Hive-命令行基本操作和java API访问hive数据库
安装
首先说明hive的安装。
链接: http://pan.baidu.com/s/1DleVG 密码: mej4
这个链接是一个视频的链接,视频中讲解了如何安装hive。
关于视频中用到的资料文件,我已经上传到CSDN,请点击这里下载。
按照视频中的讲解步骤,完全可以完成hive的安装和调试。
命令行基本操作
命令行基本操作无非就是增删改查。

进入hive的命令行模式,命令:hive
建议进入命令行模式使用Hive的安装目录下的bin目录下,因为可能当运行命令的当前目录下生成一些日志文件,时间久了,自己都不知道这些文件是做什么的了。
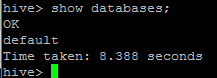
命令:show databases;
分号作为命令行结束符。

命令:use default;
show tables;
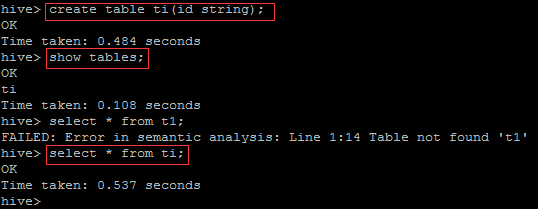
创建表,并查询。
create table ti(id string);
show tables;
select * from ti;

向表中加载数据
load data local inpath ‘/usr/local/id’ into table tb1;
没有local的话:
load data inpath ‘HDFS文件路径’ into table [tablename]
,则文件路径指的是HDFS文件系统
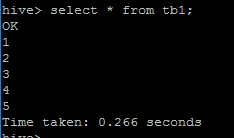
加载数据之后,进行查询验证。

删除表:
drop table tb1;
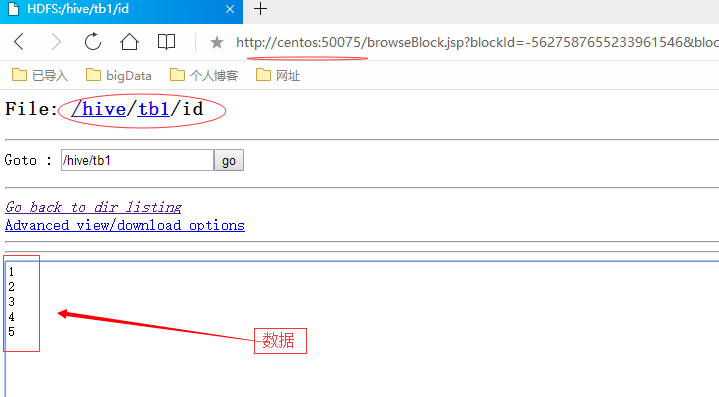
这幅图是通过浏览器远程访问HDFS所看到的Hive管理的数据库的文件。HIve管理的数据库是使用HDFS文件系统的方式进行的。所以数据库的数据都是文件,并可以通过HDFS查看到。图中看到的就是数据表tb1的数据。
制表符进行分割
CREATE TABLE t2(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
分区表命令
CREATE TABLE t3(id int) PARTITIONED BY (day int);
LOAD DATA LOCAL INPATH ‘/root/id’ INTO TABLE t1 PARTITION (day=22);
桶表命令
create table t4(id int) clustered by(id) into 4 buckets;
set hive.enforce.bucketing = true;
使用桶加载数据 不能使用load data方式加载数据
insert into table t4 select id from t3;
外部表命令
create external table t5(id int) location ‘/external’;
连接查询
Hive支持连接查询,但有一些条件必须遵守,比如只支持相等查询,其它查询如不等式查询则不支持,还支持外连接,左半连接查询。另外Hive支持多于两个表以上的连接查询
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)table_reference:
table_factor
| join_tabletable_factor:
tbl_name [alias]
| table_subquery alias
| ( table_references )join_condition:
ON equality_expression ( AND equality_expression )*equality_expression:
expression = expression
首先是Hive中的连接查询只支持相等连接而不支持不等连接查询:
//有效的连接查询,相等连接查询
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
//无效的连接查询,Hive不支持不等连接查询
SELECT a.* FROM a JOIN b ON (a.id <> b.id)
其次是Hive支持两个表以上的连接查询:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) 如果所有jion子句都使用了某个表的相同列,Hive将多个表的连接查询转换为一个map/reduce作业。如下所示:
//由于jion子句中使用了表b的key1列,该查询转换为一个作业
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) //由于表b的key1列用在第一个jion子句中,key2列用在第二个jion子句中,该查询被转换为两个作业,第一个作业执行表a和b的连接查询,第二个作业将第一个作业的结果与第二个jion子句进行连接查询
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) 在每个join的map/reduce阶段,序列中的最后一个表是以流的方式通过reducers,而其它表则缓存在reducers的内存中。这样通过将最大的表放在序列的最后有助于减少reducers的内存需求。如:
//下面的查询中,从a和b中满足条件的行中提取a.val和b.val,并缓存在reducers的内存中,对于从c中提取的每行记录,与缓存中的行进行连接计算
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) //下面的查询包含两个作业,第一个作业缓存a的值,将b的值以流的方式通过reducers,第二个作业缓存结果,并将c的值以流的方式通过reducers。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) 在每个join的map/reduce阶段,可以通过提示指定要流处理的表:
//下面的查询中b.val和c.val缓存在reducers的内存中,对于从a中提取的每行记录,与缓存中的行进行连接计算。如果省略STREAMTABLE提示,jion中最右边的表被流处理
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)LEFT,RIGHT和FULL OUTER,即左连接,右连接和全连接,为当ON从句不匹配时提供了更多的控制,如:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)该查询将返回a中的所有行,当a.key=b.key时返回a.val,b.val,没有对应的b.key时返回a.val,NULL,b中没有对应的a.key的行将会丢掉。”FROM a LEFT OUTER JOIN b”必须写在一行中为了理解该语句是如何工作的—a在b的左侧,a中的所有行被保留。RIGHT OUTER JOIN将保留b中所有的行,FULL OUTER JOIN将保留a中的所有行和b中的所有行。
Join出现在WHERR子句之前。因此如果想限制连接查询的输出,限制条件应该出现在WHERE子句中,否则应该出现在JOIN子句中。当在分区表上执行连接查询时或许会有一些困惑:
//ds为分区列
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds='2009-07-07' AND b.ds='2009-07-07' 当该左外连接在a中发现key而在b中没有发现key时,b中的列将为null,包括分区列ds,也就是将会过滤掉连接查询输出中没有有效b.key的列,或者说左外连接与WHERE子句中引用的b中的任何列无关。相反下面的语句将会提前根据条件过滤:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b
ON (a.key=b.key AND b.ds='2009-07-07' AND a.ds='2009-07-07') Join连接是不可以交换的,无论是LEFT还是RIGHT连接都是左结合的。看下面的示例:
SELECT a.val1, a.val2, b.val, c.val
FROM a
JOIN b ON (a.key = b.key)
LEFT OUTER JOIN c ON (a.key = c.key) 第一个连接a和b,丢掉所有不满足条件的记录,结果再与c进行左外连接。如果当key存在于a和c中但不在b中时,结果不是直观的。A中包含key的行丢弃掉,应为b中没有与key对应的行,这样结果将不包含key,再与c进行左外连接时将不包含c.val,该值将为null。如果是RIGHT OUTER JOIN的话,结果将为null,null,null,c.val,分析方法同分析左外连接一样。
左半连接以高效的方式实现了IN/EXISTS子查询。左半连接的限制是右侧的表只能出现在ON子句中,不能出现在WHERE或者SELECT子句中,如:
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
//两者是等价的
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key) 如果除了一个表以外的所有正在连接的表都比较小,连接操作可以只作为map作业执行,如:
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a join b on a.key = b.key该查询不需要reducer任务,对于A的每个mapper,B被完全读取。但a FULL/RIGHT OUTER JOIN b不能被执行。如果正在连接查询的表在连接列上进行了分桶,并且一个表的桶数是另一个表的桶的倍数,桶可以彼此连接。如果表a有4个桶,b有4个桶,那么下面的连接查询可以仅适用mapper任务完成:
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a join b on a.key = b.key 与对于a的每个mapper任务都读取整个b不同,只读取被要求的桶。对于上面的查询,处理a的桶1的mapper任务只读取b的桶1,但这不是默认行为,可以使用下面的参数进行配置管理:
hive.optimize.bucketmapjoin = true //默认值为false 如果表在排序和分桶的列上进行连接查询,且它们有相同的桶,那么合并查询可以被执行。对应的桶在mapper任务中彼此连接,该过程同上。但需要设置下面的参数:
hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;//默认为org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
hive.optimize.bucketmapjoin = true; //默认值为false
hive.optimize.bucketmapjoin.sortedmerge = true; //默认值为false 子查询语法
SELECT ... FROM (subquery) name ...Hive只在FROM字句支持子查询。子查询必须给一个名字,因为每个表在FROM字句必须有一个名字。子查询的查询列表的列,必须有唯一的名字。子查询的查询列表,在外面的查询是可用的,就像表的列。子查询也可以一个UNION查询表达式.Hive支持任意层次的子查询。
简单子查询的例子:
SELECT col FROM (
SELECT a+b AS col FROM t1
) t2
包含UNION ALL的子查询例子:
SELECT t3.col FROM (
SELECT a+b AS col FROM t1
UNION ALL
SELECT c+d AS col FROM t2
) t3视图view
Hive 0.6版本及以上支持视图
Hive View具有以下特点:
1. View是逻辑存在,Hive暂不支持物化视图(1.0.3)
2. View只读,不支持LOAD/INSERT/ALTER。需要改变View定义,可以是用Alter View
3. View内可能包含ORDER BY/LIMIT语句,假如一个针对view的查询也包含这些语句, 则view中的语句优先级高。例如,定义view数据为limit 10, 针对view的查询limit 20,则最多返回10条数据。
4. Hive支持迭代视图
创建View
CREATE VIEW [IF NOT EXISTS] view_name [(column_name [COMMENT column_comment], ...) ]
[COMMENT view_comment]
[TBLPROPERTIES (property_name = property_value, ...)]
AS SELECT ... 删除view
DROP VIEW [IF EXISTS] view_name 修改view
ALTER VIEW view_name SET TBLPROPERTIES table_properties
table_properties:
: (property_name = property_value, property_name = property_value, ...) 查询视图的定义信息
DESCRIBER EXTENDED viewnameEXPLAIN语法
Hive提供EXPLAIN命令,显示查询的执行计划。语法如下:
EXPLAIN [EXTENDED] queryEXPLAIN语句使用EXTENDED,提供执行计划关于操作的额外的信息。这是典型的物理信息,如文件名。
Hive查询被转换成序列(这是一个有向无环图)阶段。这些阶段可能是mapper/reducer阶段,或者做metastore或文件系统的操作,如移动和重命名的阶段。 EXPLAIN的输出包括三个部分:
查询的抽象语法树
执行计划计划的不同阶段之间的依赖关系
每个场景的描述
场景的描述,显示了与元数据相关操作的操作序列。元数据会包括FilterOperator的过滤器表达式,或SelectOperator的查询表达式,或FileSinkOperator的文件输出名字。
排序和聚集
//where和having的区别:
//where是先过滤再分组(对原始数据过滤),where限定聚合函数
hive> select count(*),age from tea where id>18 group by age;
//having是先分组再过滤(对每个组进行过滤,having后只能跟select中已有的列)
hive> select age,count(*) c from tea group by age having c>2;
//group by后面没有的列,select后面也绝不能有(聚合函数除外)
hive> select ip,sum(load) as c from logs groupby ip sort by c desc limit 5;
//distinct关键字返回唯一不同的值(返回age和id均不相同的记录)
hive> select distinct age,id from tea;
//hive只支持Union All,不支持Union
//hive的Union All相对sql有所不同,要求列的数量相同,并且对应的列名也相同,但不要求类的类型相同(可能是存在隐式转换吧)
select name,age from tea where id<80
union all
select name,age from stu where age>18;Order By特性:
对数据进行全局排序,只有一个reducer task,效率低下。
与mysql中 order by区别在于:在 strict 模式下,必须指定 limit,否则执行会报错
使用命令set hive.mapred.mode; 查询当前模式
使用命令set hive.mapred.mode=strick; 设置当前模式
hive>select*from logs where date='2015-01-02'orderby te;
FAILED: SemanticException 1:52In strict mode,
ifORDERBYis specified, LIMIT must also be specified.
Error encountered near token 'te'对于分区表,还必须显示指定分区字段查询
hive>select*from logs orderby te limit 5;
FAILED: SemanticException [Error 10041]:
No partition predicate found for Alias "logs" Table "logs"order by 时,desc NULL 值排在首位,ASC时NULL值排在末尾
Sort BY特性:
可以有多个Reduce Task(以DISTRIBUTE BY后字段的个数为准)。也可以手工指定:set mapred.reduce.tasks=4;
每个Reduce Task 内部数据有序,但全局无序
set mapred.reduce.tasks =2;
insert overwrite local directory '/root/hive/b'select*from logs
sort by te;上述查询语句,将结果保存在本地磁盘 /root/hive/b ,此目录下产生2个结果文件:000000_0 + 000001_0 。每个文件中依据te字段排序。
Distribute by特性:
按照指定的字段对数据进行划分到不同的输出 reduce 文件中
distribute by相当于MR 中的paritioner,默认是基于hash 实现的
distribute by通常与Sort by连用
set mapred.reduce.tasks =2;
insert overwrite local directory '/root/hive/b'select*from logs
distribute by date
sort by te;Cluster By特性:
如果 Sort By 和 Distribute By 中所有的列相同,可以缩写为Cluster By以便同时指定两者所使用的列。
注意被cluster by指定的列只能是降序,不能指定asc和desc。一般用于桶表
set mapred.reduce.tasks =2;
insert overwrite local directory '/root/hive/b'select*from logs
cluster by date;JAVA API操作Hive数据库
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class HiveDemo {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.hadoop.hive.jdbc.HiveDriver");
Connection connection = DriverManager.getConnection("jdbc:hive://centos:10000/default", "", "");
Statement stmt = connection.createStatement();
String querySQL="select * from default.tb1";
ResultSet resut = stmt.executeQuery(querySQL);
while (resut.next()) {
System.out.println(resut.getInt(1));
}
}
}以上代码就是通过java api操作hive数据库,获取数据然后打印。
在运行上面的命令之前,需要在linux系统中启动hive的远程服务,命令如下:
hive –service hiveserver >/dev/null 2>/dev/null &
这条命令启动hive的远程服务,分毫不差,直接输入回车就可以了。然后运行上面的java 代码,运行结果如下:

可以看到结果已经正确打印出来了。
内容引用了网上的比较多的内容。在此感谢众多同行的付出!如有侵权,请见谅!^_^~~
关于代码,如果感兴趣,请点击我的github关注整个项目。整个项目中不仅仅本文提到的hive的简单操作,还有MapReduce,Zookeeper等简单的应用。欢迎关注。^_^