软考初级程序员常见类型题,错题个人笔记
软考初级程序员常见类型题,错题个人笔记
1.操作系统三状态

2.原码补码反码
转换
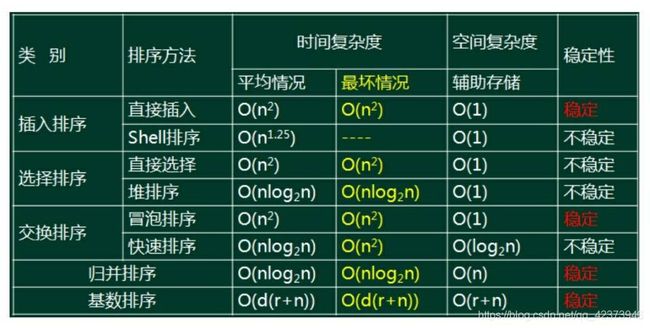
3.各种排序
1
2
4.设计模式分类

5.uml四种事物
事物: 是对模型中最具有代表性的成分的抽象。
结构事物: 如类(Class)、接口(Interface)、协作(Collaboration)、用例(Use Case)、主动类(Active Class)、组件(Component)和节点(Node);
行为事物: 如交互(Interaction)、状态机(State machine);
分组事物:(包, Package);
注释事物:(注解, Note)。
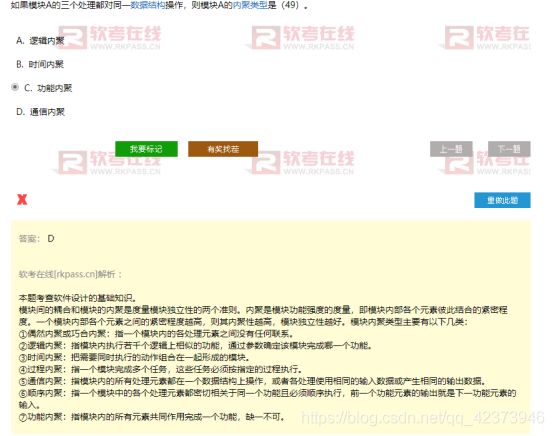
6.内聚类型
7.软件维护

8.白盒测试(路径覆盖等)
分类
白盒测试方法:
(1)语句覆盖。被测程序的每个语句至少执行一次。是一种很弱的覆盖标准。
(2)判定覆盖。也称为分支覆盖, 判定表达式至少获得一次真、假值。判定覆盖比语句覆盖强。
(3)条件覆盖。每个逻辑条件的各种可能的值都满足一次。
(4)路径覆盖。覆盖所有可能的路径。
(5)判定/条件覆盖。每个条件所以可能的值(真/假)至少出现一次。
(6)条件组合覆盖。每个条件的各种可能值的组合都至少出现一次。
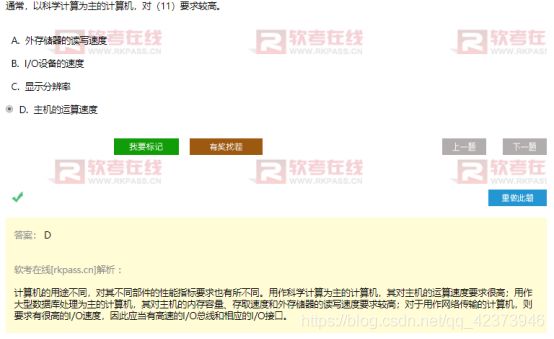
9.计算机满足不同要求应该具有的特性
10.病毒后缀

11.哈弗曼树
哈弗曼树构造
12.事务的四个特性
原子性: 事务是原子的, 要么做, 要么都不做。
一致性: 事务执行的结果必须保证数据库从一个一致性状态变到另一个一致性状态。
隔离性: 事务相互隔离。当多个事务并发执行时, 任一事务的更新操作直到其成功提交的整个过程, 对其它事物都是不可见的。
持久性: 一旦事务成功提交, 即使数据库崩溃, 其对数据库的更新操作也永久有效。
13.文件后缀
在windows操作系统下,可执行程序可以是 .exe文件 .sys文件 .com等类型文件。

14.判定算法的优劣
评定一个算法的优劣, 主要有以下几个指标。
(1)正确性: 一个算法必须正确才有存在的意义, 这是最重要的指标, 要求编程人员应用正确的计算机语言实现算法的功能。
(2)友好性: 算法实现的功能是给用户使用的, 自然要具有良好的使用性, 即用户友好性。
(3)可读性: 算法的实现可能需要多次的修改, 也可能被移植到其他的功能中, 因此算法应当是可读的、可以理解的, 方便程序人员对其分析、修改移植到自己的程序中, 实现某些功能。
(4)健壮性: 在一个算法中, 经常会出现不合理的数据或非法的操作, 所以一个算法必须具有健壮性, 能够对这些问题进行检查、纠正。算法具有健壮性是一个升华, 当用户刚开始学习写算法时可以忽略它的存在, 在逐渐的学习中要努力让算法更加完美。
(5)效率: 算法的效率主要是指执行算法时计算机资源的消耗, 包括计算机内存的消耗和计算机运行时间的消耗。这两个消耗可以统称为时空效率。一个算法只有正确性而无效率是没有意义的, 通常, 效率也可以评定一个算法是否正确。如果一个算法需要执行几年甚至几百年, 那么无疑这个算法会被评为是错误的。
15.数据库外模式和内模式
外模式/模式映象: 定义在外模式描述中, 把描述局部逻辑结构的外模式与描述全局逻辑结构的模式联系起来, 保证逻辑独立性: 当模式改变时, 只要对外模式/模式映象做相应的改变, 使外模式保持不变, 则以外模式为依据的应用程序不受影响, 从而保证了数据与程序之间的逻辑独立性, 也就是数据的逻辑独立性。
模式/内模式映象: 定义在模式描述中, 把描述全局逻辑结构的模式与描述物理结构的内模式联系起来, 保证物理独立性: 当内模式改变时, 比如存储设备或存储方式有所改变, 只要模式/内模式映象做相应的改变, 使模式保持不变, 则应用程序保持不变。 也就是数据的物理独立性
外模式/模式映象—>逻辑独立性
模式/内模式映象—>物理独立性
16.根据ip地址计算子网掩码
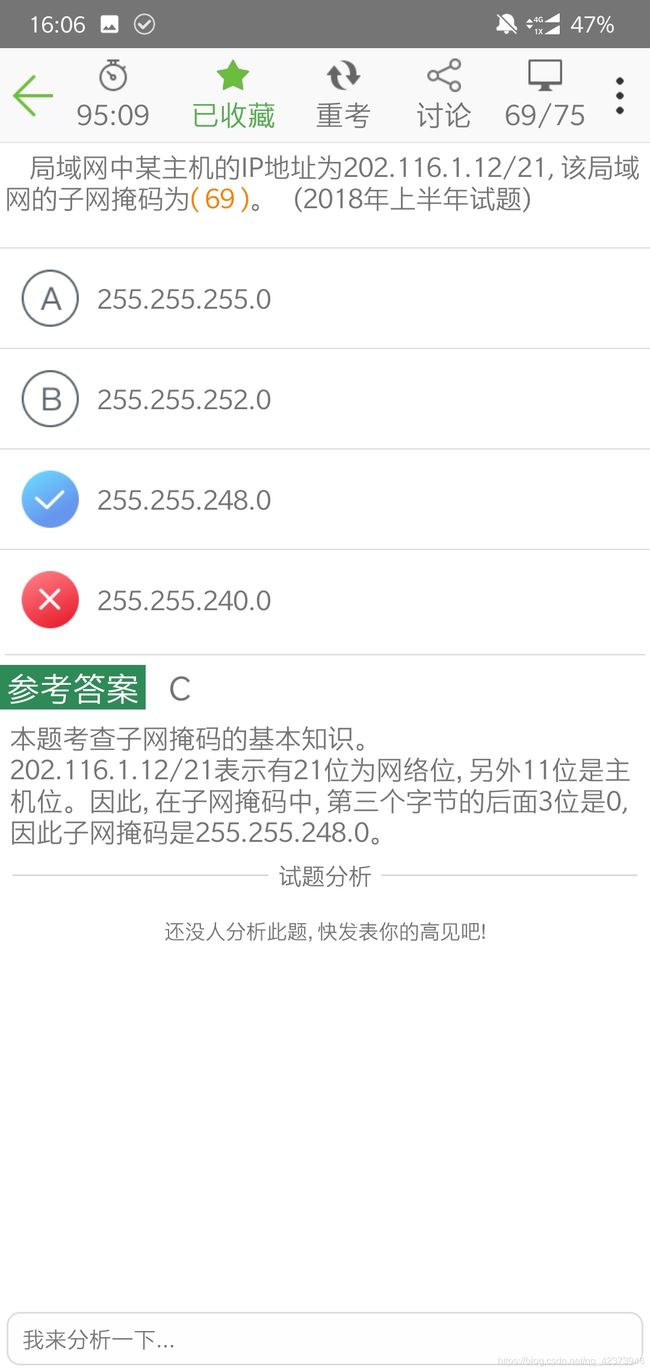
二进制表示:
11111111.11111111.11111000.00000000(有21个1),然后转为10进制就好了
17.Excel常用操作
常用函数
18.数据库设计的阶段
数据库的设计过程如下:
需求分析: 分析用户的需求, 包括数据、功能和性能需求; 得到数据流图、数据字典和需求说明书。
概念设计: 用数据模型明确地表示用户的数据需求。其反映了用户的现实工作环境, 与数据库的具体实现技术无关。(E-R模型)。
逻辑设计: 根据概念数据模型及软件的数据模型特性, 按照一定的转换规则和规范化理论, 把概念模型转换为逻辑数据模型, 如层次模型、网状模型、关系模型等。
物理设计: 为一个确定的逻辑数据模型选择一个最适合应用要求的物理结构的过程。
19.计算机网络的各种协议
计算机网络的各种协议
协议大全2