Redis学习简单笔记
一. Redis介绍.
1. 引言:
-
在服务器搭建集群之后,由于每台Tomcat的Session都是独立存在的,会导致Session数据不一致的问题.
使用nginx的ip_hash可以处理. Redis实现Session共享. -
在海量数据查询时,关系型数据库,MySQL,Oracle,DB2,每次查询数据都会通过SQL语句,再通过MySQL的解析并且通过IO的方式从本地获取数据.
针对一些经常被访问的数据,并且修改频率不高的内容做缓存. -
分布式锁,Redis在接收用户请求时,是单线程, Redis在内部处理任务时,是多线程.
…
2. Redis的由来.
意大利有一家统计网站信息的公司,LLOOGG统计网站的信息的,当前一直使用MySQL数据库.
公司老板认为MySQL的性能不足以支撑他们的LLOOGG.老板绝对为LLOOGG量身定制一块全新的数据库.
在2009年的时候,这款数据库研发完成,Redis.
同年这位老板将Redis开源.
Redis的版本已经维护到了5.x的版本,VMware也在支持Redis的维护.
3. Redis的特点.
Redis是一款NoSQL. -> 非关系型数据库. Not Only SQL (泛指)
非关系型数据库:
Key-Value:
Redis.
文档型:
ElasticSearch,Solr..
面向列:
Hbase,Cassandra..
图形:
Neo4j...
Redis的优势:
1. 对数据可以进行高并发读写.
2. 对海量数据的高效存储和访问.
3. 垂直扩展,水平扩展.
4. Redis是可以持久化数据的.
....
Redis的劣势:
Redis无法做到太复杂的关系数据库模型.
二. Redis的安装以及连接.
1. 准备yml文件.
version: '3.1'
services:
redis:
image: daocloud.io/library/redis:5.0.4
restart: always
container_name: redis
environment:
- TZ=Asia/Shanghai
ports:
- 6379:6379
volumes:
- /opt/redis-compose/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
2. 准备redis.conf文件
http://download.redis.io/releases/redis-5.0.4.tar.gz
解压压缩包,并且将redis.conf文件取出,放到指定位置.
3. 使用图形化界面连接Redis.
1. 安装图形化界面.
傻瓜式安装 Redis-Desktop-Manager.
2. 修改Redis的配置文件.
# bind 127.0.0.1 # 将本地ip注释.
protected-mode no # 关闭保护机制.
3. 使用图形化界面连接Redis
三. Redis存储数据的结构.
1. key-string (最常用的方式)
2. key-hash (存储对象的)
3. key-list (允许重复,存取有序,有下标.)
4. key-set (不允许重复,存取无序,无下标.)
5. key-zset|sortedSet (不允许重复,根据score分数排序,无下标.)
四. Redis的常用命令.
1. key.
1. keys (返回Redis中所有满足要求的key,慎用.)
keys pattern (* , abc* , *xyz)
2. exists (判断key是否存在)
exists key (存在 - 1,不存在 - 0)
3. expire (设置key的生存时间)
expire key second
4. pexpire (设置key的生存时间)
pexpire key millisecond
5. ttl (查看具体key剩余的生存时间)
ttl key (key不存在 - -2,key没有设置生存时间 - -1 ,否则返回以秒为单位的剩余生存时间)
6. del (删除key)
del key [key ...]
2. string.
1. set (设置值)
set key value
2. get (取值)
get key
3. mset | mget (批量存值,批量取值)
mset key value [key value ...]
mget key [key ...]
4. incr (自增1)
incr key
5. decr (自减1)
decr key
6. incrby | decrby (自增|自减数值)
incrby key increment
decrby key increment
7. setex (设置值的同时,指定生存时间) 最佳实现 -> 设置值的同时,基于生存时间.
setex key second value
8. setnx (not exists,如果当指定的key不存在时,再正常的set设置值,如果key存在,什么都不干.)
setnx key value (在后续的分布式锁中,起着至关重要的作用.)
9. append (在key对应的字符串尾部追加值)
append key value
10. strlen (查看字符串长度)
strlen key
Ps: incr和decr命令只能针对value为数值的进行操作.
如果不是数值,会抛出异常. (error) ERR value is not an integer or out of range
3. hash.
#1. hset (设置值)
hset key field value
#2. hget (取值)
hget key field
#3. hmset | hmget (批量存取数据)
hmset key field value [field value ...]
hmget key field [field ...]
#4. hsetnx (和setnx大同小异.)
hsetnx key field value
#5. hincrby (自增指定数值)
hincrby key field increment
#6. hexists (判断field是否存在.存在返回1,不存在返回0)
hexists key field
#7. hdel (删除指定的field)
hdel key field
#8. hvals (返回全部的field对应的value)
hvals key
#9. hkeys (返回全部的field)
hkeys key
#10. hgetall (返回全部的field和value)
hgetall key
#11. hlen (返回field的数量)
hlen key
4. list.
#1. lpush | rpush (存值,从左侧插入数据,从右侧插入数据)
lpush key value1 value2 [...]
rpush key value1 value2 [...]
#2. lrange (通过索引获取数据,如果start为0,end为-1,代表获取全部数据)
lrange key start end
#3. lpop | rpop (从左侧删除第一个值,并返回内容,从右侧删除第一个值,并返回内容,)
lpop key
rpop key
#4. lrem (删除list中的内容)
lrem key count value #(删除列表中前count个值为value的元素)
# (count > 0 ,从左侧开始删--count < 0,从右侧开始删除--count = 0,删除所有的value元素)
#5. llen (查看列表的长度)
llen key
5. set
#1. sadd (添加数据)
sadd key member [member ...]
#2. smembers (获取全部数据)
smembers key
#3. srem (删除数据)
srem key member [member ...]
#4. spop (随机弹出一个元素)
spop key
#5. sinter (取多个set集合的交集内容)
sinter key [key ...]
#6. sunion (取多个set集合的并集内容)
sunion key [key ...]
#7. sdiff (取多个set集合的差集)
sdiff key [key ...]
#8. scard (获取set集合中的元素个数)
scard key
#9. sismember (查看当前元素是否属于这个set集合)
sismember key member
6. zset
#1. zadd (添加数据,根据score进行具体内容的排序)
zadd key score member [score member ...]
#2. zrange (获取值,根据索引的范围去获取内容)
zrange key start stop [withscores]
#3. zrangescore (获取值,根据分数的范围去获取内容)
zrange key min max [withscores]
#4. zrem (从zset中删除一个元素)
zrem key member [member ...]
#5. zcount (根据分数区间,获取元素的数量)
zcount key min max
#6. zcard (获取当前集合中的全部内容)
zcard key
面试题:
ZSet的实现原理 - 跳表结构.
ZSet理论上可以存储40亿条数据.
5. 没有说到的命令,可以去文档查看.
http://doc.redisfans.com/
五. Java连接Redis.
1. Jedis连接Redis.
1. 创建Maven项目.
2. 导入依赖.
jedis
junit
3. 开始测试.
public class MyTest1 {
// Jedis客户端 - 命令是什么,方法就是什么
@Test
public void test(){
//1. 创建连接对象. 大家后续在阿里云安装Redis的话,一定一定一定要指定连接的密码. top
Jedis jedis = new Jedis("192.168.98.98",6379);
/*//2.1 基操.
jedis.set("name","张三");
System.out.println("OK!");*/
/*//2.2 存对象. (String)
User user = new User();
user.setName("王大拿");
user.setAge(33);
jedis.set("userString", JSON.toJSONString(user)); // 用Gson,fastJSON将User转换为json字符串存入.
System.out.println("OK!");*/
/*//2.3 取String类型数据,并反序列化
String json = jedis.get("userString");
User user = JSON.parseObject(json, User.class);
System.out.println(user);*/
//2.4 存对象. (byte[])
/*User user = new User();
user.setName("谢大脚");
user.setAge(22);
byte[] key = "userByte".getBytes();
byte[] value = SerializationUtils.serialize(user);
jedis.set(key,value); // 用序列化工具,将User对象转换为byte[]存入.
System.out.println("OK!");*/
//2.5 取对象. (byte[])
byte[] key = "userByte".getBytes();
byte[] value = jedis.get(key);
User user = (User) SerializationUtils.deserialize(value);
System.out.println(user);
//3. 释放资源.
jedis.close();
}
}
2. JedisPool操作.
// Jedis自带了连接池.
@Test
public void test2(){
//1. 创建Jedis的连接池.
JedisPool pool = new JedisPool("192.168.98.98",6379);
//2. 通过连接池获取连接对象.
Jedis jedis = pool.getResource();
//3. 操作
Set<String> keys = jedis.keys("*");
System.out.println(keys);
//4. 将连接对象返回给连接池.
jedis.close();
}
3. SpringBoot连接Redis.
SpringBoot官方提供了Redis的启动器 -> 即使用了Jedis,也使用了Lettuce.
1. 创建SpringBoot项目.
2. 导入依赖.
spring-boot-starter
spring-boot-starter-test
spring-boot-starter-data-redis
3. 编写配置文件.
spring:
redis:
host: 192.168.98.98
port: 6379
4. 测试.
只需要在Controller/Service注解注入RedisTemplate对象即可.
如果你只想存储String类型数据,可以在注入RedisTemplate.
如果不写泛型中的内容,那么他会将数据全部序列化后存储.
RedisTemplate对象.opsFor...();
string - Value
hash - Hash
list - List
....
二. Redis的其他配置.
1. AUTH.
连接Redis时需要密码校验.
1. 修改配置文件.
requirepass 密码
在使用redis-cli连接时,需要输入auth 密码后,才可以正常操作
2. 在第一次连接redis-cli时,指定连接密码.
CONFIG SET requirepass 密码
客户端连接带密码校验的Redis.
图形化界面连接时,需要指定auth才可以正常连接.
Jedis:
1. 输入正常命令前,先执行auth方法,再输入.(不推荐)
2. 创建连接池时,直接指定具体的密码.(推荐)
new JedisPool(new GenericObjectPoolConfig(),"192.168.98.98",6379,3000,"密码");
SpringBoot:
在yml配置文件中添加spring.redis.password=密码
2. Redis的事务.
Redis的一次事务操作,该成功的成功,该失败的还是失败.
Redis开始事务之后,会将你的一系列的操作全部放到一个队列中.
当执行事务-> 一个队列的全部操作开始有序执行,该成功的成功,该失败的还是失败.
当取消事务-> 一个队列的全部操作,都丢弃.
multi 开启事务
exec 执行事务
discard 取消事务
watch key [key ...] 在开启事务前,监听一个或多个key,如果在开启事务之后,监听的key被改变了,那么这个事务会自动取消.
unwatch 取消监听. (在提交事务,取消事务后,会自动执行取消监听)
3. Redis的持久化机制.
Redis提供了两种持久化的机制.
在Redis宕机后重新启动时,会加载持久化的本地文件.
RDB持久化机制(默认).
1. RDB持久化的文件是二进制的,传输时,是比较方便滴.
2. 什么时候RDB会执行持久化.
after 900 sec (15 min) if at least 1 key changed
在15分钟内,对一个key进行写操作.
after 300 sec (5 min) if at least 10 keys changed
在5分钟内,对10个key进行写操作.
after 60 sec if at least 10000 keys changed
在1分钟内,对10000个key进行写操作.
AOF持久化机制(默认关闭).
开机aof持久化: appendonly yes
1. AOF持久化的文件时普通的文本文件,可以看懂,传输的时候,不太方便.
2. AOF持久化的时机.
appendfsync always
每执行一个写操作,立即将操作持久化.
appendfsync everysec
每秒会将写操作内容进行持久化.
appendfsync no
代表由当前系统为数据进行持久化.
RDB和AOF是可以同时开启的,并且官方也推荐这种方式.
RDB和AOF是同时开启后,如果Redis宕机重启,优先加载AOF的持久化文件,如果没有AOF我就加载RDB.
RDB和AOF是同时开启后,RDB在执行持久化时,RDB中的数据文件会被AOF覆盖.
三. Redis的集群.
1. 单机版的Redis存在的问题.
1. 单点故障.
2. 读写效率存在瓶颈.
3. 存储数据的容量上也存在瓶颈.
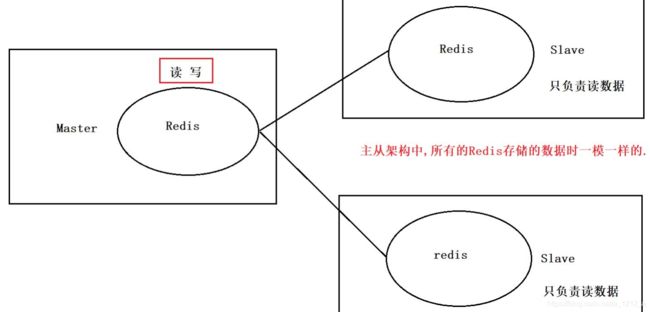
2. Redis的主从结构
主从结构帮我们解决了读写效率的问题.
问题:
1. 如果Master宕机了.主从架构基本也就崩了.
2. 存储数据的容量上限问题.
3. Redis的主从+哨兵.
主从+哨兵帮我们解决了之前主从架构存在的单点故障问题.当Master节点宕机后,哨兵会重新的选举出新的Master,来保证主从的正常执行.
问题:
存储数据的容量上限问题.

4. Redis的集群.

5. 搭建Redis集群.
5.1 准备docker-compose.yml文件.
version: '3.1'
services:
redis1:
image: daocloud.io/library/redis:5.0.4
container_name: redis1
environment:
- TZ=Asia/Shanghai
ports:
- 6379:6379
- 16379:16379
volumes:
- ./conf/redis1.conf:/usr/local/etc/redis/redis.conf
- ./data/:/data/
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis2:
image: daocloud.io/library/redis:5.0.4
container_name: redis2
environment:
- TZ=Asia/Shanghai
ports:
- 6380:6380
- 16380:16380
volumes:
- ./conf/redis2.conf:/usr/local/etc/redis/redis.conf
- ./data/:/data/
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis3:
image: daocloud.io/library/redis:5.0.4
container_name: redis3
environment:
- TZ=Asia/Shanghai
ports:
- 6381:6381
- 16381:16381
volumes:
- ./conf/redis3.conf:/usr/local/etc/redis/redis.conf
- ./data/:/data/
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis4:
image: daocloud.io/library/redis:5.0.4
container_name: redis4
environment:
- TZ=Asia/Shanghai
ports:
- 6382:6382
- 16382:16382
volumes:
- ./conf/redis4.conf:/usr/local/etc/redis/redis.conf
- ./data/:/data/
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis5:
image: daocloud.io/library/redis:5.0.4
container_name: redis5
environment:
- TZ=Asia/Shanghai
ports:
- 6383:6383
- 16383:16383
volumes:
- ./conf/redis5.conf:/usr/local/etc/redis/redis.conf
- ./data/:/data/
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis6:
image: daocloud.io/library/redis:5.0.4
container_name: redis6
environment:
- TZ=Asia/Shanghai
ports:
- 6384:6384
- 16384:16384
volumes:
- ./conf/redis6.conf:/usr/local/etc/redis/redis.conf
- ./data/:/data/
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
5.2 准备6份redis.conf的配置文件.
1. 注释bind 127.0.0.1
2. 关闭保护机制. protected-mode no
3. 开启集群模式. cluster-enabled yes
4. 指定集群文件的名称. cluster-config-file nodes-{端口号}.conf
bind 0.0.0.0
protected-mode no #关闭保护模式
port 6379 #绑定自定义端口 redis1:6379, redis2:6380 , redis3:6381 ..
cluster-enabled yes #开启集群
cluster-config-file nodes_6379.conf #集群的配置,配置文件首次启动自动生成,名字不一致即可.
cluster-announce-ip 192.168.98.98 #集群的 IP
cluster-announce-port 6379 #集群的端口 redis1:6379,redis2:6380,redis3:6381 .
cluster-announce-bus-port 16379 #集群的总线端口 redis1:16379,redis2:16380 ...
5.3 启动Redis集群.
docker-compose up -d
redis-cli --cluster create 192.168.98.98:6379 192.168.98.98:6380 192.168.98.98:6381 192.168.98.98:6382 192.168.98.98:6383 192.168.98.98:6384 --cluster-replicas 1
6. Java连接Redis集群.
6.1 Jedis连接.
@Test
public void test(){
Set<HostAndPort> nodes = new HashSet<>();
HostAndPort h1 = new HostAndPort("192.168.98.98",6379);
HostAndPort h2 = new HostAndPort("192.168.98.98",6380);
HostAndPort h3 = new HostAndPort("192.168.98.98",6381);
HostAndPort h4 = new HostAndPort("192.168.98.98",6382);
HostAndPort h5 = new HostAndPort("192.168.98.98",6383);
HostAndPort h6 = new HostAndPort("192.168.98.98",6384);
nodes.add(h1);
nodes.add(h2);
nodes.add(h3);
nodes.add(h4);
nodes.add(h5);
nodes.add(h6);
JedisCluster jedisCluster = new JedisCluster(nodes);
String a = jedisCluster.get("a");
System.out.println(a);
}
6.2 SpringBoot连接.
编写配置文件:
spring:
redis:
cluster:
nodes: 192.168.98.98:3679,192.168.98.98:6380,192.168.98.98:6381,192.168.98.98:6382,192.168.98.98:6383,192.168.98.98:6384
照常使用@Autowired注入RedisTemplate实例.
四. Redis的面试题.
1. 问题1:
如果Redis的key设置的生存时间到了,会立即删除吗??
答: 不会.
原因: Redis提供了过期策略.
1. 定期删除:
Redis会每隔一段时间,去Redis中随机获取几个设置了生存时间的key,如果发现已经过期,直接删除,如果没过期,什么事都不做. 100ms获取3个key.
2. 惰性删除:
当用户在获取一个已经超过生存时间的key时,Redis会先检查是否过期,如果过期直接删除当前key,并返回一个空值.
2. 问题2:
Redis的机制无法及时的删除掉全部的已经过期的key,会导致内存中有大量的过期数据存放,可能导致内存溢出问题,怎么解决?
答: Redis有淘汰机制.
1. noeviction: (默认策略)
当内存不足时,直接报错. (肯定不用)
2. allkeys-lru:
当内存不足时,在全部的key中移除最近最少使用的key(lru算法).
3. volatile-lru:
当内存不足时,在设置了过期时间的key中移除最近最少使用的key(lru算法).
4. allkeys-random:
当内存不足时,在全部的key中随机干掉一个key.
5. volatile-random:
当内存不足时,在设置了过期时间的key中随机干掉一个key.
6. volatile-ttl:
当内存不足时,优先干掉剩余生存时间最短的key.
7. allkeys-lfu:
当内存不足时,在全部的key中移除最近最少频次使用的key(lfu算法).
8. volatile-lfu
当内存不足时,在设置了过期时间的key中移除最近最少频次使用的key(lfu算法).
在配置文件中可以设置
maxmemory # 指定Redis的最大内存
maxmemory-policy noeviction # 指定Redis的淘汰机制
3. 问题3:
-
缓存穿透.
理想中缓存的实现方式.
请求 -> 先去缓存查询 -> 再去数据库查询 -> 放到缓存一份.
请求 -> 先去缓存查询.
缓存穿透: 缓存中没有,数据库中也没有.导致数据库压力过大,直接宕机.
解决方案:
主键自增
-> 查询最大的主键值,放到Redis里,每次去数据库查询之前,先判断一下传条件是否大于你的主键值.
-> 将全部的主键放到Redis的set中,在查询之前,先判断查询条件是否存在于set中.
-> 将用户的ip放到zset中,每查询一次,将时间戳放入zset中,1分钟发起了很多次请求,超过了要求上线,封ip. -
缓存击穿: 数据库里有,缓存里有,是一个热点数据,但缓存中的数据突然到期了,大量的请求同时查询了数据库,导致数据库宕机.
解决方案: 让一分部人去查询数据库放到缓存就ok了,分布式锁、传统的锁. -
缓存雪崩: 大量的缓存同时到期,导致数据库宕机.
缓存预热: 在服务启动时,直接将访问量高的数据直接放到缓存中.
解决方案: 在设置生存时间时,避免设置为相同的时间,给一个范围的值. -
缓存倾斜: 大量的热点数据都存放到了一个Redis节点中,导致Redis宕机.
解决方案:
在web 服务器中添加JVM缓存(Map),设置5s生存时间.
将热点数据的key在web 服务器中做一次hash计算,并将一个数据设置到多个Redis节点中,并分担压力.
在集群上搭建主从. -
缓存同步:将数据库中的数据同步到缓存中:
实时同步: 在操作数据库成功后,直接调用set方法.
不要求实时同步: 发送到MQ中.