Ubuntu 16.04开发CUDA程序入门(一)
Ubuntu 16.04开发CUDA程序入门(一)
- 环境:ubuntu 16.04+NVIDIA-SMI 378.13+cmake 3.5.1+CUDA 8.0+KDevelop 4.7.3
环境配置
- NVIDIA驱动、cmake、CUDA配置方法见:ubuntu 16.04 配置运行 Kintinuous
- KDevelop配置:命令行输入
sudo apt-get install kdevelop
参考文献
- 刘金硕等.基于CUDA的并行程序设计.科学出版社.2014
- linux下使cmake编译cuda: http://blog.csdn.net/u012839187/article/details/45887737 .
- CUDA Example: /home/luhaiyan/NVIDIA_CUDA-8.0_Samples/0_Simple/vectorAdd/vectorAdd.cu
数组相加-程序代码
- 打开KDevelop,新建工程,“New From Template…”-“Standard”-“Terminal”,“Application Name:”处填写“cuda_test”,“Location:”为默认的“/home/luhaiyan/projects”。
- 在cuda_test工程下新建文件“test_cuda_fun.cu”,“test_cuda_fun.cu”文件内容为[2][3]:
#include
#include
#include
//设备端代码
__global__ void vectorAdd(const float *A, const float *B, float *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
{
C[i] = A[i] + B[i];
}
}
//主机端代码
extern "C" int func() // 注意这里定义形式
{
// Error code to check return values for CUDA calls
cudaError_t err = cudaSuccess;
// Print the vector length to be used, and compute its size
int numElements = 3;
size_t size = numElements * sizeof(float);
printf("[Vector addition of %d elements]\n", numElements);
// Allocate the host input vector A
float *h_A = (float *)malloc(size);
// Allocate the host input vector B
float *h_B = (float *)malloc(size);
// Allocate the host output vector C
float *h_C = (float *)malloc(size);
// Verify that allocations succeeded
if (h_A == NULL || h_B == NULL || h_C == NULL)
{
fprintf(stderr, "Failed to allocate host vectors!\n");
exit(EXIT_FAILURE);
}
printf("Index h_A h_B\n");
// Initialize the host input vectors
for (int i = 0; i < numElements; ++i)
{
h_A[i] = rand()/(float)RAND_MAX;
h_B[i] = rand()/(float)RAND_MAX;
printf("Index %d: %f %f\n",i,h_A[i],h_B[i]);
}
printf("\n");
// Allocate the device input vector A
float *d_A = NULL;
err = cudaMalloc((void **)&d_A, size);//分配一维的线性存储空间
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device vector A (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Allocate the device input vector B
float *d_B = NULL;
err = cudaMalloc((void **)&d_B, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device vector B (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Allocate the device output vector C
float *d_C = NULL;
err = cudaMalloc((void **)&d_C, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device vector C (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Copy the host input vectors A and B in host memory to the device input vectors in
// device memory
printf("Copy input data from the host memory to the CUDA device\n");
err = cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);//将一维线性存储器的数据从主机端传输到设备端
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy vector A from host to device (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy vector B from host to device (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Launch the Vector Add CUDA Kernel
int threadsPerBlock = 256;
int blocksPerGrid =(numElements + threadsPerBlock - 1) / threadsPerBlock;
printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
vectorAdd<<>>(d_A, d_B, d_C, numElements);
err = cudaGetLastError();
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to launch vectorAdd kernel (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Copy the device result vector in device memory to the host result vector
// in host memory.
printf("Copy output data from the CUDA device to the host memory\n");
err = cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy vector C from device to host (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Verify that the result vector is correct
for (int i = 0; i < numElements; ++i)
{
if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5)
{
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
}
printf("Test PASSED\n\n");
printf("vectorAdd_Result:\n");
for(int i=0;iprintf("Index %d: %f\n",i,h_C[i]);
printf("\n");
// Free device global memory
err = cudaFree(d_A);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device vector A (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaFree(d_B);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device vector B (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaFree(d_C);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device vector C (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Free host memory
free(h_A);
free(h_B);
free(h_C);
printf("Done\n");
return 0;
} - “main.cpp”文件内容为:
#include
using namespace std;
extern "C" int func(); //注意这里的声明
int main()
{
func();
return 0;
} - “CMakeLists.txt”文件内容为:
cmake_minimum_required(VERSION 2.6)
project(cuda_test)
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
CUDA_ADD_EXECUTABLE(test_cuda main.cpp test_cuda_fun.cu) 右击“cuda_test”工程,点击“build”
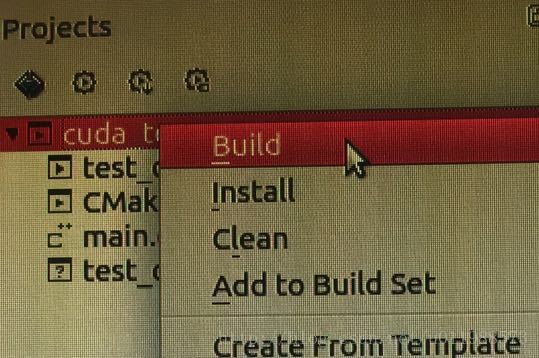
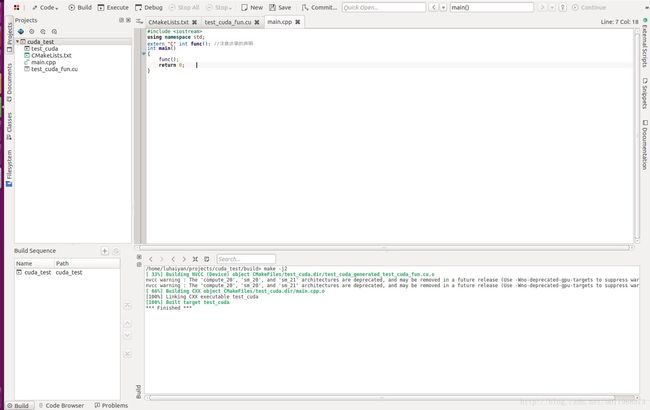
build后的整体工程结果
命令行输入
cd '/home/luhaiyan/projects/cuda_test/build'
./test_cuda- 运行结果:
