转载请出自出处:http://eksliang.iteye.com/blog/2309311
一、什么是RDD算子
答:所谓RDD算子,就是RDD中定义的函数,可以对RDD中的元素进行转换和操作。
二.算子的分类
算子分为两类:转换算子(Transformation)和行动算子(Action)。
- 转换算子(Transformation):操作时延迟计算的,也就是一个RDD转换为另外一个RDD不是马上执行的,需要等到行动算子(Action)执行的时候,才会真正触发。
- 行动算子(Action):Action算子的执行会触发Spark提交作业。
三.导包
本地导入目前spark最新版本,spark1.6进行测试
org.apache.spark
spark-core_2.10
1.6.0
org.apache.spark
spark-sql_2.10
1.6.0
org.apache.hadoop
hadoop-client
2.5.2
四.转换算子(Transformation)
温馨提示:这里演示使用javaAPI来使用算子,在javaAPI中目前没有处理key-value的算子,只有处理value数据类型的算子,也就是说如下API没有提供
- mapValues()
- combineByKey()
- reduceByKey()
- partitionBy()
- Cogroup()
- Join()
4.1.输入分区与输出分区一对一型
4.1.1.map()
将原来RDD的每个数据项通过map中的用户自定义函数f映射转变为一个新的元素。源码中的map算子相当于初始化一个RDD,新RDD叫作MappedRDD(this, sc.clean(f))。
图(4-1-1)中的每个方框表示一个RDD分区,左侧的分区经过用户自定义函数f:T->U映射为右侧的新的RDD分区。但是实际只有等到Action算子触发后,这个f函数才会和其他函数在一个Stage中对数据进行运算。V1输入f转换输出V’1。
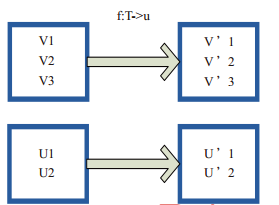
图(4-1-1)
演示代码如下:
/**
* 通过Map算子,将RDD中json字符串对象转换为java对象
*
* @author Ickes
*
*/
public class MapDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("map").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data = Arrays.asList(
"{'id':1,'name':'xl1','pwd':'xl123','sex':2}",
"{'id':2,'name':'xl2','pwd':'xl123','sex':1}",
"{'id':3,'name':'xl3','pwd':'xl123','sex':2}");
JavaRDD rddData = sc.parallelize(data);
rddData.map(new Function() {
@Override
public User call(String v) throws Exception {
Gson gson = new Gson();
return gson.fromJson(v, User.class);
}
}).foreach(System.out::println);
}
}
打印结果如下:
User [id=1, name=xl1, pwd=xl123, sex=2]
User [id=2, name=xl2, pwd=xl123, sex=1]
User [id=3, name=xl3, pwd=xl123, sex=2]
4.1.2.flatMap()
将原来RDD中的每个元素通过函数f转换为新的集合,并将生成的RDD的每个集合中的元素合并为一个集合。内部创建 FlatMappedRDD(this, sc.clean(f))。
如下图(4-1-2)中所示:
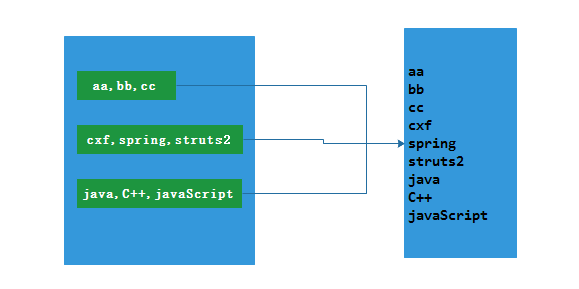
图(4-1-2)
演示代码如下:
/**
* 将rdd中的元素,通过逗号分隔;
* 原始RDD中仅有三个元素,通过flatMap后,新的RDD中有9个元素
* @author Ickes
*
*/
public class FlatMapDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("flatMap").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data = Arrays.asList(
"aa,bb,cc",
"cxf,spring,struts2",
"java,C++,javaScript");
JavaRDD rddData = sc.parallelize(data);
rddData.flatMap(new FlatMapFunction() {
@Override
public Iterable call(String t) throws Exception {
List list= Arrays.asList(t.split(","));
return list;
}
}).foreach(System.out::println);
}
}
返回结果如下:
aa
bb
cc
cxf
spring
struts2
java
C++
javaScript
4.1.3.mapPartitions()
mapPartitions函数获取到每个分区的迭代器,在函数中通过这个分区整体的迭代器对整个分区的元素进行操作。内部实现是生成MapPartitionsRDD。图(4-1-3)中的方框代表一个RDD分区。
图(4-1-3)中,用户通过函数f (iter )=>iter.filter(_>=3)对分区中的所有数据进行过滤,>=3的数据保留。一个方块代表一个RDD分区,含有1、2、3的分区过滤只剩下元素3。
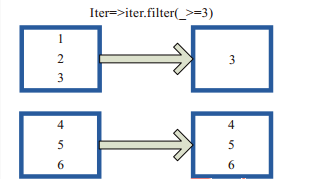
图(4-1-3)
演示代码如下:
/**
* MapPartitions 算子
* @author Ickes
*/
public class MapPartitionsDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("MapPartitions").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data = Arrays.asList(1,2,3,4,5,6,7,8);
JavaRDD rddData = sc.parallelize(data);
rddData.mapPartitions(new FlatMapFunction,Integer>() {
/**
* 其实他跟map的作用一样,区别在于他的输入是RDD中分区的迭代器。
*/
@Override
public Iterable call(Iterator t) throws Exception {
List list = new ArrayList();
while(t.hasNext()){
int num = t.next();
if(num > 3){
list.add(num);
}
}
return list;
}
}).foreach(System.out::println);
}
} 返回结果:
4
5
6
7
8
4.2.输入分区与输出分区多对一型
4.2.1.union()
使用union函数时需要保证两个RDD元素的数据类型相同,返回的RDD数据类型和被合并的RDD元素数据类型相同,并不进行去重操作,保存所有元素。如果想去重,可以使用distinct()。
图(4-2-1)中左侧的大方框代表两个RDD,大方框内的小方框代表RDD的分区。右侧大方框代表合并后的RDD,大方框内的小方框代表分区。含有V1,V2…U4的RDD和含有V1,V8…U8的RDD合并所有元素形成一个RDD。V1、V1、V2、V8形成一个分区,其他元素同理进行合并。
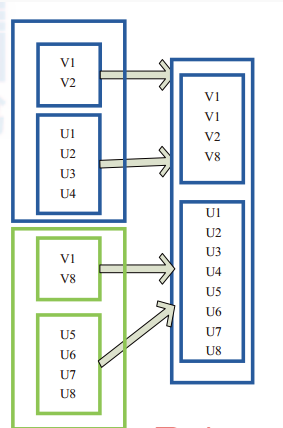
图(4-2-1)
演示代码如下:
/**
* Union算子,合并算子
* @author Ickes
*/
public class UnionDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("Union").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data1 = Arrays.asList(1,2,3,4,5);
List data2 = Arrays.asList(4,5,6,7,8);
JavaRDD rddData1 = sc.parallelize(data1);
JavaRDD rddData2 = sc.parallelize(data2);
rddData1.union(rddData2).foreach(System.out::println);
}
} 返回结果如下:
1
2
3
4
5
4
5
6
7
8
4.2.2.cartesian()
对两个RDD内的所有元素进行笛卡尔积操作。操作后,内部实现返回CartesianRDD。图(4-2-2)中左侧的大方框代表两个RDD,大方框内的小方框代表RDD的分区。右侧大方框代表合并后的RDD,大方框内的小方框代表分区。
图(4-2-2)中的大方框代表RDD,大方框中的小方框代表RDD分区。例如,V1和另一个RDD中的W1、W2、Q5进行笛卡尔积运算形成(V1,W1)、(V1,W2)、(V1,Q5)。
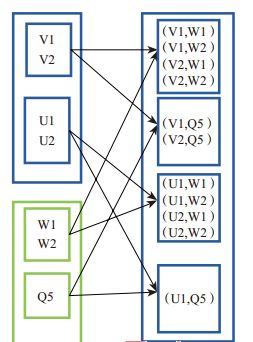
图(4-2-2)
演示代码如下:
/**
* Cartesian 算子,或者笛卡尔积算子
* @author Ickes
*/
public class CartesianDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("Cartesian").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data1 = Arrays.asList(1,2,3);
List data2 = Arrays.asList("aa","bb","cc");
JavaRDD rddData1 = sc.parallelize(data1);
JavaRDD rddData2 = sc.parallelize(data2);
rddData1.cartesian(rddData2).foreach(System.out::println);
}
}
返回结果如下:
(1,aa)
(1,bb)
(1,cc)
(2,aa)
(2,bb)
(2,cc)
(3,aa)
(3,bb)
(3,cc)
4.3.输入分区与输出分区多对多型
4.3.1.groupBy()
将元素通过函数生成相应的Key,数据就转化为Key-Value 格式,之后将Key相同的元素分为一组。
图(4-3-1)中的方框代表一个RDD分区,相同key的元素合并到一个组。例如,V1,V2合并为一个Key-Value对,其中key为“V”,Value为“V1,V2”,形成V,Seq(V1,V2)。
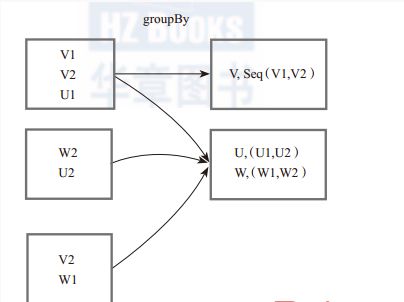
图(4-3-1)
演示代码如下所示:
/**
* GroupBy算子:分组算子
* @author Ickes
*
*/
public class GroupByDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("GroupBy").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data1 = Arrays.asList(1,2,3,1,2,1);
JavaRDD rddData = sc.parallelize(data1);
//jdk1.7
rddData.groupBy(new Function() {
@Override
public String call(Integer v) throws Exception {
String s = "key"+v;
return s;
}
}).foreach(System.out::println);
//jdk1.8
rddData.groupBy(e -> {return "key"+e;}).foreach(System.out::println);
}
} 返回结果如下所示:
(key2,[2, 2])
(key3,[3])
(key1,[1, 1, 1])
4.4.输出分区为输入分区子集型
4.4.1.filter()
filter的功能是对元素进行过滤,对每个元素应用f函数,返回值为true的元素在RDD中保留,返回为false的将过滤掉。内部实现相当于生成FilteredRDD(this,sc.clean(f))。
图4-4-1中的每个方框代表一个RDD分区。T可以是任意的类型。通过用户自定义的过滤函数f,对每个数据项进行操作,将满足条件,返回结果为true的数据项保留。例如,过滤掉V2、V3保留了V1,将区分命名为V1'。
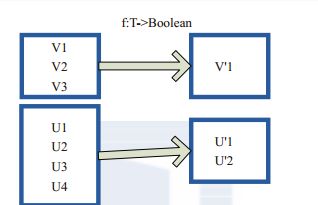
图(4-4-1)
演示代码如下:
/**
* Filter算子,过滤算子
*
* @author Ickes
*
*/
public class FilterDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("GroupBy").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data = Arrays.asList(1, 2, 3, 7, 4, 5, 8);
JavaRDD rddData = sc.parallelize(data);
// 将RDD中小于3的元素进行过滤
// jdk1.8以下
rddData.filter(new Function() {
@Override
public Boolean call(Integer v) throws Exception {
if (v >= 3) {
return true;
}
return false;
}
}).foreach(System.out::println);
// jdk1.8
rddData.filter(e -> e >= 3).foreach(System.out::println);
}
}
返回结果如下所示:
3
7
4
5
8
4.4.2.distinct()
distinct将RDD中的元素进行去重操作。图(4-4-2)中的方框代表RDD分区。
图(4-4-2)中的每个方框代表一个分区,通过distinct函数,将数据去重。例如,重复数据V1、V1去重后只保留一份V1。
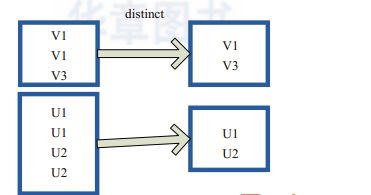
图(4-4-2)
演示代码如下所示:
/**
* distinct算子,去重操作
* @author Ickes
*
*/
public class DistinctDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("Distinct").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data = Arrays.asList(1,2,3,1,2,1);
JavaRDD rddData = sc.parallelize(data);
rddData.distinct().foreach(System.out::println);
}
} 返回结果如所示:
1
3
2
4.4.3.subtract()
subtract相当于进行集合的差操作,RDD 1去除RDD 1和RDD 2交集中的所有元素。
图(4-4-3)中左侧的大方框代表两个RDD,大方框内的小方框代表RDD的分区。右侧大方框代表合并后的RDD,大方框内的小方框代表分区。V1在两个RDD中均有,根据差集运算规则,新RDD不保留,V2在第一个RDD有,第二个RDD没有,则在新RDD元素中包含V2。
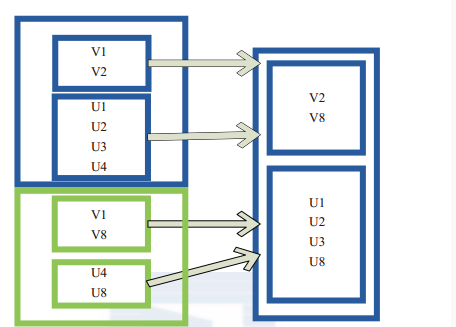
图(4-4-3)
演示代码如下所示:
/**
* Subtract算子,用于求两个集合的差集,要求两个集合中的元素类型保持一致
* @author Ickes
*
*/
public class SubtractDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("Subtract").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data1 = Arrays.asList(1,2,3,4,5);
List data2 = Arrays.asList(4,5,6,7,8);
JavaRDD rddData1 = sc.parallelize(data1);
JavaRDD rddData2 = sc.parallelize(data2);
rddData1.subtract(rddData2).foreach(System.out::println);
}
} 返回结果如下所示:
1
2
3
4.4.4.sample()
sample将RDD这个集合内的元素进行采样,获取所有元素的子集。用户可以设定是否有放回的抽样、百分比、随机种子,进而决定采样方式。
* @第一个参数:withReplacement
* true:表示有放回的抽样;false:表示无放回的抽样;
* @第二个参数:fraction
* 抽取的百分比,例如0.5就是抽取的50%的数据;
* @第三个参数:seed
* 随机种子;
图(4-4-4)中的每个方框是一个RDD分区。通过sample函数,采样50%的数据。V1、V2、U1、U2、U3、U4采样出数据V1和U1、U2,形成新的RDD。
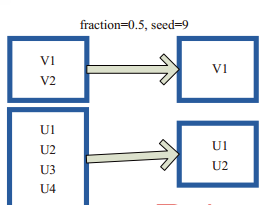
图(4-4-4)
演示代码如下所示:
/**
* Sample算子,抽取样本的算子
* @author Ickes
*
*/
public class SampleDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("Sample").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data = Arrays.asList(1,2,3,4,5,6);
JavaRDD rddData = sc.parallelize(data);
/*
* @第一个参数:withReplacement
* true:表示有放回的抽样;false:表示无放回的抽样;
* @第二个参数:fraction
* 抽取的百分比,例如下面的0.5就是抽取的50%的数据;
* @第三个参数:seed
* 随机种子;
*/
rddData.sample(true,0.5,9).foreach(System.out::println);
}
} 返回结果如下所示:
1
1
3
5
4.4.5.takeSample()
takeSample()函数和上面的sample函数是一个原理,但是不使用相对比例采样,而是按设定的采样个数进行采样,同时返回结果不再是RDD,而是相当于对采样后的数据进行Collect(),返回结果的集合为单机的数组。
图(4-4-5) 中左侧的方框代表分布式的各个节点上的分区,右侧方框代表单机上返回的结果数组。通过takeSample对数据采样,设置为采样一份数据,返回结果为V1。
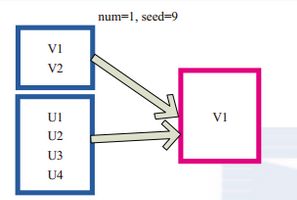
图(4-4-5)
演示代码如下所示:
/**
* TakeSample算子
* @author Ickes
*/
public class TakeSampleDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("TakeSample").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data = Arrays.asList(1,2,3,4,5,6);
JavaRDD rddData = sc.parallelize(data);
/*
* @第一个参数:withReplacement
* true:表示有放回的抽样;false:表示无放回的抽样;
* @第二个参数:num
* 抽取样本的个数
*/
rddData.takeSample(true,2).forEach(System.out::println);
}
}
返回结果如下所示:
6
1
4.5.Cache型
4.5.1.cache()
cache将RDD元素从磁盘缓存到内存,相当于persist(MEMORY_ONLY)函数的功能。
4.5.2.persist()
persist函数对RDD进行缓存操作。数据缓存在哪里由StorageLevel枚举类型确定。有以下几种类型的组合,如图(4-5-2),DISK代表磁盘,MEMORY代表内存,SER代表数据是否进行序列化存储。
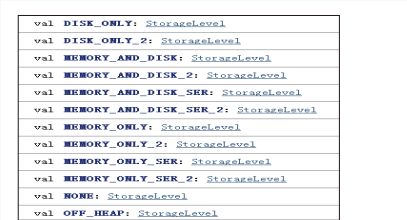
图(4-5-2)
例如,MEMORY_AND_DISK_SER代表数据可以存储在内存和磁盘,并且以序列化的方式存储。其他同理。
图(4-5-3)中的方框代表RDD分区。disk代表存储在磁盘,mem代表存储在内存。数据最初全部存储在磁盘,通过persist(MEMORY_AND_DISK)将数据缓存到内存,但是有的分区无法容纳在内存,例如:图(4-5-3)中将含有V1,V2,V3的RDD存储到磁盘,将含有U1,U2的RDD仍旧存储在内存
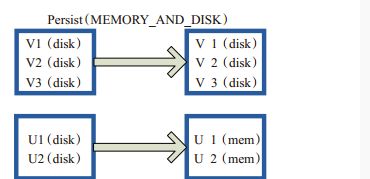
图(4-5-3)
缓存的演示代码如下所示:
/**
* Cache算子,缓存算子
* @author Ickes
*
*/
public class CacheDemo {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("Cache").setMaster(
"local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List data = Arrays.asList(1,2,3,4,5,6);
JavaRDD rddData1 = sc.parallelize(data);
JavaRDD rddData2 = sc.parallelize(data);
//cache缓存
rddData1.cache().foreach(System.out::println);
//persist缓存
rddData2.persist(StorageLevel.MEMORY_AND_DISK()).foreach(System.out::println);
}
}