pandas 快速入门教程
pandas 快速入门教程
- 学习目的
-
- 一、认识pandas
- 二、安装pandas
- 三、数据结构
- 四、导入Excel数据
- 五、输出Excel数据
- 六、数据概览
- 七、数据查看
- 八、数据清洗
- 九、数据选择
- 十、数据排序
- 十一、数据分组
- 十二、数据透视
- 十三、数据合并
- 十四、数据可视化
学习目的
通过学习pandas 撑握 处理excel 文件的技巧,提高日常工作中处理excel文件的效率。
一、认识pandas
pandas 是一个强大的数据处理工具集,它可以对数据进行清理、运算、统计、合并、数据分片等操作。
二、安装pandas
pip 安装pandas
首先确认系统已安装pip ,如未安装 可先安装pip
mac 系统:sudo easy_install pip
win 系统:python -m pip install -U pip
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
三、数据结构
pandas 数据结构分为:Series、DataFrame两种。
| 名称 | 描述 |
|---|---|
| Series | Series表示一维数据,可以简单理解为一个向量,但是不同于向量的是,Series会自动为这一维数据创建行索引。 |
创建Series
import pandas as pd
obj = pd.Series(['1','2','3','4'])
| 名称 | 描述 |
|---|---|
| DataFrame | dataframe是一种表格型的数据结构,既有行索引index,也有列索引columns。其实可以简单把dataframe理解为一张数据表。 |
创建DataFrame
import pandas as pd
#方法一 字典生成
d = {
'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data=d)
#方法二 文件生成
df = pd.read_excel("demo.xlsx")
#方法三 创建一个空DataFrame
df = pd.DataFrame(columns=["name","age","gender"])
四、导入Excel数据
方法一:
import pandas as pd
df = pd.read_excel("g:\\python\\sample\\pandas\\10.xlsx")
方法二:
import pandas as pd
excelFile = pd.ExcelFile("g:\\python\\sample\\pandas\\10.xlsx")
# 此方法 多用于从一个Excel文件 中获取多个sheet操作 较为方便,只需要修改sheet_name
df = pd.read(excelFile,sheet_name="sheet1")
#sheetList = excelFile.sheet_names 获取当前excel文件里的sheet 名 列表。["sheet1","sheet2"]
pd.read_excel(io,sheet_name,header)
| 参数名 | 描述 |
|---|---|
| io | 要读取的Excel文件。其形式(str, bytes, ExcelFile, xlrd.Book, path object, or file-like object) |
| sheet_name | 要读取的工作表名称(可以是整型数字、列表名) |
| header | 设定某一行为列名,默认值为0行。 |
五、输出Excel数据
方法一
import pandas as pd
# 将df 的数据生成一个excel文件,默认sheet_name为sheet1,也可以根据需要自定义。
df = DataFrame({
"name":["小张","小李"],"age":[18,20]}
df.to_excle(file_path) #file_path 文件存放路径+文件名
方法二
import pandas as pd
df1 = DataFrame({
"name":["小张","小李"],"age":[18,20]}
df2 = DataFrame({
"goods_name":["土豆","茄子"],"price":[1.3,3,5]})
excelWriter = pd.ExcelWriter(filePath) #file_path 文件存放路径+文件名
df1.to_excel(excelWriter,sheet_name="用户信息")#生成一个用户信息sheet
df2.to_excel(excelWriter,sheet_name="商品信息") #生成一个商品信息sheet
excelWrite.save()
excelWrite.close()
注:需要在一个excel中生成多个sheet的时候用第二种方法
DataFrame.to_excel(excel_writer, sheet_name=‘Sheet1’)
| 参数名 | 描述 |
|---|---|
| excel_writer | Excel文件路径字符串或者是ExcelWriter对像(如方法二) |
| sheet_name | 默认为‘Sheet1’,可自定义一个 sheet 名(字符串) |
六、数据概览
DataFrame为我们提供了两个非常好用的数据概览函数:
| 函数 | 描述 |
|---|---|
| info() | 展示数据概要信息(如索引、列数、列名、数据量、数据类型、缺失值、内存等) |
| describe() | 展示统计信息(统计结果包括了数据量、均值、方差、最大值、最小值等) |
代码示例
import pandas as pd
df = pd.read_excel("g:\\python\\sample\\pandas\\10.xlsx")
print df.info()
输出结果:

import pandas as pd
df = pd.read_excel("g:\\python\\sample\\pandas\\10.xlsx")
print df.describe()
print df.describe(include="all")
输出结果为:(第一个输出为不带参数的结果,第二是加入参数include="all"的结果,可对比查看区别

七、数据查看
在某些情况下我们只想看前N条数据或者后N条数据,可以通head()和tail()函数实现。
| 函数 | 描述 |
|---|---|
| head(n) | 查看前n条数据,默认查看前5条数据) |
| tail(n) | 查看后n条数据,默认查看后5条数据) |
代码示例:
#--coding:GBK
import pandas as pd
df = pd.DataFrame({
"name":[u"小红",u"小橙",u"小黄",u"小绿",u"小青",u"小蓝",u"小紫"]})
print "head() 函数 输出结果"
print df.head()
print "head(2) 函数 输出结果"
print df.head(2)
print "tail() 函数 输出结果"
print df.tail()
print "tail(3) 函数 输出结果"
print df.tail(3)
输出结果:

八、数据清洗
| 函数 | 描述 |
|---|---|
| dropna() | 删除含有空值的行或列 |
| repalce() | 数据替换 |
| apply() | 将自函数应用在行数据或列数据上 |
| fillna() | 自定义数据填充空值 |
1、dropna()函数应用
DataFrame.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
| 参数 | 描述 |
|---|---|
| axis | 指定操作轴,axis=0 是横坐标,axis=1是纵坐标。默认为0 |
| how | 删除方式 ,当how="any"时,行或列出现NA就删除,当how=“all"时 行或列全为NA时删除。默认为"any” |
| thresh | 指定出现NA的个数,例:thresh=2,当某一行或列出现两个NA值删除。 |
| subset | 指定列删除NA值。 |
代码示例:
import pandas as pd
import numpy as np
df = pd.DataFrame({
"name": ['Alfred', 'Batman', 'Catwoman'],"toy": [np.nan, 'Batmobile', 'Bullwhip'],"born": [pd.NaT, pd.Timestamp("1940-04-25"),pd.NaT]})
print "当前数据"
print df
print "删除含有NA值的行"
print df.dropna()
print "删除含有NA值的列"
print df.dropna(axis=1)
print "删除所有例都含有NA值的行"
print df.dropna(how='all')
print "删除含有2个NA值的行"
print df.dropna(thresh=2)
print "删除列['name', 'born']的行"
print df.dropna(subset=['name', 'born'])
输出结果为:

2、replace 函数应用
replace(to_replace=None, value=None)
常用参数
| 参数 | 描述 |
|---|---|
| to_replace | 准备被替换的值,值的类型(str, regex, list, dict, Series, numeric, or None) |
| value | 替换后的值,值的类型(str, regex, list, dict, Series, numeric, or None) |
代码示例
#--coding:GBK
import pandas as pd
df = pd.DataFrame({
'A': [0, 1, 2, 3, 4],
'B': [5, 6, 7, 8, 9],
'C': ['a', 'b', 'c', 'd', 'e']})
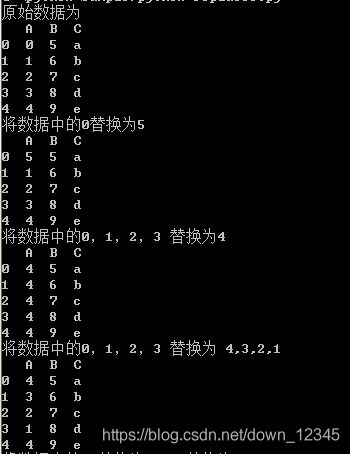
print "原始数据为"
print df
print "将数据中的0替换为5"
print df.replace(0, 5)
print "将数据中的0,1,2,3 替换为4"
print df.replace([0, 1, 2, 3], 4)
print "将数据中的0,1,2,3 替换为 4,3,2,1"
print df.replace([0, 1, 2, 3], [4, 3, 2, 1])
print "将数据中的 0替换为10,1替换为100"
print df.replace({
0: 10, 1: 100})
print "将A列的0,B列的5替换为100"
print df.replace({
'A': 0, 'B': 5}, 100)
print "将A列中的0,替换为100,4替换为400"
print df.replace({
'A': {
0: 100, 4: 400}})
输出结果为:

3、apply()函数的应用
apply(func,*args)
参数介绍
| 参数 | 描述 |
|---|---|
| func | 被调用的函数名 |
| args | 函数的参数,无组类型 |
代码示例
import pandas as pd
import numpy as np
print df
print "函数执行结果"
print df.apply(np.sqrt)
输出结果

4、fillna()函数应用
代码示列:
import pandas as pd
import numpy as np
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]],
columns=list('ABCD'))
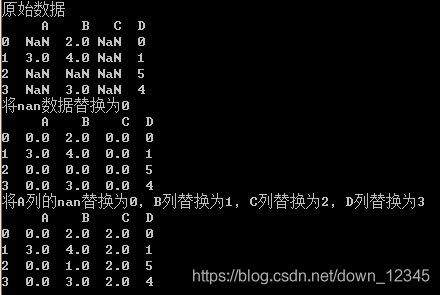
print "原始数据"
print df
print "将nan数据替换为0"
print df.fillna(0)
print "将A列的nan替换为0,B列替换为1,C列替换为2,D列替换为3"
print df.fillna(value={
'A': 0, 'B': 1, 'C': 2, 'D': 3})
输出结果
九、数据选择
在一个数据集中可以用loc()函数,iloc()函数,及条件查询获取部分数据。
1、loc(),iloc()函数介绍
| 函数 | 描述 |
|---|---|
| loc[行索引,列索引] | 通过索引获取数据,先行后列 |
| iloc[行位置,列位置] | 通过位置获取数据,先行后列 |
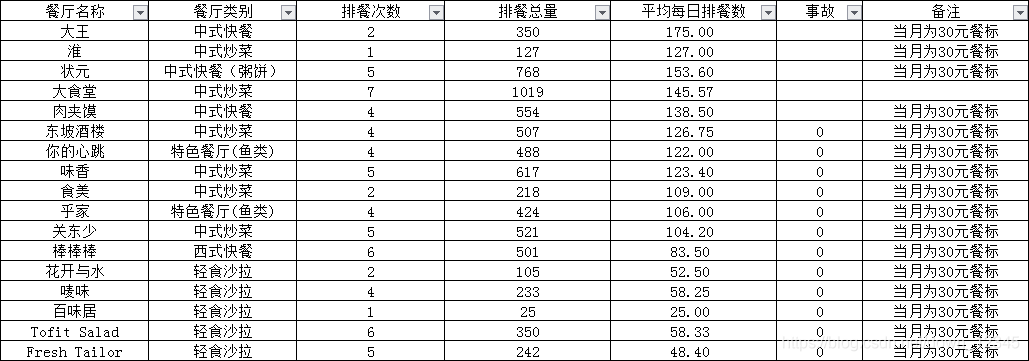
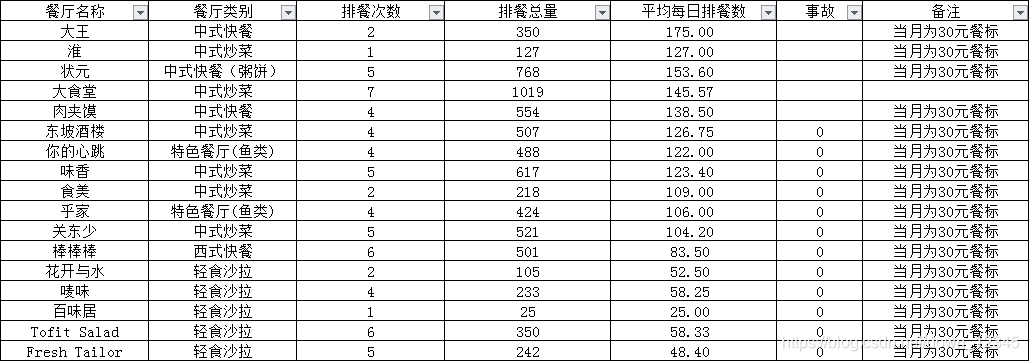
场景:从一个餐厅排餐表中获取指定的信息
loc 函数代码示例
import pandas as pd
#设置第一行,第0列(餐厅名称) 分别为列索引和行索引
df = pd.read_excel("g:\python\sample\pandas\8.xlsx",header=1,index_col=0)
#通过行索引【食膳美】的信息
print df.loc[u"食美"]
#获取【食膳美】餐厅的 u'排餐次数', u'排餐总量'信息
print df.loc[u"食美",[u'排餐次数', u'排餐总量']]
#获取列【u'排餐总量'】的所有信息
print df.loc[:,u'排餐总量']
#查看餐厅【食膳美,渝是乎】的排餐总量信息
print df.loc[[u"食美",u"乎家"],[u'排餐总量',u'平均每日排餐数']]
iloc()函数 代码示例
import pandas as pd
#设置第一行,第0列(餐厅名称) 分别为列索引和行索引
df = pd.read_excel("g:\python\sample\pandas\8.xlsx",header=1,index_col=0)
#通过行索引【食膳美】的信息
print df.iloc[8]
#获取【食膳美】餐厅的 u'排餐次数', u'排餐总量'信息
print df.iloc[8,[2, 3]]
#获取列【u'排餐总量'】的所有信息
print df.iloc[:,2]
#查看餐厅【食膳美,渝是乎】的排餐总量信息
print df.iloc[[8,9],[2,3]]
以上两个方式的输出结果为:

2、根据条件查询数据
场景:查询 排餐总量大于500 的中式快餐
代码示例:
#--coding:GBK
import pandas as pd
#设置第一行,第0列(餐厅名称) 分别为列索引和行索引
df = pd.read_excel("g:\python\sample\pandas\8.xlsx",header=1,index_col=0)
# 此处用 &(并且)|(或者)!(取反) 进行逻辑运算
dfResult = df[(df[u"排餐总量"]>500) & (df[u"餐厅类别"].isin([u'中式炒菜']))]
print dfResult
输出结果为:

十、数据排序
sort_values(by=[“col1”,“col2”,“coln”],ascending=False|True)
| 参数 | 描述 |
|---|---|
| by | 排序列名(可以单列或者多列) |
| ascending | True(升序:从小到大)False(降序:从大到小)默认True |
使用场景:
1、找出排餐总量前3的店铺
2、找出排餐总量最低的3个店铺
代码示列:
import pandas as pd
df = pd.read_excel("g:\python\sample\pandas\8.xlsx",header=1)
dfSort = df.sort_values(by=[u"排餐总量"],ascending=False)
#排餐前3家店
print dfSort.head(3)
#排餐后3家店
print dfSort.tail(3)
十一、数据分组
dataFrame.groupby(by=[“col1”,“col2”]))
| 参数 | 描述 |
|---|---|
| by | 分组的字段列表 |
数据分组就是根据一个或者多个字段将数据分成若干组,然后以分组后的数据进行统计运算(求和sum()、求平均值mean()、最大值 (max())、最小值(min()) 、个数(count()等)
例如:有一个考试成绩单分别算出每个人的考试总成绩

代码示例:
import pandas as pd
#读取Excel成绩单数据
df = pd.read_excel("g:\python\sample\pandas\8.xlsx",sheet_name="Sheet2")
#根据姓名字进行成绩汇总
#方式一
dfsum1 = df.groupby(by=[u"姓名"]).sum()
#输出汇总结果
print dfsum1
# 方式二 通过agg函数
dfsum2 = df.groupby(by=[u"姓名"]).agg({
u"分数":sum})
print dfsum2
#agg() 可以指定进行运算的字段名,且可以对一个字段同时进行多个运算。
#统计 考生的总成绩,最高分、最低分
print df.groupby(by=[u"姓名"]).agg({
u"分数":[sum,max,min]})
输出结果为:

注:建议使用agg()函数进行统计运算,agg支持一列多种运算,同时也可以支持多列实现不同的运算。
agg()函数格式:agg({col:max,col2:sum,col3:[sum,min,max]})
十二、数据透视
数据透视表是一个很重要的数据处理功能,通过对行、列的拆分使得能更好的体现业务数据。
在pandas 中,用pivot_table()函数实现数据透视功能。
pandas.pivot_table()
| 参数 | 描述 |
|---|---|
| data | 透视数据 |
| index | 行索引对应Excel中的行 |
| columns | 列索引对应Excel中的列 |
| values | 进行运算分析的值 |
| aggfunc | 对values进行运算的函数。如:sum,max,count,min,mean |
| margins | 添加行列的统计,默认不显示。 |
| magrin_names | 在margins参数为ture时,用来修改margins的名称 |
| fill_value | 填充NA值。默认不填充 |
案例:现有两家车行多种车型1月份2月份的销售数据,分析出各车型在1月份,2月份的销售情况。并保存到Excel表中。
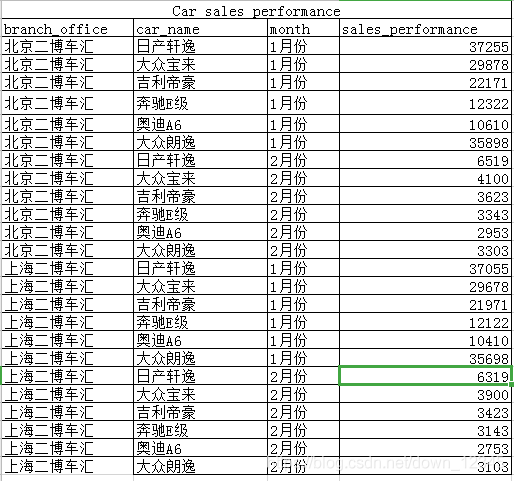
#--coding:GBK
import pandas as pd
df = pd.read_excel("G:\python\sample\pandas\pivot_data.xlsx",header=1)
#分析不同车型在1,2月的销售性况以及各车型1月份,2月份的销售总量
pivData=pd.pivot_table(df,index="car_name",columns=["month"],values=["sales_performance"],aggfunc="sum",margins=True)
pivData.to_excel("G:\pivData.xlsx")
输出结果:
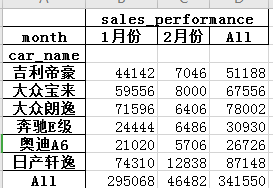
注意事项:
#margin 的运算规则
#不是简单地求和,而是与 aggfunc 的规则相同
#如果 aggfunc=np.mean,则 margin 的值也是"求平均值"
#如果 aggfunc=np.sum,则 margin 的值也是"求和"
十三、数据合并
数据的合并在pandas中分为横向合并与纵向合并。
横向合并用merge()函数 等同于Excel的vlookup,SQL的join
纵向合并用concat()函数,将多个数据纵向合并到一起。
1、pandas.merge()函数
| 参数 | 描述 |
|---|---|
| left | 左边的DataFrame |
| right | 右边的DataFrame |
| on | 关联列名,列名必须同时存在于 左右两个DataFrame中 |
| left_on | 指定 左边的 要关联的列名 |
| right_on | 指定 右边的 要关联的列名 |
| how | 合并方式(inner,outer,left,rigth)默认为inner |
案例:分析用户在某电商平台的购物情况
一个用户数据表,一个订单数据表。将两个表进行合并为一张新含有用户信息及订单信息的新表
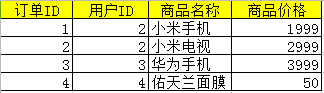
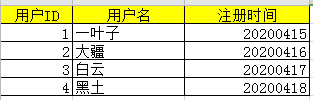
代码示例
import pandas as pd
dfUser = pd.read_excel("G:\python\sample\pandas\user.xlsx")
dfOrder = pd.read_excel("G:\python\sample\pandas\order.xlsx")
dfNew = pd.merge(dfuser,dfOrder)
dfNew.to_excel("G:\python\sample\pandas\user-order.xlsx")
输出结果

只将 用户名、商品名称、商品价格 列进行合并
dfNew = pd.merge(dfUser[[u"用户ID",u"用户名"]],dfOrder[[u"商品名称",u"商品价格",u"用户ID"]])
输出结果:
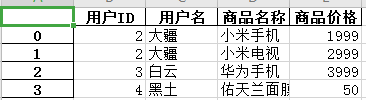
2、concat()函数
| 参数 | 描述 |
|---|---|
| objs | 需要连接的对象集合,一般是列表或字典[df1,df2…] |
| join | join = ‘inner’,则说明为取交集,join = ‘outer’,则说明为取并集, |
| ignore_index | boolean,default False。如果为True 合并后的数据重新生成索引 |
案例:有两个Excel,分别是2018年网贷数据、2019年网贷数据,将两个年份的数据合并到一张Excel中。

示例
import pandas as pd
df2018 = pd.read_excel("G:\\python\\sample\\pandas\\2018.xlsx")
df2019 = pd.read_excel("G:\\python\\sample\\pandas\\2019.xlsx")
dfnew =pd.concat([df2018,df2019],ignore_index=True)
dfnew.to_excel("G:\\python\\sample\\pandas\\20189.xlsx")
输出结果:

十四、数据可视化
在数据分析中,数据可视化能够清晰的表达出数据的趋势,方便数据使用者分析。
DataFrame.plot()函数
| 参数 | 描述 |
|---|---|
| x | X轴数据 |
| y | Y轴数据 |
| title | 图表标题 |
| kind | 图表类型(‘line’ t (default)#折线图,bar(条形图) 等) |
案例: 分析某网站的用户注册趋势

代码示例
#--coding:GBK
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel("G:\\python\\sample\\pandas\\userRe.xlsx")
print df
#解决中文乱码问题
plt.rcParams['font.sans-serif']=['SimHei']
#设置图表类型为柱图,横轴为日期,图表标题
df.plot(kind="bar",title=u"用户注册分析",x=u"日期")
plt.show()#显示图表
输出结果:
