大型DCI网络智能运营实践

9月14-15日,GOPS全球运维大会上海站圆满举行,为期两天的运维盛宴,为各位运维人带来了相互交流和学习的绝佳平台,来自腾讯技术工程事业群(TEG)网络平台部的何维兵给大家带来了「大型DCI网络智能运营实践」的主题分享。
我们同步了嘉宾现场沙龙分享视频(内含高清PPT),请点击下方「腾讯技术课小程序」卡片即可查看:
同时附上整理好的演讲稿:
何维兵,来自腾讯TEG网络平台部,资深运维老兵,拥有10年运营商网络、6年互联网基础设施运营经验,擅长大型骨干网络、数据中心网络维护管理和运营支撑系统规划建设,目前专注于网络自动化运营、NetDevOps以及网络智能运营的实践探索。

运营苦、运营累,关键时刻不能跪!!!
记得有一年微信年会,老板现场发红包给大家,结果红包没发出去,因为网络出故障了!你们能想象到当时有多尴尬。随后老板找到我们提了需求,重要业务要在三分钟恢复!
我们来分析一下这个需求,这是截取的一些公开资料,大部分互联网公司都差不多,从A端到B端的访问路径算了一下,大概经过32个网络结点,中间路径1000条,这么多路径、这么多节点,三分钟时间内搞定这些问题还是挺有挑战的。

需求是合理的,老板的方向也是对的。于是我们启动了一个项目,黑镜1.0:网络故障智能定位,尝试解决这个需求。出发点是:围绕着故障发现、定位、恢复这三个阶段,看看每个阶段能做哪些事情或提升!
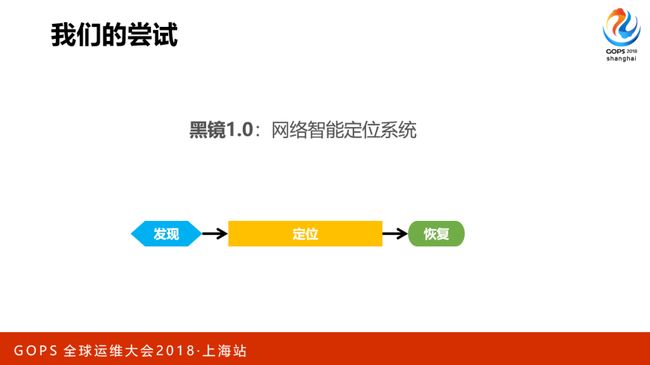
我们总结了一下思路,称之为“3M大法”。首先把自己的眼睛擦亮,通过Meshping的方案做了高精度的监控感知系统。第二,基于以往故障的经验总结哪些东西是跟故障强相关的因素,定义为Multi-KPI的体系,通过这种方式我们来定位故障。第三,把所有的冗余组件封装好,用的时候直接调用组件Moveout故障点。
第一个Meshping探测,原理并不复杂。过去我们7*24小时坐在NOC监控中心,但很多时候并没有发现问题,都是业务发现后找到我们。为什么出现这样的情况呢?因为业务非常多,它分布的太广了,它的敏捷度远远比我们高。那我们就想,干脆就从业务的角度监控,就拿机房的海量服务器去做这样的事情。
其实很简单,就是选取一部分机器作为探测对象,然后机器之间交叉探测。听起来很简单,但是要达到既能覆盖所有的路径,同时也在一定的时间之内,高效的把结果计算出来,并且达到高精度的报警,这还是很有挑战的。
一方面要解决海量ping侧任务和结果的计算,还要把中间的探索路径记录了下来,这么多的样本记录下来挑战也很大,我们当时做的时候也缴了一些“学费”,把设备搞奔溃的情况也出现过。
另外随着故障场景的积累,还需要更丰富的探测元素,比如说大小包的组合、QoS标记组合、UDP资源探测等等,我们现在还在持续的优化Meshping探测方案。
第二个就是Mulit-KPI指标系统。过去排查故障时,往往花大量的时间分析数据、找线索,就像上面提到的从那么复杂的一个路径中,串行的执行那么多的分析工作,很难在很短的时间内定位故障的来源。所以后来我们不找细节的东西了,去找什么东西能够代表它的故障,或者说哪些趋势变化跟故障强相关。
举例其中一个KPI指标:设备转发效能比,它是基于包量守恒原理(二层环境除外),把设备上所有的的入和出的数据包采集出来,做成一个比值曲线。大家可以看一下这个真实的数据,平时是很稳态的,但是故障发生后,这个曲线会有明显的突变。我们把这样的类似的趋势变化,定义为故障关联的KPI指标,这些指标不一定要多,但一定要准确和故障关联。
第三个是Moveout隔离屏蔽。我们对所有的网络冗余组件做了屏蔽操作的自动化封装。有些不具备屏蔽的条件,也会设置一些静默的通道放在这里,平时不用,需要使用的时候就开启它。所以至少核心的层的组件都具备“逃生”的能力。
整套定位平台框架由以上三个部分组成,其故障定位的原理也很简单,把所有的探测的流采集出来,记录下来探测流的路径,通过这些异常流的特性锁定一批设备,然后对这些设备计算KPI指标,通过KPI指标的叠加,就能看到谁是最可能的故障点了。

通过这套系统,可以在三分钟内检测到异常,并通过微信推送告警;然后4分钟内完成定位计算,推荐故障定位结论;下一步就是人去决策要不要做相应的动作?
初期以安全为主,只在部分场景做成全自动化。通过这套黑镜网络自动化的诊断、定位系统,我们在网络故障时,最快可以十分钟内恢复故障,大部分场景在30分钟之内搞定故障。

上述方法让运营能力得到很大的提升,网络质量监控很准确了,达到90%以上;但定位准确性不高,大概有50%(不准确性),还不能满足需求。
有没有办法进一步提升呢?
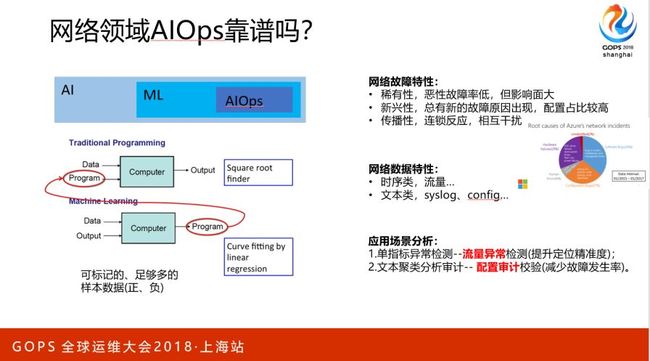
这几年大家都在谈AIOps的理念,我们想能不能把AIOps引进来做一些尝试。

想法很好,如何落地呢?
谈到AIOps、机器学习,其主要的核心是要有高质量的数据,要有丰富的输入和输出,从这些数据样本中去找到一些隐含的规律把它提取出来。
但是我们网络的数据是什么样的?
先看看网络故障数据,发现有三个特点:
第一个就是稀有性,网络上恶性故障样本非常少,一年下来大概两只手就可以数过来了;
第二个就是新兴性,我们发现每次故障和上次故障重复的比例并不多,它都是新兴的故障,特别是配置,每次配置发生的问题都是有差异性的,它的规律性其实并不强;
第三个是传播性,网络是一个mesh的连接,节点之间的存在较大的干扰。基于这几个特性,我们发现网络上的故障数据质量其实并不高,并不具备特别强的规律性。
那是不是不能做了呢?再看看网络上还有什么样的数据。
第一类是时序类的,比如我们通过SNMP采集的流量数据;还有一类是文本类的,比如config、syslog;这些数据能不能有小应用的场景呢?
我们结合一些行业的经验和做法,选取了2个场景来进行试点:
第一个就是时序曲线的检测,这个是业界应用最多的;
第二个就是文本的聚类分析,对配置文件进行审计校验。
我们的想法是,一方面能看能否对KPI指标的监控准确性有所提升;另一方面通过配置文件的管理,减少故障的发生。
我们来看一看具体是怎么做的。
第一个流量的异常检测,我们联合内部SNG的织云做了尝试,直接拿他们Metis平台的成熟算法应用。把网络的实时流量数据和历史数据导到Metis平台,平台返回检测结果,不需要我们进行任何配置,只需要对结果进行标记反馈。
用了这套方法之后,我们发现可以很好的解决单幅图的监控,帮助我们解决锯齿性、周需期性的误告问题。但也发现还存在一些问题,主要是曲线之间的关联问题。比如一个负载均衡的多个端口,像左边的图下降了,右边升高了,这是一个正常的网络切换行为,并不需要告警。这是在传统的监控中没有解决的问题,这里仍然解决不了。

那这种关联性如何解决呢?
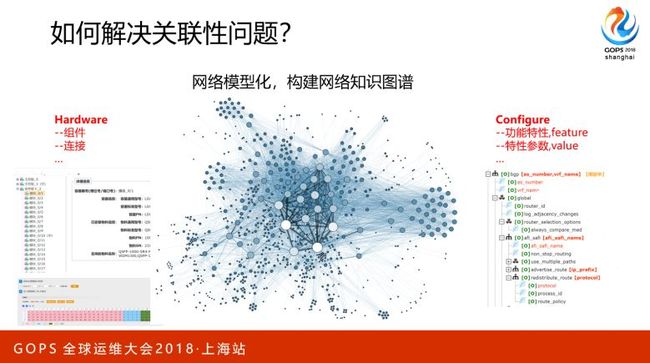
过去我们对网络的管理的模式和方法不够精确,很多的网络知识,比如对网络的连接、配置等,大部分是以PPT、WORD、EXCEL的形式存在,或者装在脑子里面。没有经过很好的抽象和封装,把这些东西以参数、函数的方式表达出来,简单说就是没有模型化、结构化的抽象,没有存在我们的数据库中,系统不太能理解网络上的一些含义,比如一条连线代表什么含义,一条配置代表什么含义,一条syslog代表什么含义。
因此我们最近2年在对网络进行抽象建模,对硬件连接、对配置特性、参数,包括运营的状态进行模型化的抽象定义,简单说就是构建比较完整的网络知识图谱。这个工作,挑战性也蛮大的,我们还在不断的摸索中,硬件部分我们已经完成,并应用在一些新建、扩容场景中,配置部分正在开展中。这是我们后续重点发力的方向。
第二个实践,我们尝试在配置管理上做一些突破。一台TOR大概有5K行的配置,一台CORE上万行的配置,这么多行里挑哪一行错了是很难的。同时每一天都有变更发生,你如何在动态的情况下管理它呢?这个挑战是很大的。
我们在想怎么做呢?也无非就是找不同嘛,找谁的差异性比较大。

举个简单的例子,比如说有这么多篮的水果,如何把不同的水果篮挑出来呢?我先把水果堆在一起,看看哪些水果出现频率是最高和最低的,然后把它进行聚类,把稀疏的项目筛掉,我们就用这种思路去管理。
具体怎么做呢?
我们参考了TF-IDF的文本分析算法,它主要是会过滤一些非关键的词项。我们把这套方法叫做聚类+降维分析法,把它应用在了配置文本的管理上。

首先把配置文件拆分成很多的模块,每一个模块把词聚集起来,比如说一百个文件中的同一个配置模块聚在一起,然后计算每个词出现的频率是多少,出现频率比较低的直接筛掉。然后会形成几个模板,这个模板会代表大多数的“广泛意见”,然后拿这个模板和现网的配置进行对比,从而实现审计校验的功能。
它可以用在两个场景,第一个场景就是可以在存量的配置里提取有哪几种配置标准,给到负责配置规范的同事去核验;第二,就是对存量的小众配置的设备,去看为什么不一样?是不是哪里配错了?这个方法在标准化程度比较高的架构中效果不错,但一些边缘接入的差异性比较大的场景则不是很好,另外对一些参数错误、或全局错误也不能发现。
通过这两个案例,我们在网络AIOps方面做了初步的探索和实践,没有用很高深的算法。在这个过程当中我们也总结了一些经验,供大家在网络领域进行AIOps尝试提供一些参考,主要有三点:
第一点,就是网络要系统建模。当前的网络的抽象程度不够,系统没有办法理解网络上的语言和行为,要把网络上的对象、事件、行为标准化的定义出来,让系统能够理解。今天上午清华的裴丹老师也提到过,这个工作是基础当中的基础。当然这个挑战性非常大,需要大量的投入;
第二点,不需要过多关注算法细节。网络从业人员在算法上不具备优势,在算法领域可以充分借鉴参考成熟的经验或开放资源,把重心放在场景、数据的挖掘和分析上。关键是利用算法的思路,看他能解决什么问题,比如我们第二个案例,实际上并没有用到机器学习,只是用了一个数学算法,降低了问题的复杂度;
第三点,要加大在数据挖掘和DevOps上的投入。未来的运营,大部分是围绕数据的提取、分析、挖掘等工作,如何对数据进行快速的提取、分析,把分析、处理逻辑准确定义好,这是我们重点投入的方向。

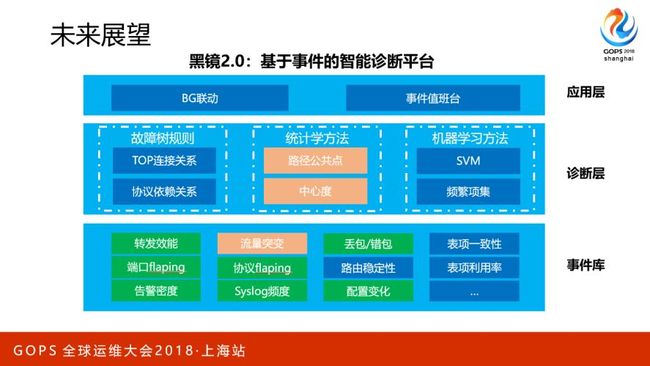
以上就是我们近期在网络AIOps上的一些探索和思考,这些工作只是一个开头,相关的项目仍然在持续的推进,我们正在开展黑镜2.0的项目,打造基于事件的智能诊断平台。会对更多的运营数据进行分析,并把检测分析逻辑模型化,实时对全网进行大量的逻辑运算,提取异常事件,形成异常事件库。会持续的进行一些方法的优化,引入更多的算法,提升准确性。
最终将基于完整的知识图谱,构建一个图数据库描述网络的软硬件关系,基于异常事件对网元进行着色处理,然后根据中心度的算法,进行故障定位计算。
这是下一步的方向和思路,这里有很多的细节东西还没有想清楚,还在落实当中。这里也是欢迎各位一起研究和探讨。