- 【RabbitMQ】RabbitMQ中死信交换机是什么?延迟队列呢?有哪些应用场景?
熏鱼的小迷弟Liu
中间件rabbitmqruby分布式
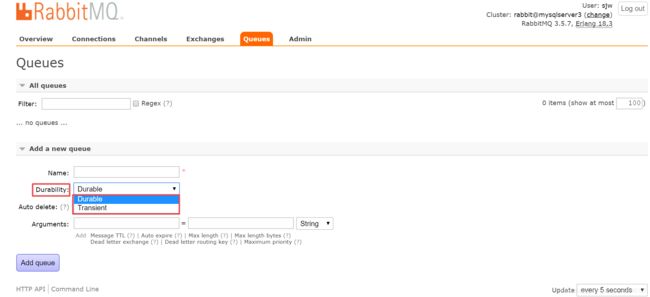
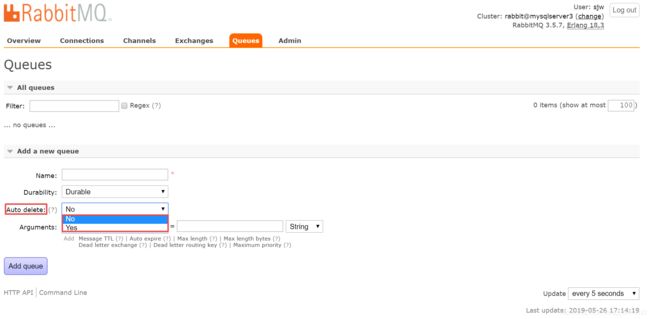
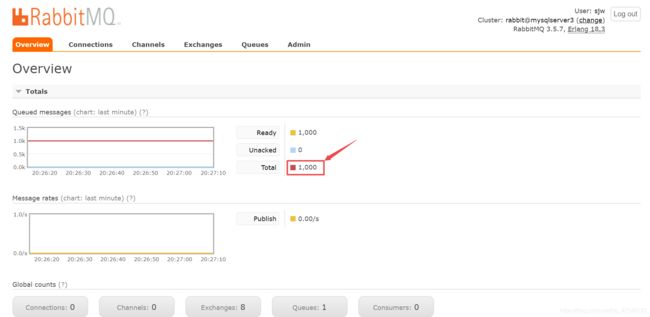
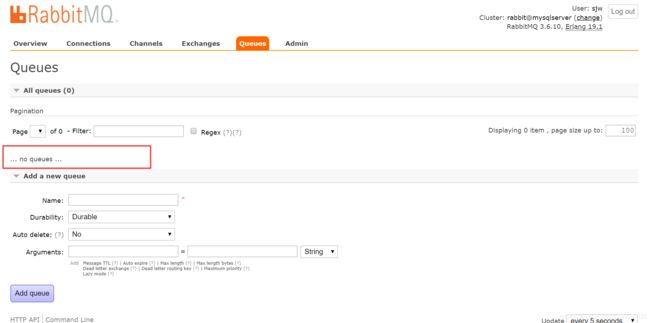
1.死信交换机(DeadLetterExchangeDLX)1.1什么是死信交换机?死信:在RabbitMQ中,无法被消费者正常处理的消息称为死信(DeadLetter)。死信交换机:用于接收死信的交换机。当消息成为死信时,RabbitMQ会将其重新路由到死信交换机,再由死信交换机根据绑定规则路由到死信队列。1.2消息成为死信的条件1.消息被拒绝:消费者调用basic.reject或basic.n
- 【RabbitMQ】RabbitMQ如何保证消息不丢失?
熏鱼的小迷弟Liu
中间件rabbitmq分布式
为了保证消息不丢失,需要在生产者、RabbitMQ本身和消费者三个环节采取相应措施。1.生产者端:确保消息发送成功1.1开启消息确认机制(PublisherConfirms)原理:生产者发送消息后,RabbitMQ会返回一个确认(ACK),表示消息已成功接收。1.2开启事务机制(Transactions)原理:生产者发送信息后,可以通过事务机制确保信息被成功接收。注意:事务机制性能较低,推荐消息确
- RabbitMQ支持的复杂的消息交换模式
啊sen丶
rabbitmq分布式
RabbitMQ支持多种复杂的消息交换模式,这些模式通过不同的交换机类型和队列特性实现,能够满足多样化的业务需求。以下是RabbitMQ支持的主要复杂消息交换模式:1.DirectExchange(直连交换机)直连交换机根据消息的路由键(RoutingKey)将消息路由到与该路由键绑定的队列。如果一个队列绑定了多个路由键,它将接收所有匹配的消息。-特点:简单直接,一对一匹配。-适用场景:适用于消息
- RabbitMQ中如何确保你的消息只被消费一次
昔我往昔
MQrabbitmqruby分布式
在SpringBoot项目中,确保RabbitMQ消息只被消费一次是一个常见且重要的问题。为了确保消息在RabbitMQ中只被消费一次,我们通常依赖于消息确认机制(acknowledgment),以及幂等性设计。以下是一些常见的做法来实现这一目标。1.使用消息确认机制(Ack)RabbitMQ提供了消息确认机制,允许消费者在成功处理消息后通知RabbitMQ服务器。这可以确保在消息消费完成前,不会
- 【开题报告+论文+源码】基于SpringBoot+Vue的社区团购配送系统
编程毕设
springboot后端java
项目背景与意义随着社会的进步和收入的提高,消费者对购物体验有了更高的要求。他们希望获得更多样化的商品选择,更加便捷的购物方式,以及更加优质的售后服务。同时,越来越多的老年人开始关注健康饮食和食品质量。他们不再满足于传统的购物方式,而是希望通过更加方便的方式来获取更加安全和健康的食品。社区团购配送系统在满足用户日常生活需求的同时,也带来了许多便利和机遇。项目介绍本课程演示的是一款基于SpringBo
- Node.js 中使用 RabbitMQ
海上彼尚
node.jsnode.jsrabbitmq分布式
目录一、RabbitMQ简介二、核心概念解析三、环境搭建(以Ubuntu为例)四、Node.js实战:生产者与消费者1.安装依赖2.生产者代码(发送消息)3.消费者代码(处理消息)五、高级配置与最佳实践六、常见问题与解决方案七、总结一、RabbitMQ简介RabbitMQ是一个基于AMQP协议的开源消息代理工具,专为分布式系统设计。它通过解耦生产者和消费者实现异步通信,支持流量削峰、任务队列、服务
- Lianwei 安全周报|2024.12.9
联蔚盘云
安全
新的一周又开始了,以下是本周「Lianwei周报」,我们总结推荐了本周的政策/标准/指南最新动态、热点资讯和安全事件,保证大家不错过本周的每一个重点!政策/标准/指南最新动态01美国消费者金融保护局提案:限制“数据经纪人”出售个人信息当地时间12月3日,美国消费者金融保护局(CFPB)宣布,计划针对“数据经纪人”出售美国人个人信息的行为,出台更加严格的监管措施。根据新提案,“数据经纪人”将受到更加
- Kafka系列之—向Kafka 写入数据(四)
葛旭朋
Kafkakafka分布式java
一,创建Kafka生产者1.1必选的三个属性1.1.1bootstrap.servers指定broker的地址清单,不需要包含所有的broker地址,生产者会从给定的broker里找到其它broker的信息,建议最少提供两个broker的信息。1.1.2key.serializerbroker希望接收到的消息的键和值都是字节数组。1.1.3value.serializer指定的类会将值序列化。1.
- Kafka 数据写入问题
喝醉酒的小白
DBAkafka分布式
目录标题分析思路1.**生产者配置问题**:Kafka生产者的配置参数生产者和消费者的处理确定并优化2.**网络问题**:3.**Kafka集群配置问题**:unclean.leader.election.enable4.**Zookeeper配置问题**:5.**JVM参数调优**:6.**副本因子和同步复制**:分析思路针对您提到的Kafka数据写入问题,以下是一些具体的原因和排查命令:1.生
- 【Kafka】Kafka写入数据
此木|西贝
Kafkakafka分布式
不管是把Kafka作为消息队列还是数据存储平台,总是需要一个可以往Kafka写入数据的生产者,一个可以从Kafka读取数据的消费者。生产者创建一个ProducerRecord对象,包含目标topic和发送的内容;另外可以指定键、分区、时间戳或标头对数据进行分区;如果没有显示指定分区,数据将会传给分区器,确定往哪个主题和分区发送数据。消息添加到一个消息批次,该批次所有的消息被发送到同一个主题和分区;
- docker 部署 RabbitMQ
嗑瓜子儿溜茶水儿
dockerdockerrabbitmq容器
命令dockerrun-d--name=rabbitmq\-p5671:5671-p5672:5672-p4369:4369\-p15671:15671-p15672:15672-p25672:25672\-eRABBITMQ_DEFAULT_USER=username\-eRABBITMQ_DEFAULT_PASS=password\-v/usr/local/rabbitmq/data:/var
- docker部署rabbitMQ
人间有清欢
dockerdockerrabbitmq
docker部署rabbitMQ如果用目录挂载会启动失败,要用数据卷挂载。dockerpullrabbitmq:3.8-management#挂载数据卷-vmq-plugins:/plugins\#设置主机名--hostnamemq\dockerrun\-eRABBITMQ_DEFAULT_USER=rabbitmq\-eRABBITMQ_DEFAULT_PASS=1234\-vmq-plugin
- Docker 部署RabbitMQ
逢生博客
dockerrabbitmq容器springboot
文章目录镜像docker-compose.yml访问控制台SpringBoot批量声明队列镜像https://hub.docker.com/_/rabbitmqdockerpullrabbitmq:managementdockerpullrabbitmq:4.0.7-managementdocker-compose.ymlservices:rabbitmq:image:rabbitmq:3.9.5
- 第十三章 Java多线程——阻塞队列
龙少丶
javajava开发语言
13.1阻塞队列的由来我们假设一种场景,生产者一直生产资源,消费者一直消费资源,资源存储在一个缓存池中,生产者将生产的资源存进缓存池中,消费者从缓存池中拿到资源进行消费,这就是大名鼎鼎的生产者-消费者模式。该模式能够简化开发过程,一方面消除了生产者与消费者类之间的代码依赖性,另方面将生产数据的过程与使用数据的过程解耦简单化负载。我们⾃⼰coding实现这个模式的时候,因为需要让多个线程操作共享变量
- RabbitMQ 和 Redis 的选择
一条小小yu
rabbitmqredis
在处理大规模消息场景时,RabbitMQ和Redis的选择需根据具体需求权衡。大规模消息场景的关键考量吞吐量需求:Redis:更适合超高频写入(如百万级/秒),但需牺牲部分可靠性。RabbitMQ:稳定吞吐(数十万级/秒),适合长期高负载但无需极限性能的场景。消息可靠性:必须持久化→选RabbitMQ(内置持久化+多节点集群)。可容忍丢失→Redis(依赖AOF/RDB,但集群部署需注意一致性)。
- kafka相关问题
给我个面子中不
Java学习kafka分布式java
Kafka通过事务机制与幂等性功能相结合,实现了跨会话的幂等性。以下是详细解释:kafka是怎么通过事物保证跨会话的幂等性?1.幂等性与跨会话幂等性幂等性:指相同的操作被执行多次,其结果是一样的。在Kafka中,主要是指生产者发送相同的消息不会导致重复。跨会话幂等性:在生产者会话关闭并重启后,Kafka仍能保证发送的消息不会被重复处理。2.Kafka的幂等性原理Kafka的幂等性主要通过Produ
- Python 数据分析实战:电动汽车行业发展态势与市场策略洞察
萧十一郎@
pythonpython数据分析开发语言
目录一、案例背景二、代码实现2.1数据收集与导入2.2数据探索性分析2.3数据清洗2.4数据分析2.4.1市场规模与增长趋势2.4.2消费者需求分析2.4.3企业竞争格局2.4.4政策影响分析2.4.5构建消费者购买意愿预测模型三、主要的代码难点解析3.1数据收集与导入3.2数据清洗-缺失值处理3.3数据清洗-异常值处理3.4数据分析-消费者需求分析3.5数据分析-构建消费者购买意愿预测模型四、可
- ActiveMQ 监听器
闲_风
activeMQactiveMQ监听器注册监听
监听器,由消息的消费者注册监听,去监听消息队列(queue)中的消息,监听到有消息未处理,即自动调用onMessage方法处理消息,监听器可以注册多个,ActiveMQ自动循环调用注册的监听器,处理队列中的消息。在消息的消费者方,使用setMessageListener方法注册监听,传入匿名参数newMessageListener(),复写onMessage(Messagemessage)方法,在
- 线程协作全攻略:5大核心机制破解并发编程难题
程序猿小白菜
后端java生态圈线程java线程协作
引言:从生产者-消费者问题看线程协作本质在电商订单处理系统中,每秒需处理数万个订单的创建与物流信息更新。当生产者线程与消费者线程因处理速度差异导致系统吞吐量骤降时,如何实现高效协作成为关键。本文将揭秘Java线程协作的五大核心机制,并通过工业级案例展示其应用场景。一、基础同步机制1.1等待通知机制(Wait/Notify)//经典生产者实现publicsynchronizedvoidproduce
- Kafka 同步机制关键点 2分钟讲明白
大博士.J
kafka
ApacheKafka通过副本同步机制来保证数据的高可用性和可靠性。Kafka的同步机制主要涉及以下几个核心概念:副本(Replication)Kafka的每个Partition都会有多个副本(Replica),分为:Leader副本:负责处理生产者和消费者的所有请求。Follower副本:仅从Leader同步数据,不直接处理请求。副本数由replication.factor参数配置。例如:rep
- 扫盲系列--Web3智能合约+Solidity简介
「已注销」
前端框架
前言这几天web3智能合约这个概念,频繁映入我的眼帘。web3.0这个概念我听说过,核心特征是去中心化、开放性、隐私保护和数据所有权回归个人。Web1.0是信息浏览时代,Web2.0是用户参与和社交网络时代,Web3.0是去中心化与智能化时代。在Web3.0这一新的互联网架构下,用户不再仅仅是内容的消费者,更是自己数字身份和数据的拥有者。Web3.0旨在构建一个更加透明、安全且高效的信息网络。我对
- c++11新特性之条件变量
要好好养胃
c++11c++开发语言
文章目录条件变量1condition_variable1.1成员函数wait()2condition_variable_any条件变量互斥锁:放行一个线程,阻塞N个线程条件变量:放心n个线程,阻塞N个线程,主要使用场景:生产者-消费者模型1condition_variable只能使用独占的互斥锁,并且还得配合unique_lock1.1成员函数wait()//①voidwait(unique_lo
- Debezium系列之:使用Debezium采集oceanbase数据库
快乐骑行^_^
debeziumDebezium系列采集oceanbase数据库
Debezium系列之:使用Debezium采集oceanbase数据库一、oceanbase数据库二、安装OceanBase三、安装oblogproxy四、基于Docker的简单采集案例五、生产实际应用案例Debezium是一个开源的分布式平台,用于监控数据库变化和捕捉数据变动事件,并以事件流的形式导出到各种消费者。Debezium基于ApacheKafka实现,并支持多种数据库系统。一、oce
- 美容院如何通过数据分析降低顾客流失率
shboka920702
信息可视化
美容行业的竞争日益激烈,顾客流失率居高不下已成为许多美容院面临的共同难题。根据《美容行业经营分析报告》的数据,美容行业的平均顾客流失率高达40%,这意味着每10位顾客中就有4位在一年内不再光顾。如何通过数据分析降低顾客流失率,成为美容院经营者亟需解决的问题。顾客流失的原因多种多样,主要包括服务质量、价格、环境、竞争对手等。根据《消费者行为研究》期刊的调查,超过50%的顾客流失是由于服务质量不达标,
- 使用 .NET Core 实现 RabbitMQ 消息队列的详细教程
江沉晚呤时
Netcore开发语言后端c#.netcore
RabbitMQ是一个流行的消息队列中间件,它允许应用程序通过异步消息的方式进行通信。RabbitMQ支持AMQP协议,可以通过多种方式与应用程序交互。在本教程中,我们将深入探讨如何在.NETCore环境中使用RabbitMQ来实现消息队列。我们将学习如何在生产者端发送消息,消费者端接收消息,并确保消息的可靠性。目录安装和配置RabbitMQ安装RabbitMQ客户端库创建生产者(Producer
- 3.7 Spring Boot整合Kafka:消息顺序性与消费幂等性保障
Sendingab
Springboot从入门到精通零基础7天精通SpringBootlinqc#springbootkafka
在SpringBoot中整合Kafka并保障消息顺序性与消费幂等性,可以通过以下步骤实现:一、消息顺序性保障1.生产者配置相同Key写入同一分区:Kafka保证同一分区内消息的顺序性,生产者发送消息时指定相同Key,确保相关消息进入同一分区。java@AutowiredprivateKafkaTemplatekafkaTemplate;publicvoidsendMessage(Stringkey
- RabbitMQ应用问题大全(精心整理版)
ngioig
RabbitMQmicrosoftspringrabbitmq分布式
前言其实这部分知识我是整理在语雀上了,这里是直接复制粘贴过来的。不是很好阅读,可以直接点下方链接去语雀看,那个看的会舒服很多。https://www.yuque.com/g/ngioig/upbg6b/fkarhyo8fpgrtyq8/collaborator/join?token=GvlO0di8KaIfO8aF&source=doc_collaborator#《RabbitMQ常见问题知识库》
- 队列在计算机系统中的应用
AredRabbit
队列
队列在计算机系统中有广泛的应用,主要用于管理任务和处理数据流。以下是队列的一些常见应用场景:1.任务调度操作系统:操作系统使用队列管理进程调度,如先来先服务(FCFS)调度算法。线程池:线程池通过队列管理待执行任务,确保任务按顺序处理。2.数据缓冲I/O操作:队列用于缓冲输入输出数据,平衡生产者和消费者速度。网络通信:网络数据包通过队列缓冲,确保按顺序处理。3.消息传递消息队列:在分布式系统中,消
- 【.NET 6】RabbitMQ延迟消息指南
人生短几个秋
.netcorerabbitmq.net
背景最近遇到一个比较特殊需求,需要修改一个的RabbitMQ消费者,以实现在消费某种特定的类型消息时,延迟1小时再处理,几个需要注意的点:延迟是以小时为单位不是所有消息都延迟消费,只延迟特定类型的消息只在第一次消费时延迟1小时,容错机制产生的重新消费(也即消息消费失败,多次进入延迟队列重试),则不再延迟1小时消费者消费过程中可能会重启考虑到这几点,我们需要一个标识以及持久化,不能简单使用Threa
- 音视频缓存数学模型
锋风Fengfeng
安卓Android应用开发相关音视频缓存
2024年8月的笔记音视频缓存数学模型-Wesley’sBlog播放器作为消费者,缓存作为生产者。进入缓冲一次设消费者速率为v1,生产者为v2,视频长度为l,x为生产者至少距离消费者多远才能保证在播完视频前两者重合。实际上就是一个追及问题。v1t=v2t+x,即l=v2*l/v1+x,因为播放器速度是1,继续简化得x=l(1-v2)如果v2大于1,即满足消费者需求时,可以流畅播放。设l是一部45分
- 如何用ruby来写hadoop的mapreduce并生成jar包
wudixiaotie
mapreduce
ruby来写hadoop的mapreduce,我用的方法是rubydoop。怎么配置环境呢:
1.安装rvm:
不说了 网上有
2.安装ruby:
由于我以前是做ruby的,所以习惯性的先安装了ruby,起码调试起来比jruby快多了。
3.安装jruby:
rvm install jruby然后等待安
- java编程思想 -- 访问控制权限
百合不是茶
java访问控制权限单例模式
访问权限是java中一个比较中要的知识点,它规定者什么方法可以访问,什么不可以访问
一:包访问权限;
自定义包:
package com.wj.control;
//包
public class Demo {
//定义一个无参的方法
public void DemoPackage(){
System.out.println("调用
- [生物与医学]请审慎食用小龙虾
comsci
生物
现在的餐馆里面出售的小龙虾,有一些是在野外捕捉的,这些小龙虾身体里面可能带有某些病毒和细菌,人食用以后可能会导致一些疾病,严重的甚至会死亡.....
所以,参加聚餐的时候,最好不要点小龙虾...就吃养殖的猪肉,牛肉,羊肉和鱼,等动物蛋白质
- org.apache.jasper.JasperException: Unable to compile class for JSP:
商人shang
maven2.2jdk1.8
环境: jdk1.8 maven tomcat7-maven-plugin 2.0
原因: tomcat7-maven-plugin 2.0 不知吃 jdk 1.8,换成 tomcat7-maven-plugin 2.2就行,即
<plugin>
- 你的垃圾你处理掉了吗?GC
oloz
GC
前序:本人菜鸟,此文研究学习来自网络,各位牛牛多指教
1.垃圾收集算法的核心思想
Java语言建立了垃圾收集机制,用以跟踪正在使用的对象和发现并回收不再使用(引用)的对象。该机制可以有效防范动态内存分配中可能发生的两个危险:因内存垃圾过多而引发的内存耗尽,以及不恰当的内存释放所造成的内存非法引用。
垃圾收集算法的核心思想是:对虚拟机可用内存空间,即堆空间中的对象进行识别
- shiro 和 SESSSION
杨白白
shiro
shiro 在web项目里默认使用的是web容器提供的session,也就是说shiro使用的session是web容器产生的,并不是自己产生的,在用于非web环境时可用其他来源代替。在web工程启动的时候它就和容器绑定在了一起,这是通过web.xml里面的shiroFilter实现的。通过session.getSession()方法会在浏览器cokkice产生JESSIONID,当关闭浏览器,此
- 移动互联网终端 淘宝客如何实现盈利
小桔子
移動客戶端淘客淘寶App
2012年淘宝联盟平台为站长和淘宝客带来的分成收入突破30亿元,同比增长100%。而来自移动端的分成达1亿元,其中美丽说、蘑菇街、果库、口袋购物等App运营商分成近5000万元。 可以看出,虽然目前阶段PC端对于淘客而言仍旧是盈利的大头,但移动端已经呈现出爆发之势。而且这个势头将随着智能终端(手机,平板)的加速普及而更加迅猛
- wordpress小工具制作
aichenglong
wordpress小工具
wordpress 使用侧边栏的小工具,很方便调整页面结构
小工具的制作过程
1 在自己的主题文件中新建一个文件夹(如widget),在文件夹中创建一个php(AWP_posts-category.php)
小工具是一个类,想侧边栏一样,还得使用代码注册,他才可以再后台使用,基本的代码一层不变
<?php
class AWP_Post_Category extends WP_Wi
- JS微信分享
AILIKES
js
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api) {
// 微信分享的数据
var wxData = {
&nb
- 封装探讨
百合不是茶
JAVA面向对象 封装
//封装 属性 方法 将某些东西包装在一起,通过创建对象或使用静态的方法来调用,称为封装;封装其实就是有选择性地公开或隐藏某些信息,它解决了数据的安全性问题,增加代码的可读性和可维护性
在 Aname类中申明三个属性,将其封装在一个类中:通过对象来调用
例如 1:
//属性 将其设为私有
姓名 name 可以公开
- jquery radio/checkbox change事件不能触发的问题
bijian1013
JavaScriptjquery
我想让radio来控制当前我选择的是机动车还是特种车,如下所示:
<html>
<head>
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.7.1/jquery.min.js" type="text/javascript"><
- AngularJS中安全性措施
bijian1013
JavaScriptAngularJS安全性XSRFJSON漏洞
在使用web应用中,安全性是应该首要考虑的一个问题。AngularJS提供了一些辅助机制,用来防护来自两个常见攻击方向的网络攻击。
一.JSON漏洞
当使用一个GET请求获取JSON数组信息的时候(尤其是当这一信息非常敏感,
- [Maven学习笔记九]Maven发布web项目
bit1129
maven
基于Maven的web项目的标准项目结构
user-project
user-core
user-service
user-web
src
- 【Hive七】Hive用户自定义聚合函数(UDAF)
bit1129
hive
用户自定义聚合函数,用户提供的多个入参通过聚合计算(求和、求最大值、求最小值)得到一个聚合计算结果的函数。
问题:UDF也可以提供输入多个参数然后输出一个结果的运算,比如加法运算add(3,5),add这个UDF需要实现UDF的evaluate方法,那么UDF和UDAF的实质分别究竟是什么?
Double evaluate(Double a, Double b)
- 通过 nginx-lua 给 Nginx 增加 OAuth 支持
ronin47
前言:我们使用Nginx的Lua中间件建立了OAuth2认证和授权层。如果你也有此打算,阅读下面的文档,实现自动化并获得收益。SeatGeek 在过去几年中取得了发展,我们已经积累了不少针对各种任务的不同管理接口。我们通常为新的展示需求创建新模块,比如我们自己的博客、图表等。我们还定期开发内部工具来处理诸如部署、可视化操作及事件处理等事务。在处理这些事务中,我们使用了几个不同的接口来认证:
&n
- 利用tomcat-redis-session-manager做session同步时自定义类对象属性保存不上的解决方法
bsr1983
session
在利用tomcat-redis-session-manager做session同步时,遇到了在session保存一个自定义对象时,修改该对象中的某个属性,session未进行序列化,属性没有被存储到redis中。 在 tomcat-redis-session-manager的github上有如下说明: Session Change Tracking
As noted in the &qu
- 《代码大全》表驱动法-Table Driven Approach-1
bylijinnan
java算法
关于Table Driven Approach的一篇非常好的文章:
http://www.codeproject.com/Articles/42732/Table-driven-Approach
package com.ljn.base;
import java.util.Random;
public class TableDriven {
public
- Sybase封锁原理
chicony
Sybase
昨天在操作Sybase IQ12.7时意外操作造成了数据库表锁定,不能删除被锁定表数据也不能往其中写入数据。由于着急往该表抽入数据,因此立马着手解决该表的解锁问题。 无奈此前没有接触过Sybase IQ12.7这套数据库产品,加之当时已属于下班时间无法求助于支持人员支持,因此只有借助搜索引擎强大的
- java异常处理机制
CrazyMizzz
java
java异常关键字有以下几个,分别为 try catch final throw throws
他们的定义分别为
try: Opening exception-handling statement.
catch: Captures the exception.
finally: Runs its code before terminating
- hive 数据插入DML语法汇总
daizj
hiveDML数据插入
Hive的数据插入DML语法汇总1、Loading files into tables语法:1) LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]解释:1)、上面命令执行环境为hive客户端环境下: hive>l
- 工厂设计模式
dcj3sjt126com
设计模式
使用设计模式是促进最佳实践和良好设计的好办法。设计模式可以提供针对常见的编程问题的灵活的解决方案。 工厂模式
工厂模式(Factory)允许你在代码执行时实例化对象。它之所以被称为工厂模式是因为它负责“生产”对象。工厂方法的参数是你要生成的对象对应的类名称。
Example #1 调用工厂方法(带参数)
<?phpclass Example{
- mysql字符串查找函数
dcj3sjt126com
mysql
FIND_IN_SET(str,strlist)
假如字符串str 在由N 子链组成的字符串列表strlist 中,则返回值的范围在1到 N 之间。一个字符串列表就是一个由一些被‘,’符号分开的自链组成的字符串。如果第一个参数是一个常数字符串,而第二个是type SET列,则 FIND_IN_SET() 函数被优化,使用比特计算。如果str不在strlist 或st
- jvm内存管理
easterfly
jvm
一、JVM堆内存的划分
分为年轻代和年老代。年轻代又分为三部分:一个eden,两个survivor。
工作过程是这样的:e区空间满了后,执行minor gc,存活下来的对象放入s0, 对s0仍会进行minor gc,存活下来的的对象放入s1中,对s1同样执行minor gc,依旧存活的对象就放入年老代中;
年老代满了之后会执行major gc,这个是stop the word模式,执行
- CentOS-6.3安装配置JDK-8
gengzg
centos
JAVA_HOME=/usr/java/jdk1.8.0_45
JRE_HOME=/usr/java/jdk1.8.0_45/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME
- 【转】关于web路径的获取方法
huangyc1210
Web路径
假定你的web application 名称为news,你在浏览器中输入请求路径: http://localhost:8080/news/main/list.jsp 则执行下面向行代码后打印出如下结果: 1、 System.out.println(request.getContextPath()); //可返回站点的根路径。也就是项
- php里获取第一个中文首字母并排序
远去的渡口
数据结构PHP
很久没来更新博客了,还是觉得工作需要多总结的好。今天来更新一个自己认为比较有成就的问题吧。 最近在做储值结算,需求里结算首页需要按门店的首字母A-Z排序。我的数据结构原本是这样的:
Array
(
[0] => Array
(
[sid] => 2885842
[recetcstoredpay] =&g
- java内部类
hm4123660
java内部类匿名内部类成员内部类方法内部类
在Java中,可以将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。内部类仍然是一个独立的类,在编译之后内部类会被编译成独立的.class文件,但是前面冠以外部类的类名和$符号。内部类可以间接解决多继承问题,可以使用内部类继承一个类,外部类继承一个类,实现多继承。
&nb
- Caused by: java.lang.IncompatibleClassChangeError: class org.hibernate.cfg.Exten
zhb8015
maven pom.xml关于hibernate的配置和异常信息如下,查了好多资料,问题还是没有解决。只知道是包冲突,就是不知道是哪个包....遇到这个问题的分享下是怎么解决的。。
maven pom:
<dependency>
<groupId>org.hibernate</groupId>
<ar
- Spark 性能相关参数配置详解-任务调度篇
Stark_Summer
sparkcachecpu任务调度yarn
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 本文试图通过阐述这其中部分参数的工作原理和配置思路, 和大家一起探讨一下如何根据实际场合对Spark进行配置优化。
由于篇幅较长,所以在这里分篇组织,如果要看最新完整的网页版内容,可以戳这里:http://spark-config.readthedocs.org/,主要是便
- css3滤镜
wangkeheng
htmlcss
经常看到一些网站的底部有一些灰色的图标,鼠标移入的时候会变亮,开始以为是js操作src或者bg呢,搜索了一下,发现了一个更好的方法:通过css3的滤镜方法。
html代码:
<a href='' class='icon'><img src='utv.jpg' /></a>
css代码:
.icon{-webkit-filter: graysc