AMNet
Deep Atrous Muliscale Stereo Disparity Estimation Networks
萱萱翻
摘要:提出了一种新的立体视差估计深度学习结构。提出的AMNet采用高效的特征提取器和深度卷积,扩展的coat volume在深度特征上提出了新的构成方式。提出了一种堆叠的多尺度网络,从coat volume中提取丰富的多尺度上下文信息,从而在多尺度上对视差进行高精度估计。AMNet可以进一步修改为一个前-后台感知网络FBAAMNet,可以在多尺度场景中区分前景和背景对象。提出了一种用于训练FBA-AMNet端到端的迭代多任务学习方法。提出的视差估计网络AMNet和FBA-AMNet能够准确地进行视差预估并在极具挑战性的middlebury,KITTI 2012, KITTI 2015,和Sceneflow上有较好的表现。
介绍:深度估计是一个基本的计算机视觉问题意在捕获场景中每个点的距离。准确的深度估计有许多应用,如场景理解、自动驾驶、计算摄影和改进、通过合成Bokeh效果来提高图像的审美质量。给定一个经过校正的立体图像,对深度的估计可以通过视差估计和摄像机标定来实现。对一幅图像中的某一像素,视差估计是找出这个像素与其对应像素(在同一水平线上的另一幅图像的对应像素)之间的位移。
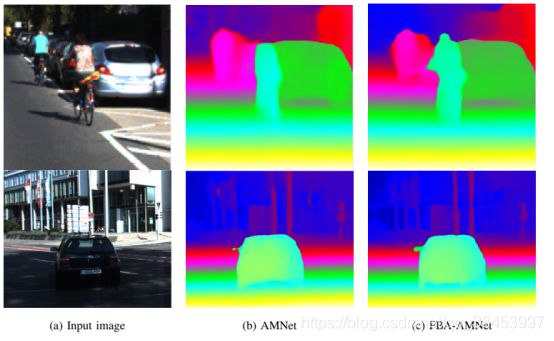
图1:由提出的多尺度网络(AMNet-32)和提出的前-背景感知AMNet (FBA-AMNet-32)对来自KITTI测试图像的两个具有挑战性的前景对象生成的视差图。
基于立体图像对的视差估计是计算机视觉中的一个重要问题。通常首先对立体图像进行极线校正,从而使左右两侧的相应像素位于同一水平线上。视差估计通常包括三个或四个步骤:特征提取、匹配成本计算、视差聚合,视差细化。计算给定视差下的匹配成本是基于对一个函数的评估,该函数测量了具有视差偏移的左右图像像素之间的相似度,它可以简单地表示为给定视差下像素强度的绝对差异的总和。由于光照差异、不一致性、雨雪耀斑、遮挡等环境因素的影响,直接计算像素强度的匹配成本容易产生误差。因此,首先从局部二进制和局部稠密编码中提取特征,可以提高传统立体匹配方法的鲁棒性。视差聚合可以通过简单地将计算出的代价聚合在局部框窗口上,或者通过cost volume滤波来实现。视差计算可以采用局部法、全局法或半对数法。半球形匹配(SGM)[6]被认为是最流行的方法,因为它比基于局部窗口的方法更健壮,并且通过沿着八个一维路径对每个像素的二维能量函数近似最小化来实现成本聚合。SGM没有全局方法那么复杂,例如GC,它最小化了光滑项具有完整二维连通性的二维能量函数。传统上,视差细化是通过进一步检查左右一致性、使遮挡和不匹配、失效以及通过传播邻近视差值来填充无效段来完成的。最近,在收集具有立体输入图像的数据集及其地面真实视差图方面做了大量的工作,例如SceneFlow[8]、KITTI 2012[9]、KITTI 2015[10]和Middlebury[11]立体基准数据集。这些数据集的存在使得深度神经网络能够进行立体匹配任务的监督训练。卷积神经网络(CNN)已经成为解决图像处理和计算机视觉问题的普遍应用。基于cnn的视差估计系统借鉴了经典的视差估计系统,构成了基于cnn的视差估计系统,不同的模块试图执行相同的四项任务:特征提取、匹配成本估计、视差聚合以及视差细化。首先,使用深度卷积网络,如ResNet-50或VGG-16,从经过校正的左右图像中提取深度特征。通过测量提取的左右深度特征图之间的匹配代价,形成cost volume(CV)。对于匹配成本的典型选择可以是简单的特征串连,也可以是计算绝对距离或相关性等的度量。CV由视差计算模块进一步处理和细化,该模块回归到估计的视差。然后可以使用细化网络进一步细化初始粗糙深度或视差估计。
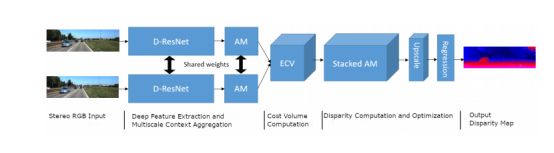
图2:提出的用于立体视差估计的多尺度网络(AMNet)的体系结构。
在这项工作中,我们提出了一种新的立体视差估计的深度神经网络架构,即AMNet。提出的网络结构如图2所示。在设计特征提取器时,我们首先将标准的ResNet-50主链修改为深度可分ResNet (D-ResNet),这样就可以在不增加可训练参数的情况下设计更大的接受域网络。其次,我们提出了AM模块,它被设计成一个场景理解模块,在多个尺度上捕获全局上下文信息以及局部细节。我们提出的特征提取器由D-ResNet和AM模块组成。对于成本匹配计算,我们设计了一个新的扩展cost volume(ECV),它同时计算不同的成本匹配指标,并由几个成本子体积组成;(a disparityshifted feature concatenation sub-volume, a disparity-level depthwise correlation sub-volume, a disparity-level feature distance sub-volume)。ECV承载了来自不同相似性度量的匹配成本的丰富信息。对于视差计算和聚集,ECV由设计的堆叠AM模块进行处理,该模块堆叠多个AM模块进行多尺度上下文聚合。对量化后的视差体进行软分类后,通过回归进行视差优化。为了改进视差计算和优化步骤,我们还提出了学习背景分割作为辅助任务。我们使用多任务学习来训练AMNet,主要任务是视差估计,辅助任务是前-背景分割。我们将多任务网络命名为前置后台感知AMNet (FBA-AMNet)。辅助任务帮助网络具有更好的前背景感知,从而进一步改善视差估计。如前所述,视差细化的可选步骤可以进一步改善视差估计。然而,在这项工作中,没有对估计的差异进行细化。
AMNet:
分 部分来讲:
A:深度可分特征提取:

提出了一种残差连接的深度可分卷积的特征提取。标准卷积可以分解为跟随着1*1卷积的深度可分卷积。深度可分卷积最近在图像分类[37]中显示出了巨大的潜力,并作为网络主干[38][32][39]被进一步发展用于其他计算机视觉任务。深度可分残差网络也被提出用于图像增强任务,如图像去噪[40]。
在这些工作的启发下,我们设计了D-ResNet作为特征提取主干,用定制的深度可分卷积代替标准卷积。我们的方法与以前的方法不同,以前的方法的目标是减少复杂性。相反,我们使用深度可分卷积来增加剩余网络的学习能力,同时保持可训练参数的数量不变。深度可分离卷积将三维卷积替换为在每个输入通道上分别进行的二维卷积(深度),然后进行逐点的1×1卷积,将各个卷积的输出组合成输出特征图。设Din和Dout分别表示卷积层上输入和输出特征映射的数量。一个标准的3×3卷积层包含9×Din×Dout参数,而一个深度可分卷积层包含Din×(9 + Dout)参数,对于Din和Dout的典型选择,该参数要小得多。
我们将PSMNet[19]中提出的50层残差网络(ResNet)改进为一个特征提取器,它由4组残差块组成,每个残差块包含2个卷积层,每个卷积层有3×3个卷积核。4组残块数分别为{3,16,3,3}。在PSMNet的ResNet中,四个残差组的输出feature map的数量分别为Dout ={32, 64, 128, 128},其中Din = Dout为所有残差块。由于Dout为32或更大,用深度可分卷积直接替换标准卷积将得到参数数量少得多的模型。然而,在我们提出depth-separable ResNet (D-ResNet),我们增加Dout切除分离卷积层四个剩余块Dout ={96、256、256、256},分别在Din = 32第一块,使参数的数量在提出D-ResNet PSMNet的接近。因此,所提出的D-ResNet在具有相似复杂度的情况下,可以学习比ResNet更深入的特性。由于我们提出的深度可分离的剩余块不一定具有相同数量的输入和输出特性,我们在快捷(剩余)连接上部署Dout点1×1投影过滤器,将Din输入特性投射到Dout特性上。图5显示了标准ResNet块和建议的D-ResNet块之间的比较。每一层之后使用ReLU和Batch归一化。在D-ResNet主干之后,输出特征图的宽度和高度是输入图像的第14个。D-ResNet主干网的网络规范列于表一。
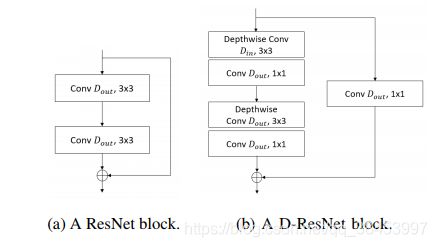
图5:ResNet块的网络结构(左)和提出的深度可分ResNet块(D-ResNet)的网络结构(右)。该D-ResNet块在快捷连接中有一个点形投影层,用于在块的输入和输出特性之间匹配维度。
B:多尺度上下文聚合:
由于视差估计的准确性依赖于在多个尺度上识别关键特征的能力,因此我们考虑从深度特征中聚合多尺度上下文信息。深度或视差估计网络倾向于使用下采样、上采样或编译码架构,也称为沙漏架构在多个尺度上聚合信息。但是通过汇聚或下采样,空间分辨率容易丢失,我们在D-ResNet骨干网之后使用AM模块来形成特征提取器。D-ResNet从立体图像对中提取的深度特征,在使用atrous multiscale (AM)模块计算视差之前,对其进行处理,如图2所示。受上下文网络和沙漏模块的启发,我们设计了一个AM模块,它是一组3×3的卷积,增加了膨胀因子,如[1,2,2,4,4,…],k2, k2, k)。膨胀率随着AM模块的深入而增加,以扩大感受野,并在不损失空间分辨率的情况下捕获更密集的多尺度上下文信息。最后加入2个1×1的卷积,并加入膨胀率1,进行特征细化和特征大小调整。
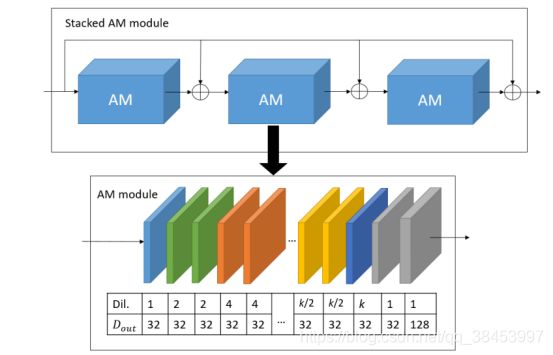
图6:提出的Atrous多尺度(AM)模块和堆叠的AM (SAM)模块的架构。
C:extended cost volume aggregation
我们提出了一个扩展的成本体(ECV),它结合了不同的方法为视差成本指标多样化的信息提取的真正的视差。cost volume以D-ResNet从左侧图像和右侧图像中提取的深度特征作为输入,分别标记为Fl和Fr。ECV由三个串联的成本体组成:视差级特征距离、视差级深度相关和视差级特征串联。假设D为AMNet所设计的最大视差,则可能的整数视差移位为D ={0,1,…D}。下面描述了连接起来形成ECV的三个构建成本卷。
(i)视差等级特征连接:让Fr (d)是指当d像素转移到正确的深度特性结合Fl,连同必要的削减和补零Fl形成Fl (d), d∈左特征图谱Fl (d)和视差一致的特征图谱Fr (d)是连接所有差距水平d∈让W H, C,分别是宽度,高度,和深度的特征图谱Fl和Fr。然后,这个成本的大小体积W* H×2 C* (d + 1)。
(ii)视差水平特征距离:在所有的视差水平d上计算Fl和Fr(d)的点向绝对差异。所有的d + 1距离图被打包在一起,形成大小为H×W×(d + 1)×C的子卷
(iii)视差水平深度相关:在[15]之后,以Fl中的x1为中心的patch p1与以Fr中的x2为中心的patch p2之间的相关关系被定义为一个大小为2t + 1的正方形patch如Eq. 1所示:
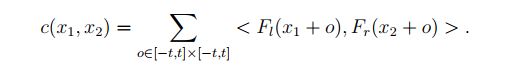
与[15]不同的是,我们不是计算p1与以x1的大小D为中心的所有其他patch之间的相关性(沿着水平线扩展),而是计算p1与其对应的patch在所有视差级别上的一致性Fr之间的相关性(沿着视差级别扩展)。这导致了大小为H×W×(D + 1)×1的子体积。为了使输出特征映射的大小与其他子卷的大小相比较,我们实现了深度相关。在每个视差水平上,对深度指数i∈{1,2,…的所有深度通道计算并打包两个对齐的patch的深度相关性。, C},由Eq. 2和Eq. 3可知
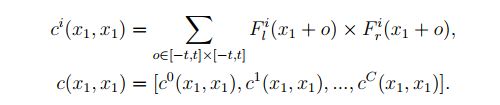
计算所有视差水平上的所有patch的深度相关,并将其串联起来,形成一个大小为H×W×(D + 1)×C的代价体积。最终的ECV尺寸为H×W×(D+1)×4C。为了将ECV信息与更粗到细的上下文信息聚合在一起,我们建议将三个具有内部快捷连接的AM模块级联,以形成堆叠的AM模块(SAM)。提出的AM模块和SAM模块的架构如图6所示。注意,由于ECV的构造引入了视差维数,所以堆叠的AM模块采用3D卷积来处理ECV。
d .视差优化
利用平滑的L1损耗,在第i个像素处测量预测视差di与地面真视差dgti之间的差异。损失计算为所有标记像素的平均平滑L1损失。在训练过程中,在SAM模块中三个AM模块的输出处分别计算三个损耗,并汇总形成最终的损耗,如Eq.(4)和Eq.(5)所示:
其中N为标记像素的总数。在测试期间,只有最后一个AM模块的输出用于视差回归。在每个输出层,使用软argmin操作[33]进行视差回归计算预测视差。在每个像素处,对D中的每个视差值进行分类概率,计算D + 1视差的期望作为视差预测,如式6所示:

其中pji为像素i处视差j的softmax概率,D为最大视差值。
四、前-后感知多尺度网络
考虑到在前景物体出现的位置上,视差会发生剧烈的变化,我们推测,对前景物体更好的感知将导致更好的视差估计。在像KITTI这样的户外驾驶场景中,我们将前景对象定义为车辆和人。在这项工作中,我们利用前-背景分割地图来改进视差估计。我们只区分前景和背景像素。
我们考虑了利用前-背景分割信息的不同方法:第一种方法是直接将额外的前-背景分割信息作为RGB图像(RGB- s输入)之外的额外输入来引导网络。这需要在训练和测试阶段精确的分割地图。第二种方法是将网络训练成多任务网络。多任务网络被设计成有一个共享的基础和两个不同的头。多任务网络被设计成有一个共享的基础和两个不同的头。通过对多任务网络进行优化,使共享基隐含地对前景对象有更好的感知,从而得到更好的视差估计。这种方法是通过尝试学习FBA的辅助任务来提高主分支的识别能力,不需要一个独立的分割网络,这是非常复杂的。所提出的FBA-AMNet的网络结构如图7所示。在特征提取器中,主要任务是视差估计,辅助任务是前-背景分割。在特征提取器的基础上,加入二分类层、上采样层和软最大层进行前-背景分割
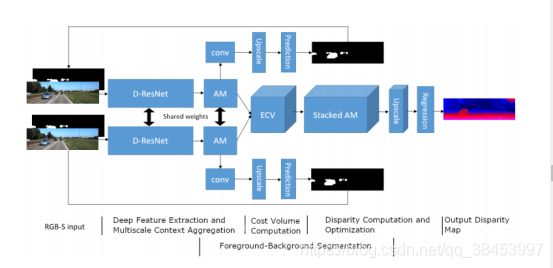
图7:用于立体视差估计的多任务前-背景感知多尺度网络(FBA-AMNet)的体系结构。
网络是训练有素的端到端使用多任务学习的损失函数的加权组合损失的差异误差和foreground-background分类误差L = Ldisp +λLseg,这样λ是分割的相对重量损失。我们提出一种迭代法来训练FBA-AMNet。在每个epoch之后,将最新的估计分割地图与RGB输入连接起来,在下一个epoch形成一个RGB- s输入到FBA-AMNet。在训练过程中,网络不断细化和利用其前景-背景分割预测,从而更好地学习前景对象的识别。在推理阶段,忽略分割任务,使用零映射作为额外的输入。
与以往利用语义分割[17]、[20]的方法不同,本文提出的前-背景感知(FBA)网络并不区分不同类别的前景对象和不同类别的背景。我们在消融研究中表明,这种前后台感知比使用完整的语义分割提供了更准确的视差估计。其中一个原因是前后台分割比全语义分割更容易学习,可以使网络优化更专注于视差估计这一主要任务。