制作自己的ctpn数据集
制作自己的ctpn数据集
1、利用label-image标注自己的数据集,保存为.txt文件,结果如下:
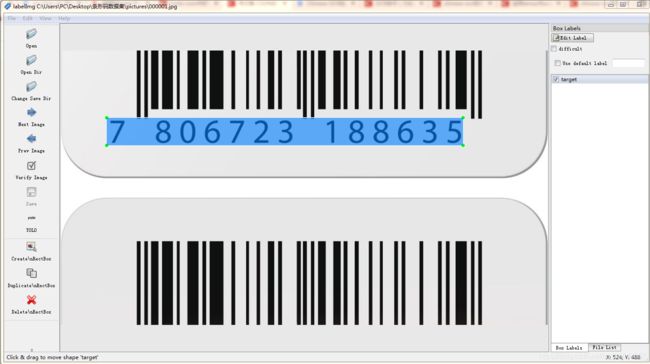


上图第一列 0:标签 后面的小数是label—image标注的坐标框位置(归一化后的结果)
2、ctpn数据集的格式:
x1,y1,x2,y2,x3,y3,x4,y4 顺序是:左上角、右上角、右下角、左下角 (坐标) (参考mlt数据集格式)
参考链接:https://blog.csdn.net/monk1992/article/details/99670559
(ctpn中的数据集格式为:左上角、右下角)
3、将自己标注的数据集转换成 2中的格式,代码如下:
在这里插入代码片
import cv2
import os
def change_labelimage_to_cptn_data(pictures_file_path, txt_file_path, cptn_data_labels_path):
list = os.listdir(txt_file_path)
# for txt_name in os.listdir(txt_file_path):
# txt_path = os.path.join(txt_file_path,txt_name).replace('\\','/')
# with open(txt_path,mode='rb') as f:
# data = f.readlines(txt_path)
# print(data)
for i in range(1, len(list)+1):
txt_path = txt_file_path + str(i).zfill(6) + '.txt' #原数据集(label-image标注的)对应的txt标签存放路径
dir = open(txt_path)
lines = dir.readlines()
lists = [] # 直接用一个数组存起来就好了
for line in lines:
lists.append(line.split())
print(lists)
im_path = pictures_file_path+str(i).zfill(6)+'.jpg' #原数据集图片存放路径
picture = cv2.imread(im_path)
# print(len(lists))
for j in range(0, len(lists)):
a = lists[j][1] #宽
b = lists[j][2] #高
c = lists[j][3] #宽度
d = lists[j][4] #高度
#根据txt标签中的归一化坐标还原为标注图像的真实坐标
e = int((float(a) * picture.shape[1]) - (float(c) *int(picture.shape[1])/2))
f = int((float(b) * picture.shape[0]) - (float(d) * picture.shape[0]/2))
q = int((float(a) * picture.shape[1]) + (float(c) * picture.shape[1]/2))
s = int((float(b) * picture.shape[0]) + (float(d) * picture.shape[0]/2))
print(e,f,q,s)
with open(cptn_data_labels_path + str(i).zfill(6)+'.txt', 'a+') as p:
p.write(str(e) + ',' + str(f) + ',' + str(q) + ',' + str(s) + '\n')
if __name__ == '__main__':
pictures_path = './standard-CTPN-label/image/' #图片路径
txt_path = './standard-CTPN-label/label/' #label-image标注的标签路径
ctpn_labels = './standard-CTPN-label/ctpn_labels/' #转换后,结果保存路径
change_labelimage_to_cptn_data(pictures_path, txt_path, ctpn_labels)
结果图片展示:

运行下面代码:split_label.py
在这里插入代码片
import os
import numpy as np
import math
import cv2 as cv
path = '/data/data/ldx/chinese_ocr/ctpn/erweima/image' #图片路径
gt_path = '/data/data/ldx/chinese_ocr/ctpn/erweima/label' #转换后的标签路径
out_path = 're_image'
if not os.path.exists(out_path):
os.makedirs(out_path)
files = os.listdir(path)
files.sort()
#files=files[:100]
for file in files:
_, basename = os.path.split(file)
if basename.lower().split('.')[-1] not in ['jpg', 'png']:
continue
stem, ext = os.path.splitext(basename)
gt_file = os.path.join(gt_path, stem + '.txt')
img_path = os.path.join(path, file)
print(img_path)
img = cv.imread(img_path)
img_size = img.shape
im_size_min = np.min(img_size[0:2])
im_size_max = np.max(img_size[0:2])
im_scale = float(600) / float(im_size_min)
if np.round(im_scale * im_size_max) > 1200:
im_scale = float(1200) / float(im_size_max)
re_im = cv.resize(img, None, None, fx=im_scale, fy=im_scale, interpolation=cv.INTER_LINEAR)
re_size = re_im.shape
cv.imwrite(os.path.join(out_path, stem) + '.jpg', re_im)
with open(gt_file, 'r') as f:
lines = f.readlines()
for line in lines:
splitted_line = line.strip().lower().split(',')
pt_x = np.zeros((4, 1))
pt_y = np.zeros((4, 1))
pt_x[0, 0] = int(float(splitted_line[0]) / img_size[1] * re_size[1])
pt_y[0, 0] = int(float(splitted_line[1]) / img_size[0] * re_size[0])
pt_x[1, 0] = int(float(splitted_line[2]) / img_size[1] * re_size[1])
pt_y[1, 0] = int(float(splitted_line[3]) / img_size[0] * re_size[0])
pt_x[2, 0] = int(float(splitted_line[4]) / img_size[1] * re_size[1])
pt_y[2, 0] = int(float(splitted_line[5]) / img_size[0] * re_size[0])
pt_x[3, 0] = int(float(splitted_line[6]) / img_size[1] * re_size[1])
pt_y[3, 0] = int(float(splitted_line[7]) / img_size[0] * re_size[0])
ind_x = np.argsort(pt_x, axis=0)
pt_x = pt_x[ind_x]
pt_y = pt_y[ind_x]
if pt_y[0] < pt_y[1]:
pt1 = (pt_x[0], pt_y[0])
pt3 = (pt_x[1], pt_y[1])
else:
pt1 = (pt_x[1], pt_y[1])
pt3 = (pt_x[0], pt_y[0])
if pt_y[2] < pt_y[3]:
pt2 = (pt_x[2], pt_y[2])
pt4 = (pt_x[3], pt_y[3])
else:
pt2 = (pt_x[3], pt_y[3])
pt4 = (pt_x[2], pt_y[2])
xmin = int(min(pt1[0], pt2[0]))
ymin = int(min(pt1[1], pt2[1]))
xmax = int(max(pt2[0], pt4[0]))
ymax = int(max(pt3[1], pt4[1]))
if xmin < 0:
xmin = 0
if xmax > re_size[1] - 1:
xmax = re_size[1] - 1
if ymin < 0:
ymin = 0
if ymax > re_size[0] - 1:
ymax = re_size[0] - 1
width = xmax - xmin
height = ymax - ymin
# reimplement
step = 16.0
x_left = []
x_right = []
x_left.append(xmin)
x_left_start = int(math.ceil(xmin / 16.0) * 16.0)
if x_left_start == xmin:
x_left_start = xmin + 16
for i in np.arange(x_left_start, xmax, 16):
x_left.append(i)
x_left = np.array(x_left)
x_right.append(x_left_start - 1)
for i in range(1, len(x_left) - 1):
x_right.append(x_left[i] + 15)
x_right.append(xmax)
x_right = np.array(x_right)
idx = np.where(x_left == x_right)
x_left = np.delete(x_left, idx, axis=0)
x_right = np.delete(x_right, idx, axis=0)
if not os.path.exists('label_tmp'):
os.makedirs('label_tmp')
with open(os.path.join('label_tmp', stem) + '.txt', 'a') as f:
for i in range(len(x_left)):
f.writelines("text\t")
f.writelines(str(int(x_left[i])))
f.writelines("\t")
f.writelines(str(int(ymin)))
f.writelines("\t")
f.writelines(str(int(x_right[i])))
f.writelines("\t")
f.writelines(str(int(ymax)))
f.writelines("\n")
生成两个文件
在运行:ToVoc.py
from xml.dom.minidom import Document
import cv2
import os
import glob
import shutil
import numpy as np
def generate_xml(name, lines, img_size, class_sets, doncateothers=True):
doc = Document()
def append_xml_node_attr(child, parent=None, text=None):
ele = doc.createElement(child)
if not text is None:
text_node = doc.createTextNode(text)
ele.appendChild(text_node)
parent = doc if parent is None else parent
parent.appendChild(ele)
return ele
img_name = name + '.jpg'
# create header
annotation = append_xml_node_attr('annotation')
append_xml_node_attr('folder', parent=annotation, text='text')
append_xml_node_attr('filename', parent=annotation, text=img_name)
source = append_xml_node_attr('source', parent=annotation)
append_xml_node_attr('database', parent=source, text='coco_text_database')
append_xml_node_attr('annotation', parent=source, text='text')
append_xml_node_attr('image', parent=source, text='text')
append_xml_node_attr('flickrid', parent=source, text='000000')
owner = append_xml_node_attr('owner', parent=annotation)
append_xml_node_attr('name', parent=owner, text='ms')
size = append_xml_node_attr('size', annotation)
append_xml_node_attr('width', size, str(img_size[1]))
append_xml_node_attr('height', size, str(img_size[0]))
append_xml_node_attr('depth', size, str(img_size[2]))
append_xml_node_attr('segmented', parent=annotation, text='0')
# create objects
objs = []
for line in lines:
splitted_line = line.strip().lower().split()
cls = splitted_line[0].lower()
if not doncateothers and cls not in class_sets:
continue
cls = 'dontcare' if cls not in class_sets else cls
if cls == 'dontcare':
continue
obj = append_xml_node_attr('object', parent=annotation)
occlusion = int(0)
x1, y1, x2, y2 = int(float(splitted_line[1]) + 1), int(float(splitted_line[2]) + 1), \
int(float(splitted_line[3]) + 1), int(float(splitted_line[4]) + 1)
truncation = float(0)
difficult = 1 if _is_hard(cls, truncation, occlusion, x1, y1, x2, y2) else 0
truncted = 0 if truncation < 0.5 else 1
append_xml_node_attr('name', parent=obj, text=cls)
append_xml_node_attr('pose', parent=obj, text='none')
append_xml_node_attr('truncated', parent=obj, text=str(truncted))
append_xml_node_attr('difficult', parent=obj, text=str(int(difficult)))
bb = append_xml_node_attr('bndbox', parent=obj)
append_xml_node_attr('xmin', parent=bb, text=str(x1))
append_xml_node_attr('ymin', parent=bb, text=str(y1))
append_xml_node_attr('xmax', parent=bb, text=str(x2))
append_xml_node_attr('ymax', parent=bb, text=str(y2))
o = {
'class': cls, 'box': np.asarray([x1, y1, x2, y2], dtype=float), \
'truncation': truncation, 'difficult': difficult, 'occlusion': occlusion}
objs.append(o)
return doc, objs
def _is_hard(cls, truncation, occlusion, x1, y1, x2, y2):
hard = False
if y2 - y1 < 25 and occlusion >= 2:
hard = True
return hard
if occlusion >= 3:
hard = True
return hard
if truncation > 0.8:
hard = True
return hard
return hard
def build_voc_dirs(outdir):
mkdir = lambda dir: os.makedirs(dir) if not os.path.exists(dir) else None
mkdir(outdir)
mkdir(os.path.join(outdir, 'Annotations'))
mkdir(os.path.join(outdir, 'ImageSets'))
mkdir(os.path.join(outdir, 'ImageSets', 'Layout'))
mkdir(os.path.join(outdir, 'ImageSets', 'Main'))
mkdir(os.path.join(outdir, 'ImageSets', 'Segmentation'))
mkdir(os.path.join(outdir, 'JPEGImages'))
mkdir(os.path.join(outdir, 'SegmentationClass'))
mkdir(os.path.join(outdir, 'SegmentationObject'))
return os.path.join(outdir, 'Annotations'), os.path.join(outdir, 'JPEGImages'), os.path.join(outdir, 'ImageSets',
'Main')
if __name__ == '__main__':
_outdir = 'TEXTVOC/VOC2007'
_draw = bool(0)
_dest_label_dir, _dest_img_dir, _dest_set_dir = build_voc_dirs(_outdir)
_doncateothers = bool(1)
for dset in ['train']:
_labeldir = 'label_tmp'
_imagedir = 're_image'
class_sets = ('text', 'dontcare')
class_sets_dict = dict((k, i) for i, k in enumerate(class_sets))
allclasses = {
}
fs = [open(os.path.join(_dest_set_dir, cls + '_' + dset + '.txt'), 'w') for cls in class_sets]
ftrain = open(os.path.join(_dest_set_dir, dset + '.txt'), 'w')
files = glob.glob(os.path.join(_labeldir, '*.txt'))
files.sort()
for file in files:
path, basename = os.path.split(file)
stem, ext = os.path.splitext(basename)
with open(file, 'r') as f:
lines = f.readlines()
img_file = os.path.join(_imagedir, stem + '.jpg')
print(img_file)
img = cv2.imread(img_file)
img_size = img.shape
doc, objs = generate_xml(stem, lines, img_size, class_sets=class_sets, doncateothers=_doncateothers)
cv2.imwrite(os.path.join(_dest_img_dir, stem + '.jpg'), img)
xmlfile = os.path.join(_dest_label_dir, stem + '.xml')
with open(xmlfile, 'w') as f:
f.write(doc.toprettyxml(indent=' '))
ftrain.writelines(stem + '\n')
cls_in_image = set([o['class'] for o in objs])
for obj in objs:
cls = obj['class']
allclasses[cls] = 0 \
if not cls in list(allclasses.keys()) else allclasses[cls] + 1
for cls in cls_in_image:
if cls in class_sets:
fs[class_sets_dict[cls]].writelines(stem + ' 1\n')
for cls in class_sets:
if cls not in cls_in_image:
fs[class_sets_dict[cls]].writelines(stem + ' -1\n')
(f.close() for f in fs)
ftrain.close()
print('~~~~~~~~~~~~~~~~~~~')
print(allclasses)
print('~~~~~~~~~~~~~~~~~~~')
shutil.copyfile(os.path.join(_dest_set_dir, 'train.txt'), os.path.join(_dest_set_dir, 'val.txt'))
shutil.copyfile(os.path.join(_dest_set_dir, 'train.txt'), os.path.join(_dest_set_dir, 'trainval.txt'))
for cls in class_sets:
shutil.copyfile(os.path.join(_dest_set_dir, cls + '_train.txt'),
os.path.join(_dest_set_dir, cls + '_trainval.txt'))
shutil.copyfile(os.path.join(_dest_set_dir, cls + '_train.txt'),
os.path.join(_dest_set_dir, cls + '_val.txt'))
最后生成一个文件:
![]()
参考博客:https://blog.csdn.net/monk1992/article/details/99670559
https://github.com/YCG09/chinese_ocr