论文阅读笔记-CVPR 2020: Attentive Weights Generation for Few Shot Learning via Information Maximization
摘要
AWGIM:通过信息最大化实现小样本学习的注意力权重生成
论文的主要贡献有两个:
- 生成的权重与输入数据之间的互信息最大化
使得生成的权重能够保留小样本学习任务和特定查询样例的信息。 - 两条注意力路径:自我注意和交叉注意
对小样本学习任务的上下文和个性化查询进行编码
论文写作框架
- 简介
- 相关工作
2.1. 小样本学习
2.2. 注意力机制
2.3. 互信息 - 提出的方法
3.1. 问题的形式化定义
3.2. 潜在的特征向量优化
3.3. 权重生成的信息最大化
3.4. 注意力权重生成
3.4.1 上下文和注意力路径
3.4.2 权重生成器
3.5. 训练和预测
3.6. 复杂度分析 - 实验
4.1. 数据集和协议
4.2. 实现细节
4.3. 与其他方法的比较
4.4. 分析
4.5. 收敛
4.6. 预测时间花费 - 结论
1. 简介
元学习是目前解决小样本学习问题的主流方法
元学习的种类有:
- 基于梯度的方法
- 基于测量的方法
- 权重生成方法,不但有效,而且计算公式简单。
权重生成是对不同的任务,在有限的带标签数据上生成分类权重。但是,固定的分类权重,对不同的查询样例,可能不是最优的。
本文提出的新方法 AWGIM 就是为了解决这个问题。
AWGIM 在整个支持集和单个查询样例上,对分类权重的概率分布进行建模。
但是作者实验发现,查询样例和支持集之间的交叉注意所生成的分类权重,不足以用于不同的查询数据。尤其是某些特定的查询信息,在权重生成时,丢失了。
为了处理这个问题,作者利用互信息最大化,把查询/支持样例的信息保留在生成的权重中。
本文的贡献是:
- 通过最大化生成的权重与查询/支持数据之间的互信息,解决了小样本分类的权重生成问题。利用信息最大化,权重生成器生成的分类权重适用于多种多样的查询样例。
- 提出通过两条单独的路径,对任务上下文和单个查询样例进行编码。两条路径都利用注意力机制来捕获上下文信息。
- 通过大量实验发现, AWGIM 比最先进的方法还要好。作者还进行了详细分析,来验证 AWGIM 的每个组件的贡献。鉴于小样本分类问题的实际情况,该方法所导致的计算开销是最小的。自适应分类权重生成也使得模型收敛更快。
2. 相关工作
2.1. 小样本学习
解决小样本学习问题,目前最有效的方法是元学习,可分为以下几类:
- 基于梯度的方法,直接训练一个元学习器来优化给定的小样本分类问题。
- 基于测量的方法,学习查询样例和支持样例之间的相似度测量。
- 权重生成方法,直接生成分类权重。已有的研究,都没有考虑为不同的查询样例生成不同的权重,也没有最大化互信息。
- 还有一些其他的方法。生成更多数据。
2.2. 注意力机制
注意力机制在计算机视觉和NLP领域取得了巨大成功。从特定上下文建模查询( query )和键值对( key-value )之间的相互作用,注意力机制非常有效。
根据 query 和 key 是否为同一实体,注意力机制可分为两类:自我注意、交叉注意。
作者利用注意力机制,通过最大化互信息,来解决小样本分类问题。聚焦于对自我注意和交叉注意之间的相互作用进行建模。
2.3. 互信息
互信息广泛用于GAN、自监督学习。。。等。最近互信息被引入小样本学习,用于记忆问题的正则项。
作者利用互信息的可变下界,直接生成精确的权重,来解决小样本学习问题。
3. 提出的方法
3.1. 问题的形式化定义
小样本学习任务 T,采样自未知的任务分布 P(T)。 T 包括支持集 S 和查询集 Q。S 中的样例类别个数称为 N-way,每个类别的样例个数称为 K-shot。T 称为 N-way K-shot 任务。
![]()
S 共包含 NK 个带标签的样例,Q 包含若干无标签的样例 x ^ \hat x x^ ,小样本学习的任务是基于 S 预测 x ^ \hat x x^ 的标签 y ^ \hat y y^。接下来的讨论,分别用 ( x c n , y c n ) (x_{c_n}, y_{c_n}) (xcn,ycn) 、 ( x ^ , y ^ ) (\hat x, \hat y) (x^,y^) 代表支持样例和查询样例。
元学习,是在 Q 上评估模型的性能,而且元训练和元测试所用的样例类别是不同的,这就需要元学习模型学到可转移的横跨不同任务的高级知识,使自己快速适应全新的任务。
3.2. 潜在特征向量优化(LEO: Latent Embedding Optimization)
怎么形象理解 embedding 这个概念? 个人理解: embedding 就是特征向量。
LEO 是一种生成权重的方法,与本文的工作密切相关。LEO 通过学习一个低维的潜在空间,来避免更新高维的 w;从这个低维的潜在空间采样得到的 z 可用于生成 w。
AWGIM 与 LEO 有两个显著区别:
第一,LEO 依靠内部更新,生成的权重,只适合所输入的任务。AWGIM 是一个前馈网络,训练用来最大化互信息,目的是让其很好地适合各种不同的任务。
第二, AWGIM 学习为每个查询样例生成最佳分类权重。而 LEO 依靠某一任务的支持集,生成固定的权重。
3.3. 权重生成的信息最大化(从理论分析推理出目标函数)
作者的目标是为任意一个小样本学习任务生成分类权重,查询样例也是任务的一部分,LEO 生成的分类权重,对不同的查询样例不敏感。为了改善这个问题,可以对特定查询的信息进行编码,在生成权重时,习得模型 p ( w ∣ x ^ , S ) p(w|\hat x, S) p(w∣x^,S) 。
但实验发现, x ^ \hat x x^ 上的信息,在生成期间,可能会被忽略。为了处理这个局限性,作者提出最大化所生成的权重w与查询以及支持集之间的互信息。不失一般性,接下来的讨论,用 wi 表示类别 ci 的分类权重。目标函数可以描述为

根据互信息的链式法则,可得
![]()
式5 中的两项都遵循式6,因此目标函数可写为式 7
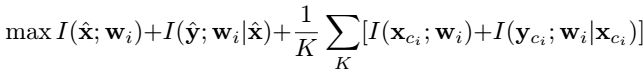
直接计算式7 中的互信息很难,因为真实后验分布仍然未知,例如 p ( y ^ ∣ x ^ , w i ) p(\hat y|\hat x,w_i) p(y^∣x^,wi) 和 p ( x ^ ∣ w i ) p(\hat x|w_i) p(x^∣wi) 。因此用可变信息最大化来计算式5 的下界,用 p θ ( x ^ ∣ w i ) p_θ(\hat x|w_i) pθ(x^∣wi) 来近似真实后验分布, θ 表示模型参数。结果有式 8

H(.) 是随机变量的熵,对于给定的数据, H ( x ^ ) H(\hat x) H(x^) 的值是常数。可以最大化这个下界,来代替真实互信息。与式8 同理有式 9
![]()
对支持集数据可进行同样的推理,把这个下界代入式7,为了清晰,忽略常数项和写在下面的期望值,得到新的目标函数 10

第一和第三项,是给定生成的分类权重时,最大化标签的 log 似然,包括支持集与查询集。这等价于最小化预测值和真实值之间的交叉熵。此外,假设 p θ ( x ^ ∣ w i ) p_θ(\hat x|w_i) pθ(x^∣wi) 和 p θ ( x c i ∣ w i ) p_θ(x_{c_i}|w_i) pθ(xci∣wi) 服从高斯分布,那么可以通过最小化 L2 重构损失,实现最大化log似然。
总之,利用互信息最大化,作者得到了一个由交叉熵损失和重构损失组成的目标函数。
3.4. 注意力权重生成(对整个模型的详细描述)
作者提出的方法框架,如下图所示

任务T 中的所有图片都是经过已有的特征提取器(可以是任一CNN)处理过的d维特征向量。有两条路径分别对任务的上下文和单个查询样例进行编码,称为上下文路径和注意力路径。这两条路径的输出被连接到一起,作为分类权重生成器的输入。所生成的分类权重,不但用于预测 x ^ \hat x x^ 的标签,而且用于最大化互信息的下界。
3.4.1 上下文路径和注意力路径
用注意力机制,是为了建模任务中所有样例之间的交互作用,作为任务的特有属性。为了这个目的,先前的工作是利用关系网络,而作者是用更先进的多头注意,因为其优势是从不同的表示子空间建模交互作用。
上下文路径的目标是只学习支持集的表征,用多头自我注意网络。其输出包含了关于任务的丰富的信息,可用于后面的权重生成。
![]()
现有的权重生成方法只是依靠支持集生成分类权重,但是用这种方式生成的分类权重可能不是最优的,对不同的查询样例缺乏必要的适应。作者通过引入注意力路径来处理这个问题,让单个查询样例注意任务的上下文,并用于生成分类权重。因此,这样的分类权重不但能够适应不同的查询样例,而且知道任务上下文。
注意力路径中,用新的多头自我注意网络,对支持集编码任务的全局信息。
![]()
上下文路径中的自我注意网络强调生成分类权重,而这里的自我注意网络充当的角色是,提供上下文的 Value,在接下来的交叉注意中,给不同的查询样例用来注意。在两个路径中,使用同一自我注意网络,可能会限制所学表征的表达。
交叉注意网络用于每个查询样例和任务的支持集上。
![]()
其中 cp: contextual path, ap: attentive path, sa: self-attention, ca: cross attention
3.4.2 权重生成器
上下文路径和注意力路径的输出拼接为 X c p ⊕ a p X^{cp⊕ap} Xcp⊕ap, X c p ⊕ a p X^{cp⊕ap} Xcp⊕ap 对于生成分类权重的查询样例是特定的。
给权重生成器 g 输入 X c p ⊕ a p X^{cp⊕ap} Xcp⊕ap , 假设分类权重服从具有对角协方差的高斯分布,g 输出该分布的参数,作者利用再参数化技巧( reparameterization)从学到的分布中采样权重。
![]()
![]()
∑ w i \sum_{w_i} ∑wi 是由 σ w i \sigma_{w_i} σwi 构成的对角协方差矩阵。采样得到的分类权重表示为 W ∈ R N K × d W∈R^{NK×d} W∈RNK×d 。
为了降低复杂度,对每个类计算 K 上分类权重的均值,得到 W f i n a l ∈ R N × d W^{final}∈R^{N×d} Wfinal∈RN×d 。
对查询数据的预测,可通过计算 W f i n a l x ^ W^{final}\hat x Wfinalx^ 。对支持数据的预测,可通过计算 W f i n a l x c i W^{final}x_{c_i} Wfinalxci。
除了权重生成器 g,还有另外两个解码器 r1 和 r2。它们都拿生成的权重 W 作为输入,用于学习式10 中的 p θ ( x ^ ∣ w i ) p_θ(\hat x|w_i) pθ(x^∣wi) 和 p θ ( x c i ∣ w i ) p_θ(x_{c_i}|w_i) pθ(xci∣wi) 。
换句话说,r1 和 r2 分别是为了重构 x c i c p x_{c_i}^{cp} xcicp 和 x ^ a p \hat x^{ap} x^ap,r1 和 r2 的输出表示为 x c i , r e c p , x ^ r e a p ∈ R d h x_{c_i, re}^{cp}, \hat x^{ap}_{re}∈R^{d_h} xci,recp,x^reap∈Rdh 。
3.5. 训练和预测
元训练期间所用的目标函数 10 等价于式 20
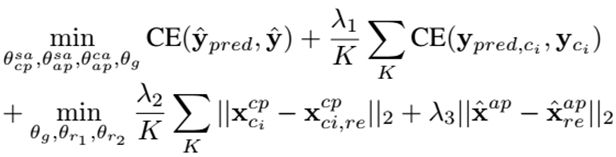
其中,CE 代表交叉熵。式20 把式10 中的 log 似然换成了均方误差或交叉熵,所以式20 每一项的值不同于式10 中的对应项。因此,为了权衡不同的项,必须决定超参数 λ1, λ2, λ3。
重构损失用于更新(反向传播) r1, r2 和 g 的参数。
这是因为作者想让两条路径中的注意力模块聚焦于编码富有表现力的表征,用于接下来的分类。在后三项的帮助下,迫使所生成的分类权重携带支持集与特定查询样例的信息。
应该注意的是,这个损失函数的计算是对一个任务中的一个查询样例。元训练期间,一个任务中有多个查询样例,而且一个batch中有多个任务,用于计算式20 的平均值。
元测试时, μ \mu_{_} μwi 直接作为类别 _ ci 的分类权重,而不再经过采样。
4. 实验
4.1. 数据集和协议
两个通用的基准数据集 miniImageNet 和 tieredImageNet。
为了公平对比,作者使用 LEO 中所用的同一数据集,每个图像表示为 640 维的向量。
元训练,对于 N-way K-shot 实验,从元训练集中随机采样 N 个类,每个类有 K 个样例作为支持集,15个样例作为查询集。和其他工作类似,训练 5-way 1-shot 和 5-shot 模型。
元测试,从元测试集采样 600 个 N-way K-shot 任务,计算查询集的平均准确率,采用 95% 的置信区间。
4.2. 实现细节
用TensorFlow 实现,d=640 是输入特征向量的维度, h _ℎ dh 设置为 128,多头注意力模块的头数 H = 4,g, r1 和 r2 都是 2 层的 MLP(多层感知机)隐层单元数量是 256, λ1 = 1, λ2 = λ3 = 0.001。
优化器使用 ADAMW,权重衰减 1E−6。初始学习率, 5-way 1-shot 是 0.0002, 5-way 5-shot 是0.001,每迭代 15000 次衰减 0.2。总共迭代 50000 次。 Batch size, 5-way 1-shot 是 64, 5-way 5-shot 是32。
和 LEO 做法相似,首先在元训练集上训练模型,根据验证结果选择最佳超参数。然后使用固定的超参数在元训练集和元验证集上训练模型。
4.3. 与其他方法的比较
本文提出的方法 AWGIM 与最近几年提出的最先进的一些方法进行性能对比。
元学习方法的种类:基于测量的方法,基于梯度的方法,基于图的方法,分类权重生成方法。
在两个数据集上,AWGIM 都取得了性能前三名,特别地,在所有设置下都超过了 LEO。
应该注意的是, 为了与 LEO 进行公平对比,AWGIM 使用的是 WRN-28-10 提取的固定的图像特征。一些训练技巧可以显著提升模型性能,包括数据增广、权重衰减、dropout等。
4.4. 分析(对 AWGIM 进行详细分析,每一模块的作用)

注意力路径的效果:支持集上的自我注意,比 LEO 所用的关系网络不差。具有信息最大化的生成器取得的性能比 LEO 略高。
注意力机制的效果:通过替换注意力模块,调查性能。一个MLP在上下文路径中用于支持集,另一个MLP在注意力路径中用于查询样例。实验结果表明,即使不用注意力对任务上下文信息进行编码, “MLP编码”所达到的准确率也能接近LEO,这是信息最大化的好处。但是把 λ1, λ2, λ3 都设置为0,性能下降显著,这表明了信息最大化的重要性。
多头注意的贡献:把两个路径中的多头注意替换为单头注意,进行实验。多头注意性能更高。
关于λ1, λ2, λ3 的消融分析【参考1,参考2】:研究信息最大化的效果。λ1, λ2, λ3 都为0时,结果表明生成的分类权重不适合当前任务,即使有注意力路径。与 λ3 = 0相比, λ1 = λ2 = 0时,性能下降更明显,这表明权重与支持集之间的信息最大化更重要。 λ1 = 0 对性能影响很大,表明支持集标签预测对信息最大化更关键。
分类权重是否适应不同的查询样例:通过打乱分类权重的顺序来调查。两种打乱方式:类别内部的不同查询样例、不同类别的查询样例。对于 5-way 1-shot 实验,类间打乱比类内打乱造成的性能下降更明显,这表明支持集样例太少时,对同一类别的查询样例所生成的权重是相似的,对不同类别的查询样例所生成的权重是不同的。对于 5-way 5-shot 实验,两种打乱方式结果非常接近甚至相同,性能都有下降。这表明 5-way 5-shot 情况下所生成的分类权重,不但更加多样化,而且更贴合每个查询样例。可能是因为大一些的支持集能提供更多的知识用于估计每个查询样例的最优分类权重。
4.5. 收敛
比较 AWGIM 和 LEO 的收敛速度。两个模型的 batch size都设置为16。 AWGIM 收敛更快,性能更高。

4.6. 预测时间花费(Inference Time Cost )
AWGIM 的预测时间表明其计算开销最小。由于 AWGIM 和 MLP 的时间复杂度取决于|Q| ,所以作者测试了不同数量的查询样例。
结果表明, |Q|很小时, AWGIM比 LEO更快。|Q|较大时,MLP和AWGIM都比 LEO 更慢。很明显,与“MLP编码”相比,在 AWGIM 中使用自我注意和交叉注意,带来的开销可以忽略。

5. 结论
本文介绍了小样本图像分类的一种方法 AWGIM,通过两条编码路径,学习对任务中的每个查询样例生成最优的分类权重。为了这一目的,对生成的权重与查询集、支持集之间的互信息下界进行最大化。
【本期作者主页】https://blog.csdn.net/jieming2002