利用python爬虫(案例8)--今天就是吃X我也要搞到有道
学习笔记
备注:这个Blog也是part14
爬取有道
写个案例,我想要破解有道翻译(http://fanyi.youdao.com/)接口,抓取翻译结果。
一开始,我还以为写这个不是很麻烦,因为2年前玩网爬的时候,最先写的小案例就是爬取翻译结果。但是现在,我重新写一遍,不知道为啥,研究了半天,心力交瘁,可能是人老了。
爬取步骤
①获取要爬取的有道翻译URL地址(http://fanyi.youdao.com/)
②在有道页面中翻译单词,抓取数据包
③查看,并解析FROM表单
④敲python代码,输入要翻译的内容,发送post请求
⑤得到翻译结果
熟悉抓包
在正式开始抓包之前,我们先熟悉一下怎么抓包
备注:抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。
在Chrome浏览器中,进入抓包的网站(比如:有道), 开启网络抓包(右键打开审查元素–>点击Network–>点击All),与网站进行交互(比如:在有道中翻译兔子一词):
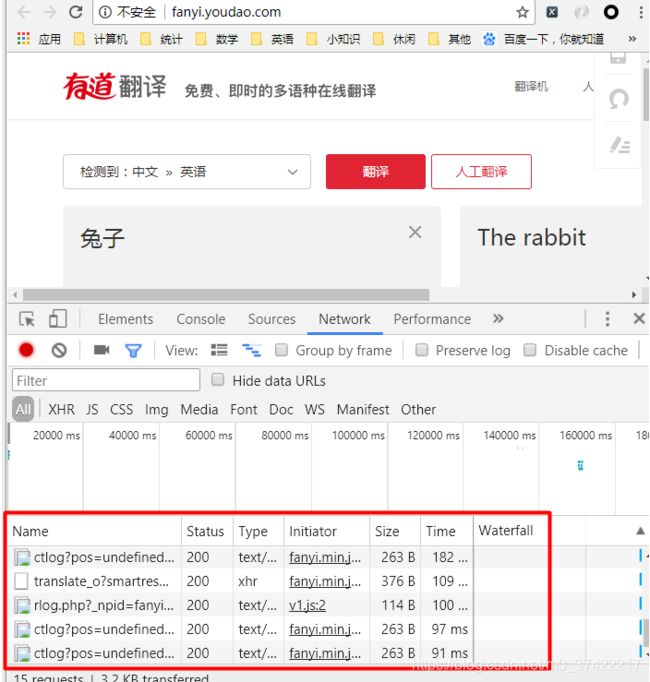
图片中,被红框框起来的部分,就是我们和有道交互的过程中产生的数据包。我们要进行网络抓包,就是要从这么一大堆数据包里,找到有用的数据包。
我们再来分析一下各个选项:
【Headers选项】可以查看基本请求信息、我们提交的请求头、响应头和查询参数。

如果该数据包是因为我们发送了POST请求而抓到的,那么它的Headers里会出现FROM表单信息:

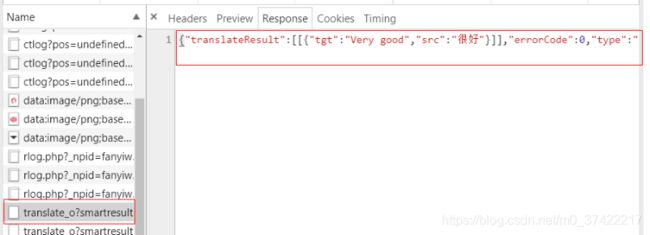
【preview】选项可以进行预览。我们通过预览,可以判断该数据包里有没有包含我们想要的数据(预览的数据经过了格式化):

【response】选项提供给我们,没有经过任何修饰的网站响应(网站响应的源码):
正式开始抓包
我们打开有道翻译后,右键打开审查元素–>点击Network–>点击XHR(我们要的数据包主要在这里)–>在有道翻译的页面中,输入Bunny, book, pen–>获取数据包:
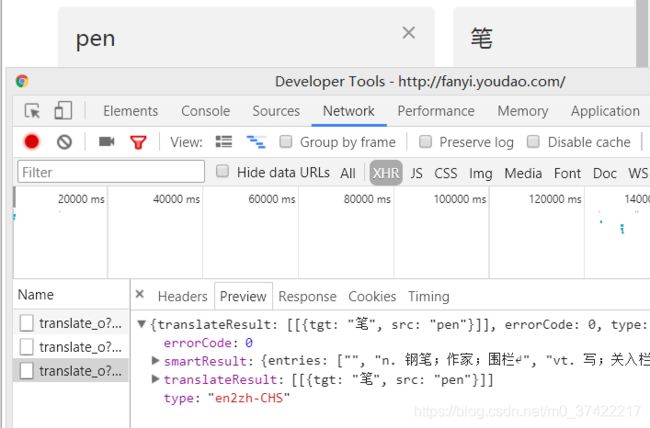
查看数据包的头部信息:

可以看到,我们向 http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule发送请求,请求方式是POST请求。如果我们发送POST请求,则Headers中一定会有FORM表单数据(FROM Data),而服务端则会对我们发送的FROM表单进行验证,如果表单验证不通过,我们拿不到想要的返回结果。
解析FROM表单
现在我们仔细研究一下,这些FROM表单数据:
i:Bunny
from:AUTO
to:AUTO
smartresult:dict
client:fanyideskweb
salt:15874435880336
sign:9010a72e07b45d70c18b3bc640006e27
ts:1587443588033
bv:cda24c3e62de8f471433417161b17a55
doctype:json
version:2.1
keyfrom:fanyi.web
action:FY_BY_REALTlME
可以看到,参数i对应的应该是我们要翻译内容,但是其他一堆堆的参数是啥呢???尤其是下面这些参数:
salt:15874435880336
sign:9010a72e07b45d70c18b3bc640006e27
ts:1587443588033
bv:cda24c3e62de8f471433417161b17a55
这一堆堆的数字,看的眼花,好像毫无头绪啊!
现在咋整呢?
我们之前不是抓了3个数据包么,那么咱就把每个数据包中FROM表单里的参数值都瞧上一瞧。看一看哪些参数的参数值没有变化,那么我们就不处理它,哪些参数的参数值有变化,那我们就针对它。
我们看看 book和pen所对应的FROM表单:
i:book
from:AUTO
to:AUTO
smartresult:dict
client:fanyideskweb
salt:15874437157104
sign:a4f482196c44b53e9f8dea18f18dd446
ts:1587443715710
bv:cda24c3e62de8f471433417161b17a55
doctype:json
version:2.1
keyfrom:fanyi.web
action:FY_BY_REALTlME
i:pen
from:AUTO
to:AUTO
smartresult:dict
client:fanyideskweb
salt:15874437391707
sign:f22542cea9aad0e1c1ca53ccc6093772
ts:1587443739170
bv:cda24c3e62de8f471433417161b17a55
doctype:json
version:2.1
keyfrom:fanyi.web
action:FY_BY_REALTlME
对比这3个FROM表单,我们把参数值一样的参数去掉,不一样的留下:
i:pen
salt:15874437391707
sign:f22542cea9aad0e1c1ca53ccc6093772
ts:1587443739170
我们需要仔细研究一下这些参数的产生方式,或者说我们怎么才能获取这些参数值。
我们已经知道,第一个参数i,它对应的是要翻译的内容。
那其他参数呢,比如salt、sign、ts
当我们访问有道翻译网站时,服务端会给予我们响应,在响应中有很多JS文件,则salt、sign、ts这些参数的值,就是由这些JS文件生成的。所以,我们想要得到这些参数值,就要找到这些JS文件。
怎么找到这些JS文件呢?
我们可以刷新一下页面,点击审查元素–>Network–>JS,来寻找JS文件:
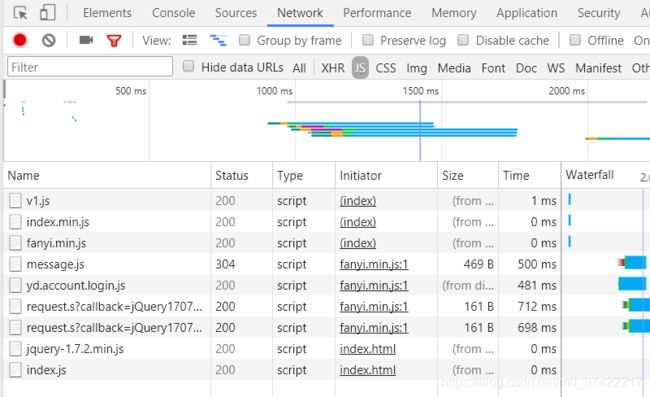
我们看到了一堆JS文件。
那这些文件里面,哪些使我们想要的JS文件呢?
我们可以在这些JS文件中,搜索From表单里出现的参数名。先搜索salt看看能得到些什么吧:

我们得到了一个JS文件,这个文件中有salt参数,我们在这个文件中继续查找有没有FROM表单里的其他参数(比如sign和ts)
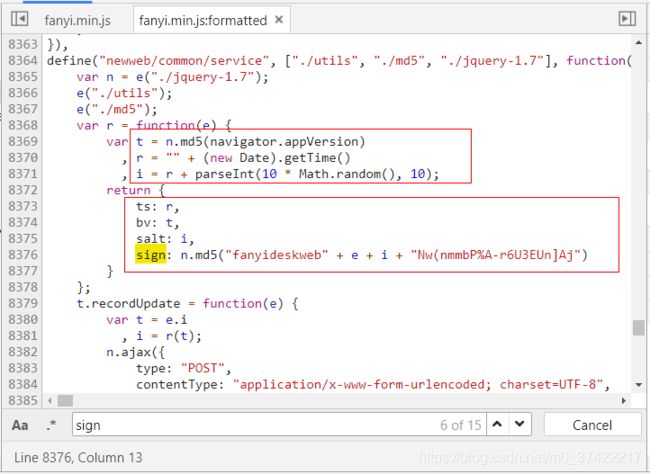
我们在这个JS文件中, 找到了FROM表单里的参数ts、bv、salt、sign, 看看这些代码(虽然看不懂),貌似是对参数进行某种md5加密, 还有生成随机数,貌似还有时间戳?
这些是啥啊…喵的, 烦!
哎。。不管,好不容易有点头绪,我们先把这些语句copy下来:
t = n.md5(navigator.appVersion)
r = "" + (new Date).getTime()
i = r + parseInt(10 * Math.random(), 10);
ts: r,
bv: t,
salt: i,
sign: n.md5("fanyideskweb" + e + i + "Nw(nmmbP%A-r6U3EUn]Aj")
copy这些JS语句有啥用呢?
为的就是按照这些js语句的意思,用python的语法把FROM表单里的参数值重现出来。 呵呵!简单粗暴。
那么我们如何弄明白这些JS语句的意思呢?
进行测试啊!来吧,拿起我们的小手手,在Console中一行一行代码的研究这些JS语句是啥意思。

navigator.appVersion语句生成的东西和我们的User-Agent好像啊。我们验证一下:
User-Agent:Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36
石锤了!navigator.appVersion语句可以生成User-Agent中Mozilla/后面的东西。这就是为啥bv参数不变的原因,因为我发起请求时的User-Agent一直没变,所以用User-Agent进行md5加密得来的bv参数也不会变。

"" + (new Date).getTime()语句貌似可以拿到时间戳。

看来parseInt(10 * Math.random(), 10)语句貌似可以生成0到9的随机数
好了,更关键的来了!现在我想要在Console中测试代码"fanyideskweb" + e + i + "Nw(nmmbP%A-r6U3EUn]Aj",这貌似只是简单的字符串拼接啊,有啥可看的。
是简单的拼接没错,但是我它喵的不知道e是啥,这该咋办!?
看那一坨坨的JS代码,把e找出来?…对不起,我有点晕,臣妾做不到…那咋整?那就,断点调试吧…咋调试呢?
我们在如下图所示的8378行打一个断点,并在有道页面里输入一些要翻译的内容,比如English:

神奇的事情发生了!我们的屏幕上跳出了我想要的答案:e = “English”
通过断点调试,我们知道了,这个e所代表的的就是我想要翻译的内容。
敲代码啦!
那么我们做了那么多现在可以敲python代码了么?

可以!但咱是先别爬,咱们先把FROM表单里salt、sign、ts参数值,用python重现一下…MD…保持微笑.JPG
用python重现FROM表单参数值的代码:
import time
import random
from hashlib import md5
ts = str(int(time.time()*1000))
salt = ts + str(random.randint(0,9))
s = md5()
e = input('输入要翻译的内容:')
sign = "fanyideskweb" + e + salt + "Nw(nmmbP%A-r6U3EUn]Aj"
s.update(sign.encode())
#update的参数为byte数据类型
md5_sign = s.hexdigest()
现在可以爬了么???
不好意思,我还想介绍一下requests.post方法。

requests.post方法
请求有很多类别,比如有GET、POST、HEAD、PUT等等。现在,我们就是要用python的requests.post方法向服务端发起POST请求。一般,当我们向网站提交一定的信息,想得到反馈(比如,想要注册账号,英汉翻译)时,就要用到POST请求。
- 语法
response = requests.post(url,data=formdata,headers=headers)
#formdata:要post(提交)的FROM表单数据,字典格式
爬虫啦
好了,现在我们开始爬吧.
python代码:
# -*- coding: utf-8 -*-
import requests
import time
import random
from hashlib import md5
import json
class YoudaoSpider:
def __init__(self):
self.url = ' http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
self.proxy = ['{}://117.88.176.93:3000',
'{}://117.88.177.153:3000',
'{}://60.188.77.31:3000']
self.headers = {
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Content-Length':'255',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'[email protected]; OUTFOX_SEARCH_USER_ID_NCOO=645870110.9638431; _ntes_nnid=75e99ed4fe9cecbb947a8df8ea8b8885,1526958441068; P_INFO=m18155501928; _ga=GA1.2.45220094.1586593751; JSESSIONID=aaa5TmtwK5mCi7b8j-Agx; SESSION_FROM_COOKIE=unknown; ___rl__test__cookies=1587469540366',
'Host':'fanyi.youdao.com',
'Origin':'http://fanyi.youdao.com',
'Referer':'http://fanyi.youdao.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
def get_parameter(self, word):
ts = str(int(time.time()*1000))
salt = ts + str(random.randint(0,9))
s = md5()
sign = "fanyideskweb" + word + salt + "Nw(nmmbP%A-r6U3EUn]Aj"
s.update(sign.encode())
#update的参数为byte数据类型
sign = s.hexdigest()
return salt,sign,ts
def post_data(self, word):
salt,sign,ts = self.get_parameter(word)
formdata = {
'i':word,
'from':'AUTO',
'to':'AUTO',
'smartresult':'dict',
'client':'fanyideskweb',
'salt':salt,
'sign':sign,
'ts':ts,
'bv':'cda24c3e62de8f471433417161b17a55',
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_CLICKBUTTION'
}
proxy = random.choice(self.proxy)
proxies = {
'http':proxy.format('http'),
'https':proxy.format('https')}
html_json = requests.post(
url = self.url,
data = formdata,
headers = self.headers,
proxies = proxies
).json()
#print(type(html_json))
result = html_json['translateResult'][0][0]['tgt']
print('翻译结果:', result)
def main(self):
word = input('输入要翻译的内容:')
self.post_data(word)
if __name__ == '__main__':
start = time.time()
spider = YoudaoSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end-start))
控制台输出:
输入要翻译的内容:垂耳兔
翻译结果: The loppy eared rabbit
执行时间:7.91
后记:写了这篇案例导致我想学CSS、JS和数据结构了,但还要复试。呵呵,说好的复试之前绝不写案例呢?辣鸡!