mysql学习笔记2--数据库知识点总结
1、数据库、关系型数据库、关键码、超键、候选键、主键、外键
数据库:按照数据结构来存储、管理、组织数据的仓库
关系型数据库:建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
关系型数据库的特点:
1】、数据以表格的形式出现
2】、每行为各种记录的名称
3】、每列为记录名称所对应的数据域
4】、许多的行和列组成一张单表
5】、若干的单表构成数据库
关键码:数据元素中能起标识作用的数据项 (如书目信息中的登录号和书名)
主关键码:能起唯一标识作用的关键码(如登录号),反之则为次关键码(如书名、作者名)
数据库中的关键码(key)由一个或多个属性组成:
1)、超键:在关系中能唯一标识元素属性的集称为关系模式的超键
2)、候选键:不含有多余属性的超键,是最小超键
3)、主键:数据库表中对存储数据对象予以唯一和完整标识的数据列或属性的组合
4)、外键:在一个表中存在的另一个表的主键
一个属性可以作为一个超键,多个属性组合在一起也可以也可以作为一个超键,超键包含候选键和主键;
一个数据列只能有一个主键,且主键的取值不能为空null;
例子:
超键:
学生表中含有学号或者身份证号的任意组合都为此表的超键。如:(学号)、(学号,姓名) (学号,性别)等
我们假设学生的姓名唯一,没有重名的现象。
学号唯一,所以是一个超键
姓名唯一,所以是一个超键
(姓名,性别)唯一,所以是一个超键
(姓名,年龄)唯一,所以是一个超键
(姓名,性别,年龄)唯一,所以是一个超键
候选键:
学号唯一,而且没有多余属性,所以是一个候选键
姓名唯一,而且没有多余属性,所以是一个候选键
(姓名,性别)唯一,但是单独姓名一个属性就能确定这个人是谁,所以性别这个属性就是多余属性,所以(姓名,性别)不是候选键
(姓名,年龄),(姓名,性别,年龄)同上,也不是候选键
主键:
主键就是候选键里面的一个,是人为规定的,例如学生表中,我们通常会让“学号”做主键,学号能唯一标识这一个元组。
外键:
外键就很简单了,假如我们还有一个教师表,每个教师都有自己的编号,假设老师编号在老师这个层次中是主键,在学生表中它就是外键。
2、什么是事务?数据库事务的四个特性及其含义?什么是锁?
【1】、事务:就是对数据库所做的一个或多个修改,比如使用update语句对表里某个人的姓名进行修改,就是在执行一个事务。
如果任何一个语句操作失败,那么整个操作都会失败,以后操作就会回滚到操作前状态,或者是上个节点。
为了确保要么执行,要么不执行,就可以使用事务。
【2】、事务必须服从ACID原则,即:原子性(atomicity)、一致性(consistency)、隔离性(isolation)、持久性(durability)
原子性:即不可分割性,事务要么被全部执行,要么就全部不被执行
一致性:事务的执行前后数据库必须处于一致性状态,比如事务执行前是处于第一范式,执行事务后也必须是第一范式
隔离性:在事务正确提交之前,它可能的结果不应显示给任何其他事务
持久性:事务正确提交后,其结果将永久保存在数据库中,即使在事务提交后有了其他故障,事务的处理结果也会得到保存
【3】、锁:在所有的数据库管理系统中,锁是实现事务的关键,锁可以保证事务的完整性和并发性。与现实生活中的锁一样,它可以使某些数据的拥有者,在某段时间内不能使用某些数据或数据解构,当然锁还分级别。
【4】、事务的隔离级别
1)、未提交读(脏读):所有事务可以看到其他未提交事务的执行结果
2)、提交读:事务在未提交之前对其他事务不可见
3)、可重复读(Mysql默认):同一事务的多个实例在并发读取数据时,可以看到同样的数据行
4)、可串行化:给每个读的数据行上加共享锁,强制所有事务都是串行执行
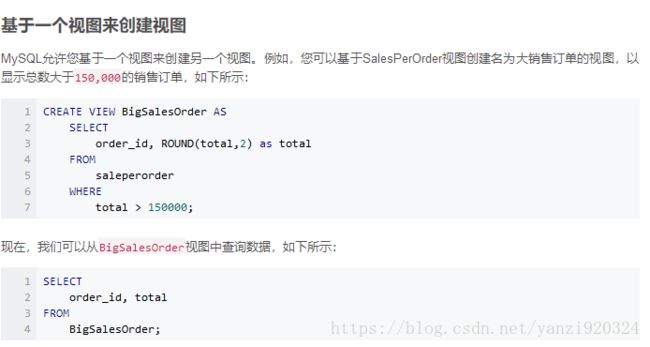
3、什么是视图?
视图是一种虚拟的表,具有和物理表相同的功能。但不占据物理空间,只是从表里引用数据。可以对视图进行增,改,查操作。
视图通常是有一个表或者多个表的行或列的子集,对视图的修改不影响基本表。它使得我们获取数据更容易,相对多表查询。
如下两种场景一般会用到视图:
1)、不希望访问者获取整个表的信息,只暴露部分字段给访问者,所以就建一个虚表,就是视图
2)、查询的数据来源于不同的表,而查询者希望以统一的方式查询,这样也可以建立一个视图,把多个表查询结果联合起来,查询者只需要直接从视图中获取数据,不必考虑数据来源于不同表多带来的差异。
注:这个视图是在数据库中创建的,而不是用代码创建的
创建视图:
CREATE
[ALGORITHM = {MERGE | TEMPTABLE | UNDEFINED}]
VIEW
[database_name].[view_name]
AS
[SELECT statement]


4、触发器的作用?
触发器是一种特殊的存储过程,主要是通过事件来触发而被执行的,它可以监视某些数据的操作,并触发相关的操作,用来保护数据的完整性。
触发器语法格式:
creat trigger 触发器名称
after/before(触发器工作的时机) update/delete/insert(触发器监听事件) on 表名(触发器监听的目标表)
for each row(行级监视,mysql固定写法,oracle不同)
begin
sql语句集........(触发器执行动作,分号结尾)
end;
删除触发器:drop trigger if exist 触发器名称
查询数据库触发器:show triggers;
行变量:当目标表发生改变时候,变化的行可用行变量表示
new:代表目标表目标行发生改变之后的行
old:代表目标表目标行发生改变之前的行
例子:
触发器监听:insert
create trigger tr1
after insert on orders
for each row
begin
update goods set godnum = godnum-new.godnum where id = new.id;
end;
5、维护数据库的完整性和一致性,你喜欢用触发器还是自写业务逻辑?为什么?
尽可能使用约束,如:check、主键、外键、非空字段等来约束,这样做效率最高,也最方便。其次是使用触发器,这种方法可以保证,无论什么业务系统访问数据库都可以保证数据的完整性和一致性。最后考虑自写业务逻辑,但这样做麻烦,编程复杂,效率低下。
6、索引的作用,她的优点和缺点?用什么数据结构创建索引?为什么是用这种数据结构?
简答:索引就是一种特殊的查询表,数据库的搜索引擎可以利用它加速对数据的检索。它很类似于现实生活中书的目录,不需要查询整本书的内容就可以找到想要的数据。索引可以是唯一的,创建索引允许指定单个列或者多个列,缺点一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间,因为索引也要随之变动。
索引的实现一般使用B+树。
B+树的特点:只有叶节点存放数据,其余节点用来索引,叶子节点中有一个指针指向一下个叶子节点,提高了区间访问的性能。所以B+树更适合用来存储外部数据,也就是所谓的磁盘数据。
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
为什么用B+树:
1】、文件很大,不可能全部存储到内存中,故要存储到磁盘上。
2】、索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数
3】、B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此他的内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘快中,那么盘快所能容纳的关键字数量也越多,一次性读取内存需要查找的关键字也就更多,相对IO读写次数就降低了。
4】、B+树的查询效率更加稳定,由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引,所以任何关键字的查找必须走一条从根结点到叶子结点的路,所以关键字查询的路径长度相同,导致每一个查询的效率相当。
5】、B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是比如说B树因为他的分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合数据库索引。
https://www.cnblogs.com/tiancai/p/9024351.html
为表设置索引要付出代价:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间,因为索引也要随之变动。
创建索引可以大大提高系统的性能(优点):
第一:通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二:可以大大加快数据的检索速度,这也是创建索引的最主要原因。
第三:可以加速表与表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四:在使用分组和排序字句进行数据检索时,同样可以显著减少查询中分组和排序的时间
第五:通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统性能。
创建索引的缺点:
第一:创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
第二:索引需要占据物理空间,除了数据表占数据空间之外,每一个索引还要占一定的索引空间,如果要建立聚簇索引,那么需要的空间会更大。
第三:当对表中的数据进行增、删、改的时候,索引也要动态的维护,这样就降低了对数据的维护速度。
索引是建立在数据库表中某些列的上面,在创建索引时,一般应该在这些列上创建索引:
1)、在经常需要搜索的列上,可以加快搜索的速度
2)、在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构
3)、在经常用在连接的列上,这些列主要是一些外键,可以加快连接速度
4)、在经常需要根据范围进行搜索的列上,因为索引已经进行排序,其指定的范围是连续的。
5)、在经常需要排序的列上,因为索引已经排序,可以加快查询时间
6)、在经常使用在where字句中的列上面创建索引,加快条件的判断速度
同样,对于有些列不应该创建索引
1)、在查询中很少使用或者参考的列。因为既然这些列很少使用,因此有无索引,并不能提高查询速度,反而由于增加了索引而降低了系统的维护速度和增大了空间需求
2)、只有很少数据值的列。如性别,在查询结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大,增加索引,显然并不能加快检索速度。
3)、定义为text、image、bit数据类型的列。因为这些列的数据量要么很大要么取值很少
4)、当修改性能远远大于检索性能。因为修改和检索性能是互相矛盾的,当增加索引,会提高检索性能,但同时会降低修改性能。
7、dop、delete、truncate的区别
drop:直接删掉表
truncate:删除表中数据,再插入时自增长id又从1开始
delete:删除表中数据,可以加where字句
1)、delete语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行回滚操作。truncate则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的,并且在删除的过程中不会激活与表有关的删除触发器,执行速度快。
2)、表和索引所占空间,truncate:表和索引所占据的空间会恢复到初始大小;delete:不会减少表和索引所占用的空间;drop:将表所占用的空间全部释放
3)、速度:drop>truncate>delete
4)、应用范围:truncate只能对table,而delete可以是table和view
5)、truncate和delete只删除数据,而drop可以删除整个表,包括数据和结构
6)、truncate和不带where的delete:只删除数据,而不删除表的结构;drop将删除表的结构、被依赖的约束、触发器、索引,依赖于该表的存储过程或者函数将会保留,但其状态会变为:invalid
7)、delete语句为DML(data maintain language)语句,不会自动提交,操作会被放到rollback segment中,事务提交后才生效,有相应的触发器执行的时候才会被触发;drop/truncate语句为DDL(data define language)语句,执行后会自动提交。
8)、在没有备份的情况下,谨慎使用drop与truncate。要删除部分数据行采用delete且注意结合where来约束影响范围。回滚段要足够大,要删除表用drop;若想保留表而将表中数据删除,如果与事务无关,用truncate即可实现。如果与事务有关或想触发trigger,还是用delete。
9)、truncate table 表名 :速度快,而且效率高。因为truncate table 在功能上与不带where子句的delete功能相同:二者均删除表中的全部行,但truncate比delete速度快,且使用的系统和事务日志资源少。delete语句每次删除一行,并在事务日志中为所删除的每行记录一项。truncate 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
10)、truncate删除表中的所有行,但表的结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子,如果想保留标识计数值,请改用delete。如果要删除表定义及其数据,请使用drop table语句
11)、对于由foreing key约束引用的表,不能使用truncate table,而应使用不带where的delete,由于truncate table不记录在日志中,所以它不能激活触发器。
8、什么是连接池?
连接池是一个等待数据库连接的队列。连接池是创建和管理一个连接的缓冲池的技术。当一个线程需要用JDBC(java数据库连接)对一个GBase或其他数据库操作时,它从池中请求一个连接。当这个线程使用完了这个连接,当这个线程使用完了这个连接,将它返回到连接池中,这样就可以被其他想使用它的线程使用。
9、什么是存储过程?有哪些特性?用什么来调用?
存储过程:简单来说就是一组SQL语句集,功能强大,可以实现一些比较复杂的逻辑功能,类似于java里面的方法
ps:存储过程与触发器有点类似,都是一组SQL集,但是存储过程是主动调用的,且功能比触发器更加强大,触发器是某件事触发后自动调用
特性:
1】、有输入输出参数,可以声明变量,有if/else/case/while等控制语句,通过编写存储过程,可以实现复杂的逻辑功能
2】、具有函数的普遍特性:可以模块化、封装、代码重用
3】、速度快,只有首次执行需要经过编译和优化步骤,后续被调用可以直接执行省去以上步骤

10、什么是游标?
是对查询出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。可以对结果集当前行做修改。一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
11、NULL是什么意思?
NULL表示未知,它不表示空字符串。假设SQL Server数据库里有ANSI_NULLS,对空这个值的任何一个比较都会产生一个null值。不能把任何值与一个未知值进行比较,必须使用is null操作符
12、如何判断数据库的时区?
SQL>select dbtimezone from dual 查看数据库时区
SQL>select sessiontimezone from dual 查看回话时区
SQL>select sysdate from dual 查看当前日期和时间
SQL>select systimestamp from dual 返回本机数据库上当前系统日期和时间(包括微秒和时区)
SQL>select current_date from dual
SQL>select current_timestamp from dual
13、创建sequence
create sequence sql_test minvalue 1 maxvalue 21 start with 1 increment by 1 catch 20 cycle order;
minvalue 1 / nominvalue:最小值为1
maxvalue 21 / nomaxvalue:最大值为21
start with 1:从1开始计数
increment by 1:每次增加1
cache 20 / nocache:缓存20个sequence值 / 不缓存
如果缓存,则会有跳号的危险:如果指定cache值,oracle就可以预先在内存里面放置一些sequence,这样存取的快些。内存里面的取完后,oracle自动再取一组到内存。数据库突然不正常down掉,内存中的sequence就会丢失
cycle / nocycle:cycle,即如果到达最大值21后,再次从1开始
14、如何重构索引?
SQL>alert index indexname rebulid;
15、1000个用户同时来访数据库,可采用什么技术解决?
可用连接池
16、如何分辨某个用户是从哪台机器登录oracle的?
select machine,terminal from v$session
17、如何查看系统被锁的事务时间?
select *from v$locked_object
18、数据库表中的字段最大数为多少?
表或试图中的最大列数为1000
19、如何查询数据库的SID?
select name from v$database;也可以直接查看init.ora文件
20、SID是什么?
SID是一个数据库的唯一标识符,是建立一个数据库时系统自动赋予的一个初始ID。SID主要用于在一些DBA操作以及操作系统中交互,从操作系统的角度访问实例名ORACLE_SID,且它在注册表中也是存在的。
21、mysql的数据类型?
mysql的数据类型主要包括三类:数值、日期、字符串
常用:数值:int、float、double
字符串:char(定长)、varChar(变长)
日期:date、time、year