关于人脸识别项目
- 事宜
| 日期 | 待做 | 备注 |
| 2019/05/25 | (1)人脸比对的模型可以考虑由faceNet换成insightFace (2)MTCNN人脸检测器可以再重新训练 |
|
| 2019/06/10 | (1)开发那边的图片有些不合格,不符合我这边的规则的时候,可以删掉这些图片,并且新增图片。 | |
| 2019/06/11 | (1)编码考虑自动化,设定时间让程序自动运行 (2)将比对代码所有人和所有人对比 |
|
| 2019/06/12 | (1)服务器和线下数据整合; (2)与官方数据集进行对比,计算准确率; (3)新增数据时,不根据系统时间而是每次对比是否存在这个json文件; |
|
| 2019/06/13 | (1)筛选图片时,选择人脸区域分辨率不小于80*80甚至100*100的; (2)一个id的比对结果也可以不是一个,可以返回多个结果供人来进行最后的判定; |
|
| 2019/06/17 | (1)之后要训练facenet的权重文件; (2)可能服务器上并不需要每个id存放50张图片,10张应该就够了; |
|
| 2019/06/19 | (1)考虑损失函数是用softmax还是tripletloss函数; | |
| 2019/06/20 | (1)对每个id下进行聚类,找到id下不是一个人的; |
李博的意见是一个id下两个学生上课的情况毕竟是少数,暂时先不管,一起放进去训练。 |
| 2019/06/21 | (1)安保领域的黑白名单,借鉴此思路; (2)训练的时候学习率的策略,要加上验证集,可以考虑用LFW数据集或者,自己构造; (3)问中华哥,无用的图片要不要删了,放着也是占内存,还增加了我这边的处理量; |
|
| 2019/06/24 | (1)正式训练之前要检查学习率优化器等; (后面的处理要学习聚类) |
done |
| 2019/07/02 | (1)从6月20到7月2号,学生ID一共增加了800多个,这个正常吗? | |
| 2019/07/05 | (1)每个学生仅留下一张做比对时,会不会在人工筛选阶段不利于判断,这个需要看一张的策略是否有问题; | |
| 2019/07/05 | (1)为了解决遮挡带来的精度下降问题,提出线性空间重构,利用参考图片的信息尝试尽可能地恢复残缺特征图,恢复后的特征图和参考特征图之间的距离即为重构距离。 | |
| 2019/07/23 | (1)尝试不同的人脸检测器和不同的人脸识别模型; | |
| 2019/07/30 | (1)分批给lpb结果,先以表筛选,再类内筛选; (2)可以设置不同的阈值; |
|
| 2019/08/01 | (1)接口的服务:将传入的id与全库的id进行对比; |
- 工作手记:
2019/06/05
6月5号前的120万(1256250)张图片中,编码成功了100万(1072036)张。
2019/06/10
这次增加aftercoding时间是截止到2019-06-10的图片
2019/06/11
增加aftercoding的时间从2019-06-10 12:00到2019-06-11 11:00
截至到下午已经编码了1115801条,大概存了6万多个id的图片
2019/06/13
目前的人脸识别的具体步骤如下:
筛选图片———人脸对齐——通过训练的模型进行编码——直接比较各张脸之间的欧式距离
2019/06/19
测试了权重文件20170512-110547,20180402-114759在LFW数据集上的准确性,分别是0.99550+-0.00342@ FAR=0.00100,0.97467+-0.01477 @ FAR=0.00133
关于lfw数据集的pairs.txt的格式说明:
从Line1-line301是同一个id的不同图片;
line302-line601是不同id的图片;
Line602-line901是同一个id的不同图片;
line902-line1201是不同id的图片;
.......
每行是一对,测试过程LFW给出一对照片,询问测试中的系统两张照片是不是同一个人,系统给出“是”或“否”的答案。通过6000对人脸测试结果的系统答案与真实答案的比值可以得到人脸识别准确率。这样的测试一共进行10次,每次600行有300行是匹配的,300行是不匹配的 。参考
2019/06/17
用facenet的模型20170512-110547,测试了pot是10000的50个id的识别正确率,得到的是0.831-0.9之间;
2019/06/18
昨天97个id的图片的正确率是0.831-0.9之间,今天将id增加到495个,正确率是0.868+-0.012并没有显著变化。开始增量训练facenet模型;找到了训练分类器以及进行分类和预测人是那个的方法:分别使用claffifier.py以及predict.py。使用方法:博客。
2019/06/19
今天把facenet增量训练和直接训练的softmax函数也调通了
因为服务器上的图片存在不同id下同一个人的情况,因此,训练策略需要再考虑。目前考虑的
策略有两个:(1)对训练的照片先选用官方模型进行严格筛选,再放入进行训练,但是这样要考虑如果是将官方模型文件能够选出的图片放进去训练的话,意义不大,只能从facenet识别有问题的图片下手(facenet或者其他的模型)(2)可以从结果入手,进行对比的时候返回的结果不至一个id,这就需要在后面的部分加一些逻辑。这两种方法都要考虑聚类进去。
2019/06/20
目前aiImg服务器上一共140万图片(1400701),7万id(70048),图像的像素大小对识别的精度有着非常重要的影响
LFW数据集的分辨率:250*250
关于编码之前的人脸对比,facenet不需要像别的人脸识别的对齐方式:
faceNet不采用landmark直接用CNN来学对齐的那套,直接是face detection->feature extraction
其他的走face detection->face alignment ->feature extraction步骤。
2019/06/21
根据格灵深瞳的CEO赵勇:在公安系统的人脸识别系统中,对于犯罪分子的抓捕,是有黑白名单的(我认为一定不是全库搜索,在给定计算能力的情况下,耗时一定很久,正确率也会大大下降)。
人眼的分辨率大致计算是5.76亿。
图片量1404140,上的课只有一半的量能够存下来;
facenet的模型20180402-114759,测试海风的495个id的12k图片(12143),Accuracy:0.868+-0.012;
facenet的模型20170512-110547,测试海风的495个id的12k图片(12143),Accuracy:0.829+-0.010;
差了3%
从2019-06-21 18:12:58开始人脸对齐,
2019/06/22
pic:1407545
2019/06/24
一共切割137万完成(1372500)图片,不能对齐的有3万5千张图片(34973)
训练的参数设置,
第一个epoch训练之后,正确率0.9145+-0.01065;
第2个epoch训练之后,正确率0.91317+-0.01047;
第3个epoch训练之后,正确率0.91467+-0.00977;
第4个epoch训练之后,正确率0.91550+-0.00949;
第5个epoch训练之后,正确率0.91633+-0.00113;
2019/06/25
经过200轮训练之后,正确率跟昨天一致,但是损失从昨天的11稳步降到了8左右,Accuracy也增加到了0.55左右;
中华哥那边的日志的路径:/home/zzh/vision/faceDetector/logs
2019/06/26
人脸识别对整张照片的像素没有要求,但是脸部像素至少在64x64以上,最好是128x128以上。参考阿里云的问答;
写了一个筛选规则,只有大约一半的id有符合要求的图像;
2019/06/27
使用20180402-114759,测试海风的对500个id的筛选后的图片,Accuracy:0.897+-0.012;也就是正确率提高了3%(不是之前的500个id)
自己的数据训练200论之后,测试海风500个id的正确率0.858+-0.012
自己的数据训练200轮之后,测试海风之前的495个id的正确率竟然是:0.821+-0.006也就是比原先的基础模型的准确率(0.868+-0.012)反而降低了4%,目前原因不明。
2019/07/01
服务器上学生的图片数量依然是142万张(1424431);
使用服务器上的验证validate_on_lfw.py,来测试模型的正确率时,采用官方的20180402-114759.pb,Accuracy: 0.86633+-0.01201;采用20190624-163159(softmax)时,Accuracy: 0.91700+-0.01074;
在本地采用validate_on_lfw.py,验证20190701-173059(triplet_loss)时,Accuracy: 0.950+-0.009;
在本地采用validate_on_lfw.py,验证之前训练的模型,Accuracy: 0.939+-0.005;
在本地采用validate_on_lfw.py,验证20190701-173059(triplet_loss)时,用筛选之后的图片,Accuracy: 0.966+-0.004;
在本地采用validate_on_lfw.py,验证20190701-173059(triplet_loss)训练140轮之后的qu时,权重文件时,在筛选之后的500个id上,Accuracy: 0.984+-0.005;
2019/07/02
截止到今天服务器上一共有图片142万张(1426176),学生数目7万(70892)
2019/07/03
服务器上的图片,进行选择时,将人脸区域的大小限制为124*124时,符合此条件的图片大约是17%;再限制全部关键点以及头部角度(-10,10)会减少4%
服务器上的图片,进行选择时,将人脸区域的大小限制为86*86时,符合此条件的图片大约是66%;再限制全部关键点以及头部角度(-10,10)会减少4%;
在服务器上,调整脸部区域面积为90*112时,筛出率为83.5左右,筛出id一共1000个,6000个问答,使用权重文件20190701-173059的正确率是0.96900+-0.00549;
在本机上,调整脸部区域面积为90*112时,筛出率为83.5左右,筛出id一共1000个,6000个问答,使用权重文件20190701-173059的正确率是0.967+-0.005;
在服务器上,对triplt损失函数训练400轮之后的20190701-193246,对之前按照124*124的标准筛选出的数据测试的结果是0.99217+-0.00373;
在服务器上,对triplt损失函数训练400轮之后的20190701-193246之后,对未进行筛选的hf_tmp的数据测试的结果是0.97533+-0.00666;
在服务器上,对triplt损失函数训练400轮之后的20190701-193246之后,对按照90*112的标准筛选出的数据测试的结果是0.99117+-0.00308;
在本机,对triplt损失函数训练400轮之后的20190701-193246之后,对按照124*124的标准筛选出的数据测试的结果是0.987+-0.004;在没有经过筛选的数据上测试的0.964+-0.008;
在服务器上,对triplt损失函数训练500轮之后的20190701-193246,对之前按照124*124的标准筛选出的hf_tmp_after_select数据测试的结果是0.98300+-0.00427;
在服务器上,对triplt损失函数训练500轮之后的20190701-193246,对之前按照90*112的标准筛选出的hf_tmp_after_select1数据测试的结果是 0.98183+-0.00647;
2019/07/04
根据筛选规则的结果统计
| id | notes | good or bad |
| 115505 | 遮挡导致选择的脸不是最大的最清楚的 | 0 |
| 115529 | 1 | |
| 115544 | 1 | |
| 1 | ||
| 199833 | 有遮挡 | 1 |
| 1 | ||
| 1 | ||
| 1 |
2019/07/05
服务器上截止到今天积累的图片150万(1502914),id数目72k(72461)
2019/07/09
服务器上图片的数量152万(1526953),id数目73k(72979),平均每个人20张图片;
警方给出寻找跟某个罪犯比较相似的会按照相似度给出TOP K(K值一般是十、几十或者100)个相似的预测;
CASE:假设一共10个罪犯,安防搜索100万次,底库有10万,总共系统报警100此,确认9个嫌疑犯;
召回率:10个罪犯出现,抓到了9个,不考虑报警了多少次,召回率90%;
误报率:误报91次,一共搜索100w*10w次,误报率:91/(100w*10w)约为10亿分之一
影响人脸识别效果的一些因素:
(1)数据收集、数据清洗、数据分布不平衡;
(2)domin问题(监控/手机自拍/证件照/黑白)
(3)分辨率、侧脸、遮挡、光照、模糊、跨年龄段等极端情形的改进;
(4)loss设计;
(5)超大规模模型训练;
(6)模型压缩(distilling、int8等;
(7)模型评测;
(8)检测/Alignment准确性;
(9)视频流中人脸跟踪的稳定性,人脸的抓拍质量;
(10)视频中人脸多帧融合
(11)........
2019/07/10
查了服务器上老师的数量1.2万(12406),图片数量62万(624453)
人脸识别常用的测试数据集:
LFW:5K名人,6k对人脸比对;(量小,有饱和趋势)
MeGaface:在100万干扰项中找到目标人脸;(存在一些噪声数据,正样本人脸对的数量有限)目前在筛除噪声之后,精度已经刷到了98.998%;筛除噪声之前(iBUG_DeepInsight)数据集,达到精度98.063%;
类内噪声:同一个id下不是一个人的图片;
类间噪声:同一个id被分到了不同id下面;
如何解决类别分布不平衡和跨domin的问题(因为不同种族人脸之间的距离不同),留待学术人员研究;
类内图片的差异:
戴眼镜、模糊、遮挡、黑白、侧脸、跨年龄、化妆;
关于数据:
gallery set:参考图像集 | probe set :测试图像集; | quarery set:也就是做真实情况时候的数据(个人理解)
千亿级别人脸识别模型测试,上传编码之后的文件:http://trillionpairs.deepglint.com/overview
这里有一个非常好的人脸识别的综述:https://www.cnblogs.com/shouhuxianjian/p/9789243.html
大致理一下近几年常用的人脸识别的数据集:
| 时间 | 名字 | 人数 | 图片量 | 备注 |
| 2007 | LFW(labled face in wild) | 5K | 13k | 最早的非约束场景下的人脸识别测试数据集 |
| 2014 | CASIA WebFace | 10k | 500k | 大规模公开训练集,平均50 |
| 2016 | VGGFace | 2.6k | 2.6M | 训练集,平均1000 |
| 2018 | MS-celeb-1M | 100k | 10M | 训练集,平均100,特点:广,化妆,每个id图像的数量都逼近100张; |
| 2018 |
Megaface | 670k | 4.7M | 训练集,平均7,特点:日常 |
| 2018 | VGGFace2 | 9k | 3.3M | 训练集,平均366,特点:深,每个Id下最少3张图片,最多2469图片; |
(1)Cao在VGGFace2和MS-celeb1-M上进行模型训练并做了系统性研究,并发现首先在MS-celeb-1M(广度)上训练然后在VGGFace2(深度)进行微调可以得到最优的结果。
(2)数据偏置问题:数据集存在差距,例如Megaface是日常场景,而VGGface2和Ms-celeb-1M的场景是化了妆的场景,这种数据
2019/07/15
FRVT比赛中,格灵深瞳的比赛经验总结:https://zhuanlan.zhihu.com/p/72518307
训练模型的过程:
根据以往的经验,在这个特定的比赛任务上,不断的试验:
(1)各种模型优化策略;
(2)数据集融合策略;
(3)调整和尝试各种模型结构;
(4)调整超参数、迭代次数、损失函数、等等;
混合精度训练:
单精度:32位浮点数;
半精度:16位浮点数;
大多数的深度学习模型使用的是32位浮点数(fp32)进行训练,而混合精度训练的方法,通过16位浮点数的方法(fp16)进行深度学习模型训练,从而减少训练深度学习模型所需要的内存,同时由于fp16的运算比fp32更快,从而也进一步提高了硬件效率。
深度学习模型的计算任务分为训练和推理,训练往往是放在云端或者超算集群中,利用GPU强大的浮点数计算能力,来完成网络模型参数的学习过程。一般来说训练时,计算资源往往非常充足,基本上受限于显存资源/多节点扩展/通讯库效率的问题。相对于训练过程,推理往往被应用于终端设备,如手机,计算资源/功耗都收到严格的限制,为了解决这样的问题,提出了很多不同的方法来减少模型的大小以及所需的计算资源/存储资源。模型压缩除了剪枝以外,还有一个方法就是降低模型参数的数值精度。随着网络深度的加大,带来的参数数量也呈现指数级增长,如何将最终学习好的网络模型塞入到终端设备有限的空间中是目前很多性能优良的网络真正应用到日常生活中的一大阻碍。
我从此次比赛经验学到的:
(1)基于insightface的baseline进行;
(2)修改insightface的网络结构,数据集处理等;
(3)模型剪支、压缩;
2019/07/16
(1)对id_A的每张图片匹配id(P_id_n)(设置阈值),如果这个id_A下面的所有图片都可以跟某个id下面的图片匹配的到;
对id_A的每张图片匹配id(P_id_n)(设置阈值),如果小于这个阈值的id的数目占总数的一半以上,则认为可疑Id
2019/07/17
筛选之后,大约有58%的id下的图片是不超过10张的,51%的图片是不超过9张的
2019/07/18
pkl文件需要二进制读写,json文件是一种能传递基本的数型(int,long,string等),但不能传递byte类型,即不能进行二进制读写;
所以,同样的内容保存在pkl文件是比保存在json文件所占的内存小的:pkl文件 4.6kb;json文件 11kb;
2019/07/22
服务器上学生id数量:7.3万(73541),图片数量154万(1547419);
试了本机的4万多pkl一次性读入内存,只占了2.5兆
id:156867 1543839
id:1522295 1316737
2019/07/23
发现用之前训练的模型可能呢能够大概区分不同id;
2019/07/24
将之前本地的id和服务器的合并,学生数量89371 图片数量 1959591
2019/07/25
连蓬勃给的查找的意见:
`view_student`表的 先查track_userid相同的,其次查 exam_year sex province_id相同的
2019/07/30
track_userid相同的, exam_year sex province_id相同的数据中,student_id的数量小于1000的,一共12154行,只有343行中的数据满足,至少两个ID的图片是被编码的。
same_by_track_userid_exam_year.txt一共12508行,少于100个的占12173行,100到1000之间的占据170行,1000到10000之间的128行,大于10000的有37行。
2019/07/31
人脸识别的对比:
0<=len(name_list)<100
100<=len(name_list)<1000;60910个id
1000<=len(name_list)<1500:32行,39620个id
排列组合计算公式:
![]()
![]()
将1000——1500之间的图片结果与face++对比
743个文件夹,聚类时间越1个小时
2019/08/05
insightface人脸识别
2019/08/06
insightface的距离和相似度计算方法:
dis = np.sum(np.square(v1-v2))
sim = np.dot(v1, v2.T)
2019/08/07
人脸检测算法评价标准中,FDDB数据集是一个常用的评价标准,地位类似于人脸识别评价中的LFW数据集。
1.FAR(false accept rate)误识率:本该匹配失败的判别为匹配成功的次数/类间尝试总次数(假冒者尝试的总次数)
2.FRR(false rejection rate)拒识率:本该匹配成功的判别为匹配失败次数/类内匹配总次数(总的匹配成功次数)
3.TRR = 正确拒绝的次数/类间匹配的次数,TRR = 1 - FRR
4.TAR = 正确拒绝的次数/类内匹配的次数,TAR = 1 - FAR;
FAR越高,意味着假冒者被接受的可能性越高,系统安全性越低;
FRR越高,意味着合法用户被拒绝的可能性越高,系统的易用性越低;
因此,强调安全性的场合,例如金融机构,要求较低的FAR,也就是较高的阈值;一般情况下,误识率FAR 随阈值的减小(放宽条件)而增大,拒识率FRR 随阈值的减小而减小。因此,可以采用等错误率(Equal Error Rate, ERR)作为性能指标,即通过调节阈值,使这FAR和FRR两个指标相等时的FAR 或 FRR。
3.Acc(准确率):(TP+FN)/(TP+FP+FN+TN)
4.Precision(精确度)= TP/(TP+FP),又名查准率,意为:预测为正样本的实例中,确实是正样本的比例;
5.TPR(true positive rate)将正例分为正类的概率,也称为recall = TP/(TP+FN),又名查全率,意为:实际是正样本的实例中,被预测为正样本的实例,所占比例;

参考:https://www.cnblogs.com/shinedaisiki/p/10050267.html
https://blog.csdn.net/lijiao1181491631/article/details/54407830
2019/08/14
服务器上学生ID数量89581人,图片数量1968454
2019/09/02
服务器上学生ID数量89649人,图片数量1972431
2019/09/03
服务器上学生ID数量89653人
2019/10/-9
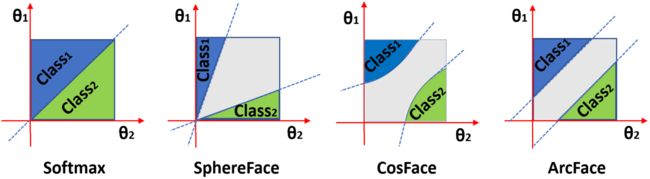
人脸识别中常见的损失函数:softmax,triplet loss, center loss,cosine loss,arcface等;参考资料
人脸识别的baseline是:CNN+softmax
softmax损失函数是使用softmax激活函数加上crossEntropy作为损失函数将线性特征转化为概率。最早的softmax损失函数,不能像metric learning那样显式化类内距离以及类间距离,因此性能不是特别好。另外,人脸识别不只是分类,根源在于得到泛化能力更强的人脸特征。(metric learning概念:根据不同任务,自主学习出针对于某个任务的距离衡量函数);
triplet loss:与softmax损失函数最小化类内距离,最大化类间距离不同,triplet loss引入样本间距离的概念,直接对样本间距离进行优化,使不同类间样本距离比同类间样本距离大出一个间隔(margin)。在训练样本足够多,模型的表示能力足够强的情况下,triplet loss函数能够学习的很好。但是使用该损失函数的时候,由于过于关注局部,经常出现难以训练且收敛时间长的问题。因此,比较好的训练方式是先使用分类损失函数训练模型,再使用triplet loss进行fine tune来提升模型的效果。
center loss的提出:有些情况下,类内距离比类间距离还要大,该损失函数为每一个类别提出一个类内中心,最小化每个样本与中心的距离。因此center loss是用于压缩类内距离;
cosine loss将人脸的embedding信息归一化,使得类间距离仅取决于余弦夹角,并进一步引入了余弦间隔参数,用于扩大类间距,缩小类内距离,同时,由于,余弦角范围较小,为了扩大类间距离,是的类间距离更显著,引入超参数,来放大余弦距离。
arcface是为了使得embedding的表示更加符合超球体流行假设,将cosine loss的余弦距离改为角度距离。