机器学习算法——Task04条件随机场(CRF)
1. 前言
最近看了一些有关于CRF的论文,基本概念懂,但是到求解的部分有些疑惑。CRF问题容易构成NP-hard问题,求解过程还需要再学习。下面稍微介绍一些CRF的学习吧,这里前面CRF内容主要参考了下面博文,讲的非常好:
http://blog.sina.com.cn/s/blog_6d15445f0100n1vm.html
2. 介绍
条件随机场(Conditional random fields),是一种判别式图模型,因为其强大的表达能力和出色的性能,得到了广泛的应用。从最通用角度来看,CRF本质上是给定了观察值集合(observations)的马尔可夫随机场。在这里,我们直接从最通用的角度来认识和理解CRF,最后可以看到,线性CRF和所谓的高阶CRF,都是某种特定结构的CRF。
2.1. 随机场
简单地讲,随机场可以看成是一组随机变量的集合(这组随机变量对应同一个样本空间)。当然,这些随机变量之间可能有依赖关系,一般来说,也只有当这些变量之间有依赖关系的时候,我们将其单独拿出来看成一个随机场才有实际意义。
2.2. Markov随机场(MRF)
这是加了Markov性质限制的随机场。首先,一个Markov随机场对应一个无向图。这个无向图上的每一个节点对应一个随机变量,节点之间的边表示节点对应的随机变量之间有概率依赖关系。因此,Markov随机场的结构本质上反应了我们的先验知识——哪些变量之间有依赖关系需要考虑,而哪些可以忽略。
马尔科夫链最重要的则是考虑一步转移概率,放在图模型中理解,就是知道当前节点的状态,那么下一步转移到下个节点的概率分布是如何的。例如下图4个节点一步状态转移概率:
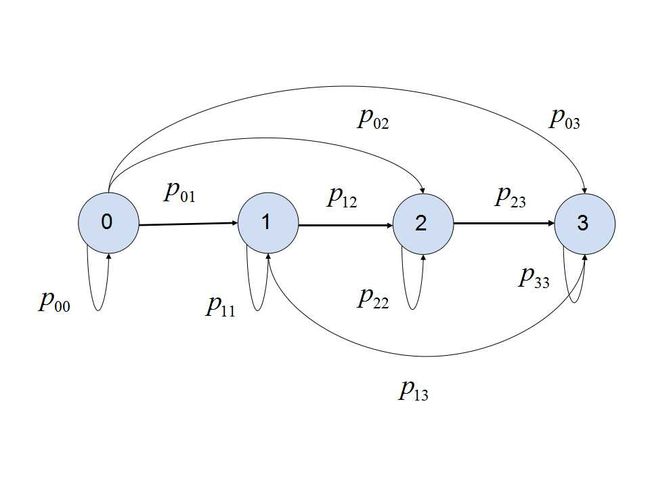
马尔科夫链一步转移概率想要描述的问题即是,例如当前状态位于节点0,那么下次转移到节点0、1、2、3的概率分别是p00p00。那么我们可以将所有状态的一步转移概率放到一个表格中,表示为转移概率表,其中每一行的每个数据为对应行状态转移到其他状态的概率。因为表示下个状态出现在各个节点的概率,状态不可能凭空消失,所以每一行的概率和一定为1。那么如果把这些数据存储到一个矩阵中,则是转移矩阵(Transition Matrix)。如下图:

关于马尔科夫链这块的理解可以参考下面博文:
http://blog.csdn.net/makenothing/article/details/41363971
其实构建转移概率,哪些节点相连通是需要深入研究的,它决定了在后面计算中,哪些节点会产生相互影响。上面的表中其实也反映了,概率大于0的表示之间节点是相互连接的,后面迭代计算其特征或者性质会对其连接的节点产生影响。当这种相互影响通过迭代到无穷趋于稳定,反应的则是稳态后状态的分布。
Markov性质是指,对Markov随机场中的任何一个随机变量,给定场中其他所有变量下该变量的分布,等同于给定场中该变量的邻居节点下该变量的分布。这让人立刻联想到马式链的定义:它们都体现了一个思想:离当前因素比较遥远(这个遥远要根据具体情况自己定义)的因素对当前因素的性质影响不大。
例如2013年发表在CVPR上一篇关于显著性目标检测的经典论文,虽然使用的是流行排序算法,但是实质跟马尔科夫随机场有很多相似的地方。这篇文章,先将图片进行超像素分割,即性质相似的像素先聚类在一起构成一块一块的具有相似性质的像素集,称为超像素(superpixel),然后将每个超像素分割作为一个节点,整幅图像所有无重叠的超像素构成一个无向图。而在构建转移矩阵上,作者认为每个超像素和其相邻接的超像素,以及相连接超像素的相连接超像素之间是相互连通的,即某个超像素是否显著会由这些超像素影响。另外,作者考虑先验知识,即图像边界的超像素之间都是连接的,因为一般一幅图像中显著区域不会出现在边界区域。节点连接结果如下图所示:
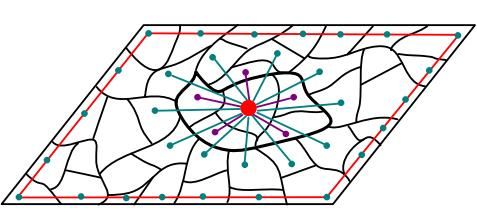
图中只画了一个超像素和邻接超像素的连通性,以及边界超像素的连通性。而各个节点之间的边权重则是由Lab颜色特征的欧氏距离决定,越相似值越大,最后每一行标准化就构成了上面类似的转移矩阵。作者设置初始状态在边界上,即由边界先验性质的边界超像素为背景,然后通过转移概率迭代平滑,当达到收敛取反则高亮处为显著目标区域。当然,作者还经过了二次游走排序,具体内容请读者自行阅读研究。
论文题目是:Saliency Detection via Graph-Based Manifold Ranking。
下载地址在下面:
http://202.118.75.4/lu/Paper/CVPR2013/cvpr13_saliency_final.pdf
- 1
另外需要强调下,这篇文章是大连理工大学张立和老师及其研究生研究成果,在显著性目标检测领域有很大影响,最近好像也扩充发表在了PAMI期刊上。
插讲了一些其他内容,下面继续回到主要内容。
Markov性质可以看作是Markov随机场的微观属性,那么其宏观属性就是其联合概率的形式。
假设MRF的变量集合为
S={y1,...yn},
P(y1,...yn)= 1/Z * exp{-1/T * U(y1,..yn)}
- 1
- 2
其中Z是归一化因子,即对分子的所有y1,..yn求和得到。U(y1,..yn)一般称为energy function, 定义为在MRF上所有clique-potential之和。T称为温度,一般取1。什么是click-potential呢? 就是在MRF对应的图中,每一个clique对应一个函数,称为clique-potential。这个联合概率形式又叫做Gibbs distribution。Hammersley and Clifford定理表达了这两种属性的等价性。
如果click-potential的定义和clique在图中所处的位置无关,则称该MRF是homogeneous;如果click-potential的定义和clique在图中的朝向(orientation)无关,则称该MRF是isotropic的。一般来说,为了简化计算,都是假定MRF即是homogeneous也是iostropic的。
2.3. 从Markov随机场到CRF
现在,如果给定的MRF中每个随机变量下面还有观察值,我们要确定的是给定观察集合下,这个MRF的分布,也就是条件分布,那么这个MRF就称为CRF(Conditional Random Field)。它的条件分布形式完全类似于MRF的分布形式,只不过多了一个观察集合x,即P(y1,..yn|x) = 1/Z(x) * exp{ -1/T * U(y1,…yn,x)。U(y1,..yn,X)仍旧是click-potential之和。
2.4. 训练
通过一组样本,我们希望能够得到CRF对应的分布形式,并且用这种分布形式对测试样本进行分类。也就是测试样本中每个随机变量的取值。
在实际应用中,clique-potential主要由用户自己定义的特征函数组成,即用户自己定义一组函数,这些函数被认为是可以用来帮助描述随机变量分布的。而这些特征函数的强弱以及正向、负向是通过训练得到的一组权重来表达的,这样,实际应用中我们需要给出特征函数以及权重的共享关系(不同的特征函数可能共享同一个权重),而clicque-potential本质上成了对应特征函数的线性组合。这些权重就成了CRF的参数。因此,本质上,图的结构是用户通过给出特征函数的定义确定的(例如,只有一维特征函数,对应的图上是没有边的)还有,CRF的分布成了对数线性形式。
看到这个分布形式,我们自然会想到用最大似然准则来进行训练。对其取log之后,会发现,表达式是convex的,也就是具有全局最优解——这是很让人振奋的事情。而且,其梯度具有解析解,这样可以用LBFGS来求解极值。
此外,也可以使用最大熵准则进行训练,这样可以用比较成熟的GIS和IIS算法进行训练。由于对数线性的分布形式下,最大熵准则和最大似然准则本质上是一样的,所以两者区别不是很大。
此外,由于前面两种训练方法在每一轮迭代时,都需要inference,这样会极大地降低训练速度。因此普遍采用另一种近似的目标函数,称为伪似然。它用每个随机变量的条件分布(就是给定其他所有随件变量的分布)之积来替代原来的似然函数,根据markov性质,这个条件分布只和其邻居有关(Markov Blanket),这样在迭代过程中不需要进行全局的inference,速度会得到极大的提升。我自己的经验表明,当特征函数很多取实数值时,伪似然的效果跟最大似然的差不多,甚至略好于后者。但对于大量二元特征(binary-valued),伪似然的效果就很差了。
2.5.推断
如前所述,训练的过程中我们需要概率推断,分类的时候我们需要找出概率最大的一组解,这都涉及到推断。这个问题本质上属于图模型上的概率推断问题。对于最简单的线性框架的结构,我们可以使用Viterbi算法。如果图结果是树形的,可以采用信念传播(belief propogation),用sum-product得到概率,用max-product得到最优的configuration.但是对于任意图,这些方法就无效了。一种近似的算法,称为loopy-belief propogation,就是在非树形结构上采用信念传播来进行推断,通过循环传播来得到近似解。这么做据说在某些场合下效果不错。但是,在训练时如果采用近似推断的话,可能会导致长时间无法收敛。
求解这块一直没有深入研究过,这些内容都是摘抄自其他论文,相关具体求解请查阅相关论文。
基于任意图上的概率推断算法称为junction tree。这个算法能够保证对任意图进行精确推理。它首先把原来的图进行三角化,在三角化的图上把clique按照某种方式枚举出来作为节点(实际上就是合并特征函数),clicque之间如果有交集,对应的节点之间就有边,这样就得到一个新的图,通过对这个图求最大生成树,就得到了Junction tree. 最后在junction tree上进行信念传播可以保证得到精确解。
本质上这3中算法都属于动态规划的思想。Viterbi的想法最直观,信念传播首先将特征函数都转换为factor,并将其与随机变量组合在一起形成factor-graph, 这样在factor-graph上用动态规划的思想进行推断(即做了一些预处理)。junction tree的做法是通过合并原有的特征函数, 形成一种新的图,在这个图上可以保证动态规划的无后效性,于是可以进行精确推理。(做了更为复杂的预处理)
值得注意的是,junction tree虽然极大地避开了组合爆炸,但由于它要合并特征函数并寻找clique, 用户的特征函数如果定义的维数过大,它得到新的clique也会很大,这样在计算的时候还是会很低效,因为在推断的过程中它需要遍历所有clique中的配置,这和clique的大小是呈指数级的。所以,用户要避免使用维数过高的特征。
更深入研究可以阅读这篇论文:
Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials
本文转载自:无鞋童鞋;原文链接:https://blog.csdn.net/FX677588/article/details/53157878?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3