阿里深度兴趣网络:Deep Interest network(DIN)
DIN(深度兴趣网络)是阿里在KDD2018提出的一种有效的用于CTR、个性化推荐的深度学习模型。其效果已经在阿里的电商平台得到了验证。优秀的文章需要学习记录。接下来对这篇论文进行总结概括:
1. 动机
文章指出,用户兴趣有以下两个特点:
多样性:即每个用户在浏览购物网站的时候可能会对不能的商品感兴趣。比如一个年轻小伙,他可能对电子产品和运动装备都感兴趣。他的历史行为中可能购买过手机、电脑、耳机,也可能购买过护膝、球衣以及篮球鞋。
局部聚集性:由于用户兴趣具有多样性,所以只有部分用户历史行为对是否点击有帮助。比如系统给年轻小伙推荐一款新款篮球鞋,他是否点击只跟他之前买过护膝、球衣的历史行为有关,而与他是否购买过电脑、手机的历史行为无关。
CTR预测是工业应用中常见的任务。常见的深度学习的基线模型是将Embedding&MLP相结合。首先,将大规模的稀疏特征映射为低维度的embedding向量;然后用group-wise将其转换为长度固定的向量;最后将这些向量连接在一起喂入MLP学习特征间的非线性关系。但是这种模型存在一定的缺陷:不论候选ad是什么,用户特征都被压缩为固定长度的表示向量(这限制了Embedding&MLP的表达能力),这很难从有效的从历史行为数据中捕获用户的多样性兴趣。论文作者提出了DIN模型,即深度兴趣网络,它通过设计局部激活单元自适应的从历史行为中学习用户的兴趣表示。DIN通过引入一个局部激活单元,通过软搜索历史行为的相关部分来关注相关的用户兴趣,并采用加权和池来获得用户兴趣相对于候选广告的表示,与候选广告相关性越高的行为的激活权重越大,并在用户兴趣的表示中占主导地位。实际上就是增加了Attention机制。此外,文中还提出了新的正则化方法以及激活函数。
2. DIN网络模型
不同于搜索,用户进入电商网站并没有明确的意向。因此需要从丰富的历史行为提取出用户的兴趣以此来构建CTR预测模型。
2.1 特征表示
CTR预测任务中的数据大多数都是多分组的类别表,比如特征[weekday=Friday,gender=Female,visited_cate_ids={Bag,Book},ad_cate_id=Book],这些特征通过编码转化成高维稀疏二值特征。
上述四种特征按照如下的方式编码:
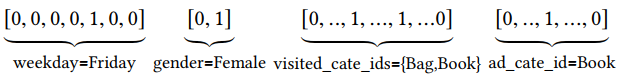
文中使用的特征表示如下表所示:
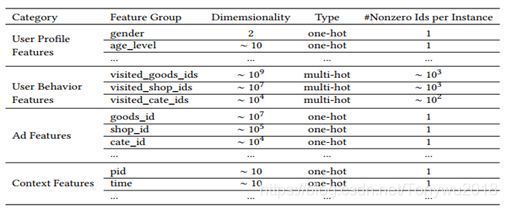
其中用户行为特征是多热编码,它包含了丰富的用户兴趣信息。文中没有使用组合(交叉)特征,而是通过DNN来学习特征间的交互。
2.1. 基线模型(Embedding&MLP)
很多关于CTR预估的深度学习模型都相似的Embedding&MLP范式,如下图所示:

Embedding层:
因为输入是高维的二值向量,embedding层将它们转化为低维的稠密向量。
池化层和连接层:
不同的用户不同的行为数,因此多热行为向量ti![]() 中的非零数在不同实例中是不同的,这导致相应的embedding向量的长度是变化的。但是全连接网络只能处理固定长度的输入,通常通过pooling层将embedding向量转化为固定长度的向量。
中的非零数在不同实例中是不同的,这导致相应的embedding向量的长度是变化的。但是全连接网络只能处理固定长度的输入,通常通过pooling层将embedding向量转化为固定长度的向量。
![]()
将用户行为特征进行sum池化后,然后与其它3个特征组的低维稠密向量表示Concat为一个更高维度的向量作为MLP的输入
MLP:
将合并好的向量输入MLP,MLP由3层组成,第一层由200个神经单元组成,激活函数为PReLU;第二层由80个神经单元组成,激活函数同样为PReLU;最后一层是由Softmax做一个二分类。
损失函数:
基线模型的目标函数是负的对数似然函数,定义如下:
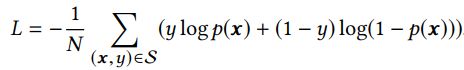
S是size为N的数据集。
2.3. DIN的结构:
Key:部分激活函数的设计,相当于给User Behavior特征加了Attention机制,即与候选ad相关性高的行为获得更大的权重。
固定向量的长度会降低用户兴趣的表达能力,一种简单的方法是扩展embedding向量的维度,但是这会大大增加计算量并且容易导致过拟合。
有没有一种更好的方式在有限的维度表示向量的多样性兴趣?考虑到用户兴趣的局部聚集特性,即与展示商品相关的行为对点击action有更大的贡献,基于此作者提出了DIN。DIN不会通过使用相同的向量来表达所有用户的不同兴趣,而是通过考虑与候选广告的历史行为的相关性来自适应地计算用户兴趣的表示向量。这个表示向量是根据不同的广告变化的。DIN模型结构如下:

DIN结构与基线模型的区别在于DIN设计了局部激活单元。激活单元会计算候选商品与用户最近N个历史行为商品的相关性权重,然后将其作为加权系数对N个行为商品的embedding向量做sum pooling。用户的兴趣由加权后的embedding来体现。权重是根据候选商品和历史行为共同决定的,同一候选商品对不同用户历史行为的影响是不同的,与候选商品相关性高的历史行为会获得更高的权重。可以看到,激活单元是一个多层网络,输入为User Behaviors embedding向量、Candidate Ad embedding 向量以及二者的叉乘。
Note:初始版本中输入是二者的差
3.训练技巧
当数据量较大时,训练开销很大,因此作者提出了两个训练技巧。
3.1. Mini-batch aware正则化/自适应正则化
过拟合是模型训练中的很容易出现的问题,但是在参数较多数据规模较大的情况下,L1或L2正则化的计算成本太高。因此作者提出了一种效率更高的正则化方式。Mini-batch aware正则化,其公式如下:

其中αmj = max(x,y)∈Bm I(xj , 0),表示在mini-batch Bm中是否至少有一个实例存在特征j;Bm表示第m个mini-batch;B表示mini-batch的总数;K是特征空间的维度,nj表示所有样本中特征j出现的次数;wj表示第j个embedding向量的权重。
对于第j个mini-batch,权重更新如下所示:
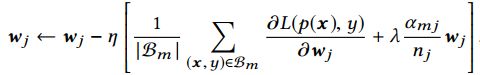
3.2. Dice激活函数
Dice激活函数是在PReLU的基础上进行改进的,首先PReLU激活函数的公式如下:
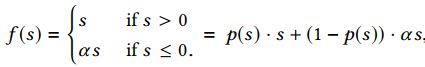
其中p(s)为控制函数,其定义为p(s)=I(s>0),I(.)为指示函数。Dice激活函数把PReLUde激活函数中的p(s)进行了修改如下:
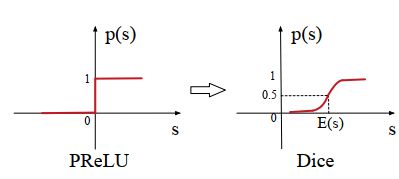
Dice激活函数的表达式如下:

其中E[s]和Var[s]是每个mini-batch输入的均值和方差。ϵ是一个非常小的常数10-8,其值设置为。Dice主要思想是根据输入数据的分布,自适应地调整校正点,使其值为输入的均值。当E[s]和Var[s]均为0时,Dice和PReLU是等价的。
4. 实验部分
4.1. 数据集
文章使用了两个公开数据集和阿里自己线上收集的数据集
Amazon数据集:特征包括goods_id、cate_id、user reviewed goods_id_list以及cate_id_list使用带有指数衰减的SGD优化,学习速率从1开始、衰减速率设置为0.1,mini-batch的size设置为32。
MovieLens数据集:这是用户对电影评分的数据集,评分为0-5分,作者将其转化成了二分类:0-3分为负样本、4和5分为正样本。特征包括moive_id、moive_cate_id、user_rated moive_id_list以及moive_cate_id_list.优化器、学习速率以及mini-batch的size和Amazon的设置一样。
Alibaba数据集:两周的线上数据作为训练集、一天的线上数据作为测试集。Embedding向量的维度为12;mini-batch的size为5000;使用带有指数衰减的Adam作为优化方法;学习速率从0.001开始、衰减速率设置为0.9。
4.2. 模型比较
文章提出的DIN分别与LR、BaseModel、Wide&Deep、PNN、DeepFM五种模型比较。使用平均AUC作为度量指标,其定义如下:

其中i是用户数、#impressioni是第i个用户的曝光数、AUCi是第i个用户的AUC。
4.3. 正则化的性能比较
当数据维度较大时,过拟合问题会成为一个巨大挑战。这主要出现在Alibaba数据集。尤其是加入细粒度特征goods_id时容易出现过拟合,作者分别使用了Dropout、Filter、DiFracto以及文中提出的mini-batch aware四种正则化方法。比较结果如下:
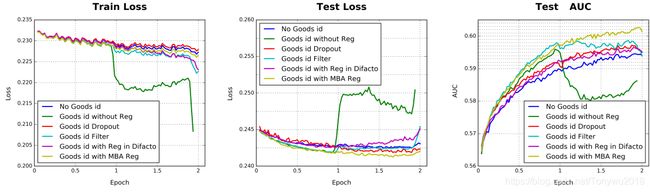

4.4. 加入Dice激活函数
在MBA基础上加上Dice激活函数,最后的结果比较如下:

使用DIN作为模型,以MBA为正则化方法、Dice为激活函数时的AUC最高。
5. 总结
DIN最大的亮点是引入了类似于Attention的机制,这捕获了用户兴趣的多样性。此外还引入了两个技巧:MBA正则化以及Dice激活函数。
参考文献:
Deep Interest Network for Click-Through Rate Prediction