之前,会将key代入hash()方法中进行散列。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果哈希表为空,调用resize()方法创建一个哈希表,并用n记录哈希表的长度
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果指定参数hash(key的hashCode()值)在表中没有对应的桶,即没有碰撞
//(n-1)&hash计算key将被放置的槽位
//(n-1)&hash本质上是hash%n,只是位运算更快
if ((p = tab[i = (n - 1) & hash]) == null)
//如果没有碰撞,直接将键值对插入到map中即可
tab[i] = newNode(hash, key, value, null);
else {
//如果桶中已经存在了元素
Node<K,V> e; K k;
//比较桶中的第一个元素(数组中的结点)的hash值、key是否相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//如果相等,则将第一个元素p用e来记录
e = p;
else if (p instanceof TreeNode) //当前桶中无该键值对,且桶的结构为红黑树,则按照红黑树结构的规则插入元素
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果桶中无该键值对,且桶的结构为链表,则按照链表结构将元素插入到尾部
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//遍历到链表尾部
p.next = newNode(hash, key, value, null);
//检查链表长度是否达到阈值,达到则将该槽位的节点组织形式,转化为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//链表节点中的元素与put操作控制的元素相同时,不做重复操作,直接跳出程序
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果put操作控制的元素的key和hashCode,与已经插入的元素相等时,执行以下操作
if (e != null) {
// existing mapping for key
// oldValue记录e的value
V oldValue = e.value;
// onlyIfAbsent为false,或旧值为null时,允许替换旧值,否则无需替换
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//访问后回调
afterNodeAccess(e);
//返回旧值
return oldValue;
}
}
// 更新结构化修改信息
++modCount;
// 键值对数目如果超过阈值时,执行resize()方法
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
从以上源码中我们可以看出,将一个键值对
当HashSet中的add()方法里,map.put(e, PRESENT) == null为false时,HashSet添加元素失败。所以如果向HashSet中添加一个已经存在的元素,新添加的元素不会覆盖原来已有的元素。
5. 如何在遍历的同时删除ArrayList中的元素?
平时我们可能会觉得遍历ArrayList并删除其中元素是一件很简单的事情,但其实这个操作很容易出bug,接下来我们一起看下怎么样绕过这些坑。
从后向前遍历元素
我们先从前向后遍历的同时,进行删除元素:
public static void main(String[] args){
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list.add(4);
for(int i=0; i<list.size()-1; i++){
if(list.get(i) == 3){
list.remove(new Integer(3));
}
}
System.out.println(list);
}
运行结果为:
[1, 2, 3, 4]
造成这个现象的原因,在【Java集合】ArrayList的使用及原理中笔者稍有提及。在于ArrayList执行remove()操作时,将既定元素删除时还把该元素后的所有元素向前移动一位。这就导致了在遍历[1,2,3,3,4]时,删除前一个元素“3”后,将其后元素向前移动一位,因下标[2]已经被遍历过了,所以就遗漏了第二个“3”。
对于这个问题,我们只需要换个遍历的角度即可——从后往前遍历:
for(int i=list.size()-1; i>=0; i--){
if(list.get(i) == 3){
list.remove(new Integer(3));
}
}
运行结果为:
[1, 2, 4]
从后往前遍历,在删除某一元素之后,也不用担心在遍历过程中会遗漏元素。
Iterator.remove()
除了上述遍历方法,还有一种遍历方式是我们经常使用的——for-each遍历:
for(Integer i : list){
if(i == 3){
list.remove(new Integer(3));
}
}
运行结果:
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:901)
at java.util.ArrayList$Itr.next(ArrayList.java:851)
...
我们知道,for-each的遍历方式其实是Iterator、hashNext()、next()的复合简化版。当点开ArrayList.checkForComodification()方法可以看到:
private class Itr implements Iterator<E> {
......
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
这里的modCount是ArrayList的,而expectedModCount是Itr的,所以其实出错的地方在于,运行ArrayList.remove()方法时改变了modCount,这就打破了原本modCount == expectedModCount之间和平友好的关系,导致报出并发修改异常。
所以在使用迭代器迭代时(显示或for-each的隐式)不要使用ArrayList.remove(),改为使用Iterator.remove()即可:
Iterator<Integer> i = list.iterator();
while(i.hasNext()){
Integer integer = i.next();
if(integer == 3){
i.remove();
}
}
结语
本来昨天就已经写好了,然而电脑一卡,啥都没了,只能重写…
如果本文对你有帮助,请给一个赞吧,这会是我最大的动力~
参考资料:
List、Set、Map的区别
ArrayList循环遍历并删除元素的常见陷阱
Java中Set集合是如何实现添加元素保证不重复的?
本文已经授权以原创的方式发布在微信公众号Java后端。