Python网络爬虫与信息提取学习
本文基于《Python网络爬虫与信息提取》的学习,参考资料源于“Python网络爬虫与信息提取 北京理工大学:嵩天”,视频链接如下:
学习视频
(学习视频的课程排序不太准确,注意先看某节的简介/介绍,再看内容,最后看总结,【可以参考本文目录顺序】)
视频嵩老师使用python自带的IDLE,而本博客作者使用IDE为pycharm,因此在交互式部分的代码会有出入
导入——课程全局
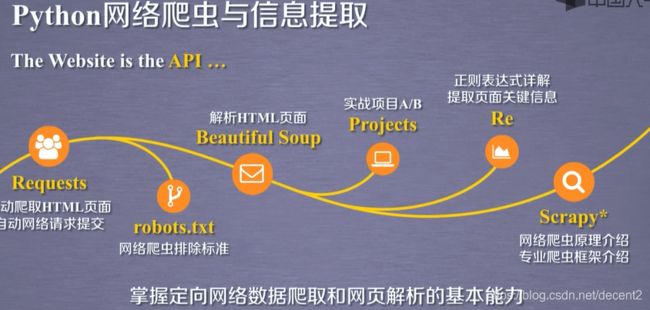
单元一 Requests库入门
1、HTTP协议及Requests库方法(SHD)
(1)HTTP协议
HTTP,Hypertext Transfer Protocol,超文本传输协议,是一个基于“请求与响应”模式的、无状态的应用层协议,并采用URL(统一资源定位符)作为定位网络资源的标识。
URL格式 > http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省(默认)端口为80
path:请求资源的路径
HTTP URL的理解:
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
HTTP协议对资源的操作:
| 方法 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应消息报告,即获取该资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL位置的资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置存储的资源 |
理解PATCH和PUT的区别
假设URL位置有一组数据UserInfo,包括UserID、UserName等20个字段。
需求:用户修改了UserName,其他不变。
采取PATCH,仅向URL提交UserName的局部更新请求
采取PUT,必须将所有20个字段一并提交到URL,未提交字段被删除
PATCH的最主要好处:节省网络宽带
(2)Requests库的7个主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST方法 |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests…delete() | 向HTML页面提交删除请求,对应于HTTP的DELETE |
对比我们可以看到,HTTP协议与Requests对资源操作一一对应。
下面就Requests中的部分方法进行操作:
import requests
r = requests.head("http://httpbin.org/get")
print(r.headers)
{‘Date’: ‘Fri, 03 Jul 2020 11:09:50 GMT’, ‘Content-Type’: ‘application/json’, ‘Content-Length’: ‘307’, ‘Connection’: ‘keep-alive’, ‘Server’: ‘gunicorn/19.9.0’, ‘Access-Control-Allow-Origin’: ‘*’, ‘Access-Control-Allow-Credentials’: ‘true’}
Requests库的post()方法
import requests
payload = {
"key1" : "value1",
"key2" : "value2"
}
r = requests.post("http://httpbin.org/post", data=payload)
print(r.text)

可以看到,使用post()方法向URL提交一个字典时,网页自动编码到form(表单)中
import requests
r = requests.post("http://httpbin.org/post", data="ABC")
print(r.text)
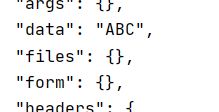
可以看到,使用post()方法向URL提交一个字符串时,网页自动编码到data中
Requests库的post()方法
import requests
payload = {
"key1" : "value1",
"key2" : "value2"
}
r = requests.put("http://httpbin.org/post", data=payload)
print(r.text)

向URL发送post请求,相当于传递新增数据,而put还会覆盖原有数据。当然,在一些URL中,POST和PUT方法也会不被允许使用,上述例子在我访问的时候已经不被运行使用了。上述例子主要是为了了解使用这些方法后,URL会如何处理这些数据。
2、Requests的get方法
(1)get方法
首先使用get方法发出请求
requests.get(yrl, params = None, **kwargs)
url:拟获取页面的url链接
params:url中的额外参数,字典或字节流格式,可选
**kwargs:12个控制访问的参数
(2)Requests库的2个对象
注意Requests库的2个重要对象,我们不仅要发出请求,还要得到响应

(3)Response响应
下列就是我们调用响应的方法:
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回请求状态码 |
| r.text | HTTP响应页面内容的字符串形式 |
| r.encoding | 从HTTP header中猜猜的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
下面我们就访问b站首页并获取响应内容
import requests
r = requests.get("https://www.bilibili.com/")
print(r.status_code)
print(type(r))
print(r.headers)

下面就是一些常见的状态码以及对应的含义:

那么使用request访问基本流程就是这样的:

对于响应内容的编码类型,有两种获取方式,r.encoding是根据HTTP头文件中是否存在charset来判断,而r.apparent_encoding是就返回内容分析,因此从后者中可以更准确了解响应内容的编码格式。
r.encoding : 如果header中不存在charset,则认为编码为ISO-8859-1
r.apparent_encoding : 根据网页内容分析出的编码方式
import requests
r = requests.get("https://www.baidu.com/")
print(r.encoding)
print(r.apparent_encoding)
ISO-8859-1
utf-8
这样就可以便于我们去解析响应内容,如果直接返回原格式相应内容:

下面我们修改解析方式
import requests
r = requests.get("https://www.baidu.com/")
r.encoding = "utf-8"
print(r.text)
这样可以解析中文,使得人眼可读性提高

3、Rquests库主要方法解析
(1)requests库的request方法
requests.request(method, url, **kwargs)
method : 请求方式,对应get / put / post / put / patch / delete / options 7种
url : 拟获取页面的url链接
**kwargs : 控制访问参数,共13个
(2)request方法的13个控制参数
下面介绍 13个访问的控制参数:
| 参数 | 用途 |
|---|---|
| params | 字典或字节序列,作为参数增加到url中 |
| data | 字典、字节序列或文件对象,作为Request的内容 |
| json | Json格式的数据,作为Request的内容 |
| headers | 字典,HTTP定制头 |
| cookies | 字典或者CookieJar,Request中的cookie |
| auth | 元组,支持HTTP认证功能 |
| files | 字典类型,传输文件 |
| timeout | 设定超时时间,单位为秒 |
| proxies | 字典类型,设定访问代理服务器,可以增加登录认证 |
| allow_redirects | True/False,默认为True,重定向开关 |
| stream | True/False,默认为True,获取内容立即下载开关 |
| verify | True/False,默认为True,认证SSL证书开关 |
| cert | 本地SSL证书路径 |
SSL 证书就是遵守 SSL协议,由受信任的数字证书颁发机构CA,在验证服务器身份后颁发,具有服务器身份验证和数据传输加密功能。
(3)requests库的其他方法
下面介绍requests的其他方法:
其中,url : 拟获取页面的url链接, **kwargs : 13个访问参数
在下列这些方法中,有些参数是必须指定的,那么13个参数中剩余的参数就作为自定义参数
requests.head(url, **kwargs)
requests.post(url, data = None, json = None, **kwargs)
requests.put(url, data = None, **kwargs)
requests.patch(url, data = None, **kwargs)
requests.delete(url, **kwarg)
对于requests库中所有方法,最常用的就是request、get和head三个方法。在我们访问时,可以通过请求传递信息,这些信息就可能导致网络安全性问题,因此上面其他的几个方法很有可能就不被允许使用。
单元小结
以上介绍了requests库的方法,在使用时最多的就是request、get和head。同时,我们还需要认识到——“网络链接有风险,异常处理很重要!”下面就介绍如何处理异常:
首先了解一下requests的异常:
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
| r.raise_for_status() | 如果不是200,产生异常requests.HTTPError |
import requests
try:
#尝试去运行
r = requests.get("https://www.baidu.com/")
r.raise_for_status()
#判断响应状态码是否为200,如果不是200,它就会产生一个HttpError的异常
r.encoding = "utf-8"
print(r.text)
except:
print("产生异常")
由此我们获得一个通用框架:
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()#如果状态码不是200,触发HTTPError异常
r.encoding = "utf-8"
return r.text
except:
return "产生异常"
if __name__=="__main__":
url = "https://www.bilibili.com/"
print(getHTMLText(url))
单元二 网络爬虫“盗亦有道”
1、Robots协议
Robots Exclusion Standard网络爬虫排除标准
作用:网站告知网络爬虫哪些页面可以访问,哪些不行
形式:网站根目录下的robots.txt文件
如何找到robots.txt文件:直接在网址后面加上“/robots.txxt”

在上面的robots文件中,作出以下规定:
Allow规定以其后开头的URL是允许robot访问的,Disallow规定以其后开头的URL是不允许访问的,这里的User-agent(用户代理)指明了爬虫的引擎。在协议的后面,例如最后一个,表明了:禁止该搜索引擎访问网站的任何部分。
当然,并不是所有网站都会有robots协议,如果没有这个协议,默认是允许所有用户访问任意部分。
2、对robots协议理解

无论我们爬取什么数据,网络爬虫都应该遵守robots协议。
3、网络爬虫的约束
(1)网络爬虫的大小

(2)网络爬虫带来的问题
网络爬虫会带来很多问题,主要是下面三类:
1、网络爬虫的骚扰
受限于编写水平和目的,网络爬虫将会给web服务器带来巨大的资源开销
2、网络爬虫的法律风险
服务器上数据有产权归属
网络爬虫获取数据后牟利将带来法律风险
3、网络爬虫泄露隐私
网络爬行可能具备突破简单访问控制的能力,获取被保护数据从而泄露个人隐私
因此网页维护者会采取来源审查和发布公告两种方式来限制网络爬虫。
(3)网站维护者的约束方式
1、来源审查:判断User-Agent进行判断
2、发布公告:Robots协议
除了Robots协议之外,我们在使用爬虫时还需要进行自我约束,过于快速或者频密的网络爬虫都会对服务器产生巨大的压力,可能引起网站封锁你的访问ID,甚至采取进一步的法律行动。因此,在使用爬虫时,需要对请求速度进行合适的调整。
单元三 Requests库的5个实例
1、爬取京东商品页面
浏览商品信息

import requests
r = requests.get("https://item.jd.com/12441345483.html")
print(r.status_code)
print(r.encoding)
利用get方法获取网络链接状态码和网页编码类型
200
UTF-8
然后使用r.text打印内容,当然,这里需要登陆,这就需要提交一组账户密码组织键值对对象给网页,或者事先登录(这里就自己动手吧)。
2、爬取亚马逊商品页面
(1)实例操作

这是课程中出现的问题,亚马逊网站直接拒绝我们的请求,因为我们发出的请求头很坦诚的告诉亚马逊网站自己是python发出的,因此我们需要对请求进行处理。(当然,由于时差影响,我访问的时候并没有被拒绝)
下面介绍定制请求头,
import requests
b = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)" \
" Chrome/85.0.4170.0 Safari/537.36 Edg/85.0.552.1"
}
url = "https://www.amazon.cn/dp/B013JV3G2K/ref=sr_1_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E"\
"7%BD%91%E7%AB%99&crid=3DYCPY7I9J9S7&keywords=%E9%B2%81%E8%BF%85%E5%85%A8%E9%9B%86&qid=1"\
"593834844&sprefix=%E9%B2%81%E8%BF%85%2Caps%2C173&sr=8-1"
r = requests.get(url,headers = b)
print(r.text)
(2)方法:定制请求头
这个user-agent是指用户代理,下面我们介绍如何定制请求头:
请求头Headers提供了关于请求、响应或其他发送实体的信息。对于爬虫而言,请求头十分重要,尽管上述示例没有指定请求头。如果没有指定请求头或者请求的请求头和实际网页不一致,就可能无法返回正确是结果。
requests并不会基于定制的请求头Headers的具体情况改变自己的行为,只是在最后的请求中,所有的请求头信息都会被传递进去。
下面介绍如何找到Headers:
1、使用浏览器的检查(开发者模式)
2、打开网络(Network),刷新页面,找到需要请求的页面
3、单击请求的页面(如果只是找用户代理,可任意选取一个)
4、在标头下面找到“请求标头”,就可以看到用户代理

3、向百度提交关键词
百度关键词接口:
http://www.baidu.com/s?wd= keyword
import requests
a = {"wd":"Python"}#创建一个键值对用作提交对象
r = requests.get("http://www.baidu.com/s", params= a)
print(r.status_code)
print(r.request.url)
print(len(r.text))
200
http://www.baidu.com/s?wd=Python
349937
查看字符串长度我们就可以看到响应的内容非常多,就不必将其打印。类似的,这里直接给出360搜索实例
4、网络爬取图片及存储
网络图片链接格式:http://www.example.com/picture.jpg

path:存储路径
5、IP地址归属地的自动查询
原理:利用URL接口,向网页提交一个IP地址
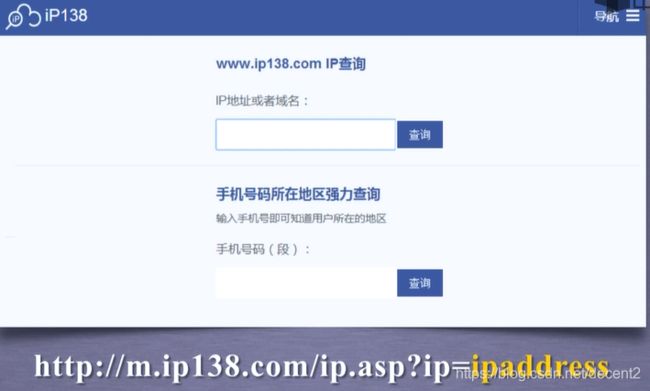
http://m.ip138.com/ip.asp?ip= ipaddress

单元四 Beautiful Soup库入门
1、Beautiful Soup库的基本元素
(1)Beautiful Soup库的理解
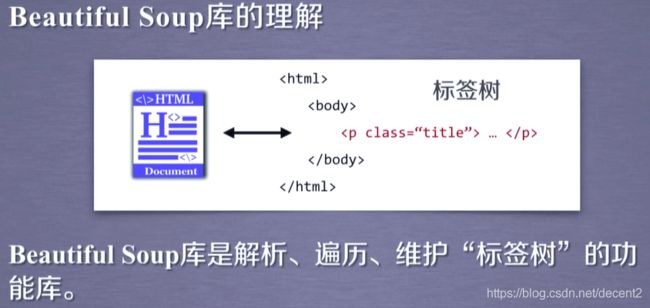
(2)Beautiful Soup库的引用
Beautiful Soup库,也叫beautifulsoup4或bs4
注意Beautiful Soup中大小写
Beautiful Soup类就是bs4中的一个类


(3)Beautiful Soup库解析器

上面就是使用HTML解析器


这些将在接下来的内容将。
2、基于bs4库的HTML格式化和编码
下面看一下HTML解析样式:
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.bilibili.com/")
soup = BeautifulSoup(r.text,"html.parser")
b = soup.prettify()
print(b)

3、基于bs4库的HTML内容遍历方法
(1)HTML基本格式
HTML的基本格式就是成对的标签
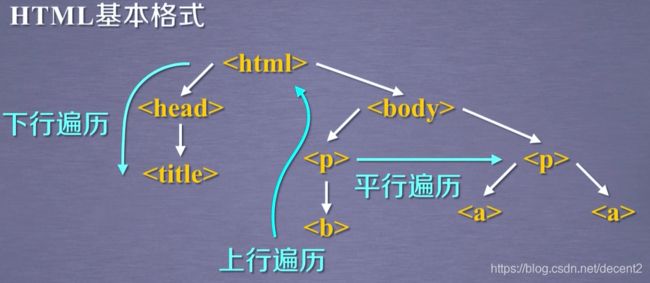
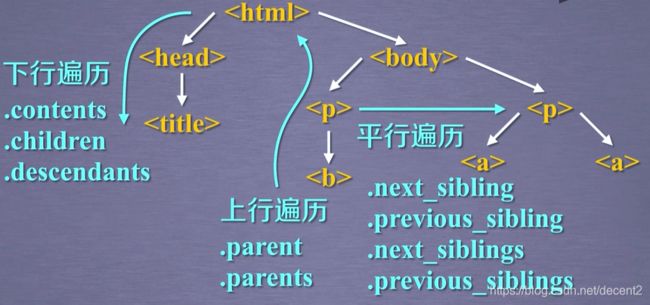
(2)标签树的三种遍历方式
<1>下行遍历

import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.bilibili.com/")
soup = BeautifulSoup(r.text,"html.parser")
b = soup.head
print(b)
c = b.contents
print(c)
要想达到遍历,利用循环即可

<2>上行遍历


<3>平行遍历

需要注意,平行遍历发生在同一父节点的各节点间,同时,我们不能直接认为平行遍历返回的下一个节点就是标签类型。


<4>总结
注意,如果遍历中使用的方法需要迭代,那么就只能用for循环来完成遍历。
单元五 信息组织与提取方法
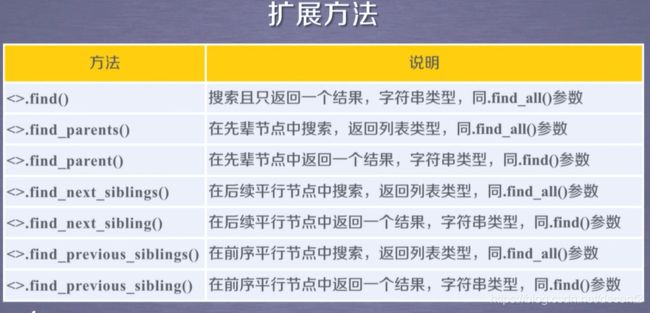
1、基于bs4库的HTML内容查找方法
(1)<>.find_all方法

import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.bilibili.com/")
soup = BeautifulSoup(r.text,"html.parser")
for tag in soup.find_all(True):#显示suop所有标签头
print(tag.name)

(2)其他方法
2、三种信息标记形式
(1)三种信息标记形式介绍与实例

实例:



(2)三种信息标记形式的比较


3、信息标记的三种形式
(1)信息标记

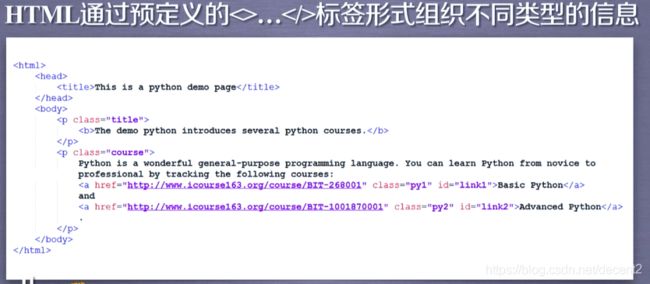
(2)HTML信息标记

(3)XML信息标记
XML就是由HTML发展来的通用信息标记形式


(4)JSON信息标记

注意,组织信息时,键值对都需要双引号包裹,只有值为数值可以不用。
(5)YAML信息标记

4、信息提取的一般方法
(1)信息标记的两种方法及混用



(2)实例


实例1:中国大学排名爬取
(1)实例介绍

(2)功能描述

(3)网页分析
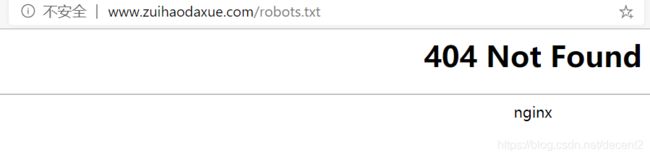
以最好大学网为例:
http://www.zuihaodaxue.com/zuihaodaxuepaiming2020.html
首先查看该网页的robots协议,返现该网页不存在,也就是无限制:
接下来我们简要分析定向的可行性,找到我们想要获取的内容:
1、使用浏览器的检查
2、查看网络,使用搜索,输入关键字“清华”,找到其所在位置

我们可以看到旁边的行数,确定其在源代码中的位置,接下来找到其在源代码中所处的位置:
可以看到其在中的中的中

在源代码页面可以使用快捷键ctrl+f,可以调出搜索框,也可以通过这种方式进行查到位置
(4)结构设计

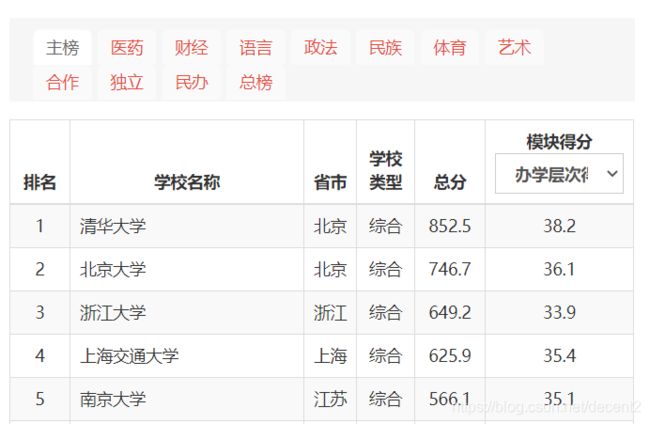
我们可以看到这些内容是二维数据,可以用列表进行存储

(5)实例代码
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
#将url信息爬取,将其中html页面返回
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = "utf-8"
return r.text
except:
return "访问异常"
def fullUnivList(ulist, html):
#提取html中关键数据并存储
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find("tbody").children:
#获取下所有子类
if isinstance(tr, bs4.element.Tag):
#检验 标签下内容的类型是否为bs4库定义的Tag类型,否,则直接过滤
tds = tr("td")
#所有 已经解析,下面就需要接受其下的中的内容
ulist.append([tds[0].string, tds[1].string, tds[2].string])
#将获取的内容
def printUnivList(ulist, num):
print("{:^6}\t{:^10}\t{:^6}".format("排名","学校名称","总分"))
#这里对输出格式进行规定,{:^6}表示取6位正中对齐,\t添加一个制表符,详情下面附有链接
for i in range(num):
u = ulist[i]
print("{:^6}\t{:^10}\t{:^6}".format(u[0], u[1], u[2]))
def main():
unifo = []
url1 = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2020.html"
html = getHTMLText(url1)
fullUnivList(unifo, html)
printUnivList(unifo, 20)
main()
下面就是输出的结果:

(6)实例优化:中文对齐问题

关于.format的用法 .
我们可以看到上面结果,中文并不是完全居中对齐,当中文不够,系统会用西文字符填充,而中西文的空格占位不同,这就会导致中文对齐问题
解决方法:
采用中文字符的空格填充chr(12288)
def printUnivList(ulist, num):
tplt = "{0:^6}\t{1:^10}\t{2:^6}"
#制定输出规则
print(tplt.format("排名","学校名称","总分",chr(12288)))#替换
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2]))
单元六 Re(正则表达式)库入门
1、正则表达式的概念
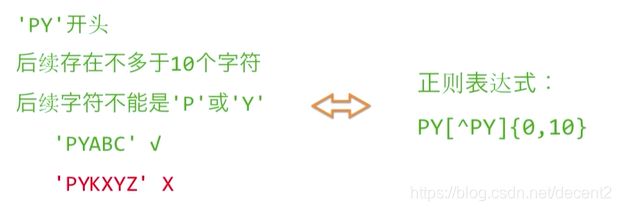
(1)正则表达式概念及实例


(2)正则表达式功能
由上述例子,我们可以看出正则表达式可以将一段复杂的内容简洁地表达,除此之外,正则表达式还具有以下功能:


(3)正则表达式的主要用途
正则表达式常用在字符串匹配,在使用正则表达式时,我们需要进行编译,

2、正则表达式的语法
(1)基本语法

(2)常用操作符

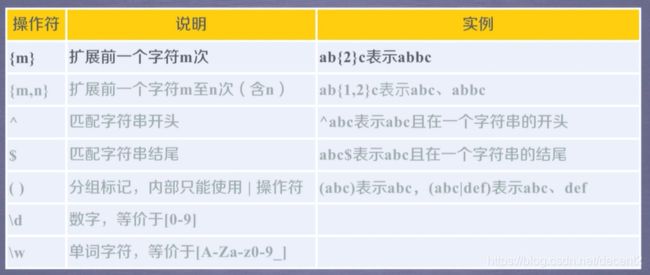
注意:{ }的扩展只针对其前的一个字符
(3)语法实例

这里的第一个实例,其效果和去掉 ? 一样,这里涉及最小匹配,将在后面解释
import re
a = "pyyn"
m = re.search(r"p(y|yt|yth|ytho)n",a)
n = re.search(r"p(y|yt|yth|ytho)?n",a)
print(m,"\n",n)
返回结果都是None
(4)经典实例


3、Re库的基本使用
(1)正则表达式的表示类型


原生字符串就是在字符串前面加一个“r”,注意,原生字符串中不包含转义字符,因此在使用正则表达式需要用到转义字符时,最好使用原生字符串。
(2)Re库的6个主要功能函数

下面就一一解释:



import re
a = "pyn"
m = re.search(r"p(y|yt|yth|ytho)n",a)
print(m)
print(m.group())
pyn
可以看到,这里调用.group直接输出匹配结果,但是要注意一点,如果没有匹配到结果,那么就会返回空值,此时用group就会返回异常,因此在使用时,为了避免错误,就需要处理异常。


这个函数是将匹配到的结果去掉,返回一个列表,可使用maxsplit参数进行分割
import re
m = re.split(r"[1-9]\d{4}","cmf10086 dli10084")
n = re.split(r"[1-9]\d{4}","cmf10086 dli10084",maxsplit=1)
print(m)
print(n)
[‘cmf’, ’ dli’, ‘’]
[‘cmf’, ’ dli10084’]

注意,这个函数在引用时需要用for循环操作
import re
for m in re.finditer(r"[1-9]\d{4}","cmf10086 dli10084"):
if m:
print(m.group(0))
10086
10084

(3)面向对象的调用方法
我们还可以将对象单独存储,这样我们就可以重复调用已知对象并重复操作

我们还可以将正则表达式编译成正则表达式对象,这样就可以重复调用这样正则表达式,那么在使用时,就不需要再规定pattern和flags这两个参数了。


4、Re库的Match对象
(1)Macth对象的属性

(2)Macth对象的方法

(3)Re库的贪婪匹配和最小匹配



实例2 某宝商品比价定向爬虫(略)
本文不涉及该部分,完成此内容需要获取登录接口链接并验证身份
实例3 股票数据定向爬虫(略)
单元七 Scrapy爬虫框架
1、Scrapy爬虫框架介绍
(1)爬虫框架

(2)Scrapy爬虫框架图示
Scrapy爬虫框架有7个模块

其中,engine、downloader、scheduler(调度器)是已有的,用户需要编写spiders、item pipelines(配置)模块。
(3)Scrapy爬虫框架解析
Engine>>>
控制所有模块之间的数据流
根据条件触发事件
Downloader>>>
根据请求下载网页
Scheduler>>>
对所有爬虫请求进行调度
这三者是不需要用户进行修改,但是这三者间有一个中间键,用于用户可控制的配置:

Spider>>>
解析Downloader返回的响应(Reponse)
产生爬取项(scraped item)
产生额外的爬取请求(Request)
Item Pipelines>>>
以流水线方式处理Spider产生的爬取项
由一组操作顺序组成,类似流水线,每个操作是一个Item Pipelines类型
可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库
这两个模块需要用户进行编写,另外,这这两者之间还有一个中间键:

2、Scrapy爬虫的常用命令
(1)Scrapy命令行格式

(2)Scrapy常用命令
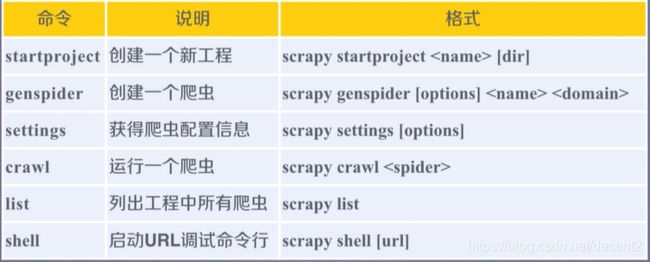
(2)Scrapy爬虫命令行逻辑

3、requests库和Scrapy爬虫的比较
(1)相同点

(2)不同点
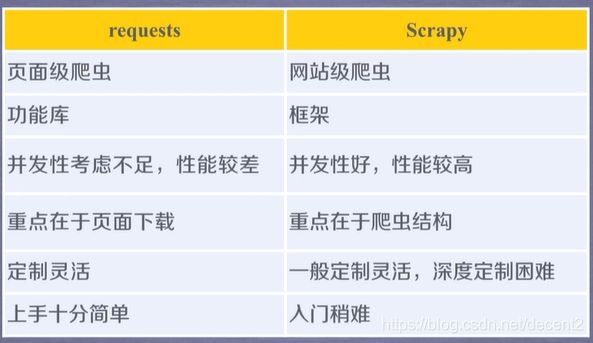
(3)选取建议

单元八 Scrapy爬虫的基本使用
1、使用介绍
(1)使用步骤
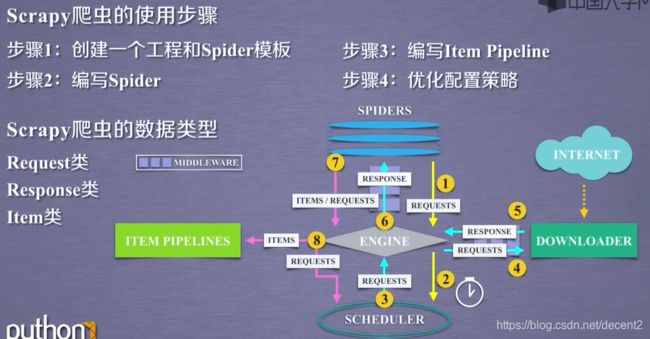
(2) Scrapy爬虫的三种数据类型

request类主要的属性或方法:


response类主要的属性和方法:


(2) Scrapy爬虫提取信息的方法
Scrapy爬虫支持多种HTML提取信息的方法:
Beatuiful Soup
lxml
re
Xpath Selector
CSS Selector
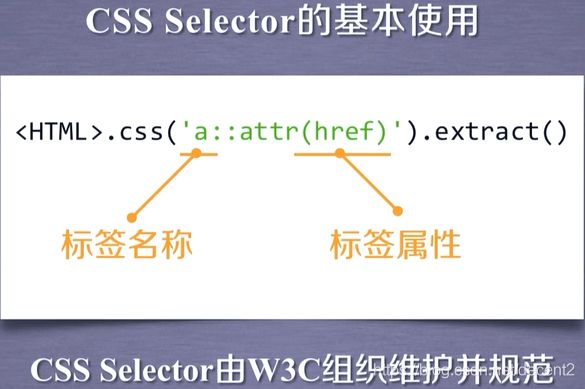
2、yield关键字的使用
(1)生成器

(2)实例
输出小于n的数的平方数
def gen(n):
for i in range(n):
yield i**2
for i in gen(5):
print(i)
for i in gen(6):
print(i," ",end="")
0
1
4
9
16
0 1 4 9 16 25
另外,我们还可以找到取值范围,定义一个列表返回这些数值,然后直接使用平方函数求值即可。
既然有可以直接求,为什么还需要生成器?
(3)生成器的优势
生成器相比于一次性列出所有可能的优势
1、节省存储空间
2、响应更迅速
3、使用更灵活
当上述实例取n=1M,那么我们还需要定义一个包含0-1M的列表。在爬虫使用时,我们可能需要访问很多内容时,我们就可以使用生成器,
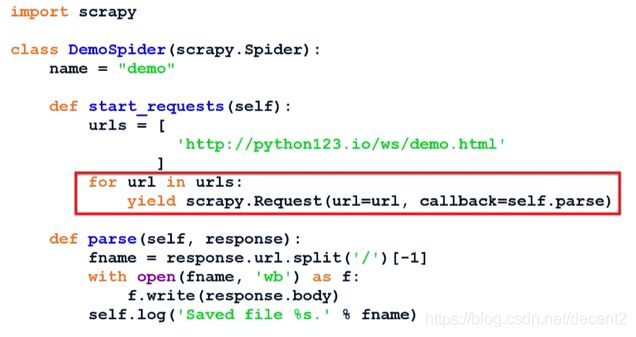
3、简单实例
演示网址
http://python123.io/ws/demo.html
文件名:demo.html
(1)建立一个Scrapy爬虫工程(pycharm)
博主使用的是pycharm,下面就介绍,使用pycharm的Terminal终端创建一个Scrapy项目
先试试第二行直接创建,如果没有成功,再执行第一行步骤
( File -> Setting -> Tools -> Shell path -> 将其修改成本机的cmd位置)
Terminal >>> scrapy startproject ____【name】
Terminal终端的位置如图所示:(pycharm左下角)
看到如下信息即为创建成功:
New Scrapy project 'test_scrapy', using template directory 'e:\\Anaconda3\\lib\\site-packages\\scrapy\\templates\\project', created in:
G:\PycharmProjects\scrapy\test_scrapy
You can start your first spider with:
cd test_scrapy
scrapy genspider example example.com
工程目录


(2)生成一个爬虫
依然是在Terminal终端完成
>cd getdemo #在当前工程下执行你的工程(getdemo即为我的工程名)
>getdemo>scrapy genspider demo python123.io
#给定名称和爬取网址
结果如下:
Created spider ‘demo’ using template ‘basic’ in module:
getdemo.spiders.demo
在getdemo的工程下生成了一个爬虫,名为demo
当然,我们还可以手动生成,下面我们看一下这个爬虫的内容
import scrapy
class DemoSpider(scrapy.Spider): #scrapy.Spider的子类
name = 'demo'
allowed_domains = ['python123.io'] #指定爬虫爬取的网址,只能爬取这个域名以下的链接
start_urls = ['http://python123.io/'] #需要爬取页面的初始内容
def parse(self, response): #解析页面的空方法,parse()用于处理响应,解析内容形成字典,发现新的url爬取请求
pass
(3)配置产生的爬虫
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
start_urls = ["https://python123.io/ws/demo.html"]
def parse(self, response):
fname = response.url.split("/")[-1] #从响应的url中提取文件名作为保存本地的文件名
with open(fname, "wb") as f: #将保存的内容存储
f.write(response.body)
self.log("Saved file %s." % fname)
(4)运行爬虫获取网页
>cd getdemo #调用getdemo
>\getdemo>scrapy crawl demo #使用crawl命令执行demo
2020-07-06 22:47:48 [scrapy.core.engine] INFO: Spider closed (finished)
最后就可以在看到getdemo的子目录中看到这个html文件
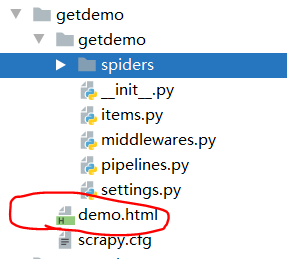
(5)爬虫文件


可以看到,完整版本的爬虫文件中使用了生成器,当需要访问的url很多时,这是就需要考虑使用生成器了。
实例四 股票数据Scrapy爬虫
实例涉及到百度股票(已下架),只拓展Pipelines的编写
配置 Pipelines.py文件
通过配置文件,让框架找到我们新定义的类,并且用这个类处理Item提出的相关信息;
同时,我们话可以继续定义对爬取项(Scraped Item)的处理类以及其他函数,完善其功能;
最后,我们找到ITEM_PIPELINES,并将我们定义类的注释效果去掉。
附页—— 开发工具选择
python开发工具可分为两类,如下:


python自带的IDLE包括交互式和文本式两种编译器

你可能感兴趣的:(python爬虫,python爬虫)