每日一学 Scale和Normalization
kaggle上的数据清洗教程第二天---Scale和Normalization
(不知道如何翻译会比较好,参考了其他博客,scale为缩放,normalization 为正则化)
1.Scale
1.1 粗略理解
将数据转为为特定范围的数据,比如(0,1)或者(0,100)
1.2 例子
a.对于SVM和KNN方法,由于涉及数据点之间的距离度量,则需要对数据进行scale,使得任何特征中的“1”的变化具有相同重要性。比如,1美元和1日元,如果没有scale,SVM和KNN会把1美元和1日元视为同等重要的
1.3 采用min-max标准化的code
import numpy as np
from mlxtend.preprocessing import minmax_scaling#区别与sklearn.preprocessing中的minmax_scale
import seaborn as sns
import matplotlib as plt
np.random.seed(0)#保证几次用到随机产生数据的随机相同
ori_data = np.random.exponential(size=100)#产生一个数据点数量为100的指数分布
scaled_data = minmax_scaling(ori_data,columns)#对数据第0列进行scale,默认scale到(0,1)之间,具体的scale方式见后续部分
fig,ax = plt.subplots(1,2)
sns.distplot(ori_data,ax=ax[0])
ax[0].set_title("Original data")
sns,distplot(scaled_data,ax=ax[1])
ax[1].set_title("Scaled data")
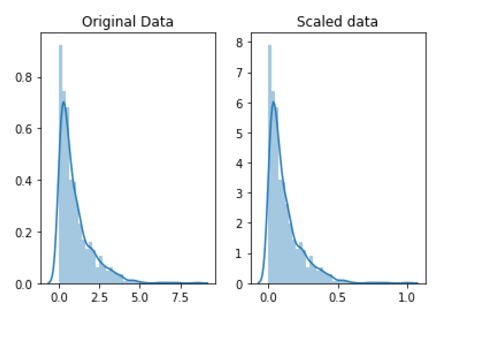
观察上述结果,可以看到横轴的数据范围已经转为(0,1)了
1.4 关于minmax_scale 和minmax_scaling
minmax_scale 是来自 sklearn.preprocessing sklearn-minmax_scale
minmax_scaling 是来自 mlxtend.preprocessing mxltend-minmax_scaling
(mxltend也是用于数据分析的工具和扩展库,主页:mlxtend主页)
对于sklearn中的minmax_scale,有个博客写到
X_std = (X-X_min(axis=0))/(X_max-Xmin(axis))
X_scaled = S_std*(max-min)+min
2.Normalization
2.1粗略理解:
正则化/标准化是使得数据服从正态分布(平均值和中位数的是相同的),在机器学习中,有些方法的前提是假设数据服从正态分布的,如t-检验-Wiki/t-检验 -百度,方差分析(ANOVAS)ANOVAS-wiki/百度,线性回归,线性判别分析,高斯朴素贝叶斯。
2.2 code
from scipy import stats ##引入box cox变换
ori_data = np.random.exponential(size=100)##同上
norm_data = stats.boxcox(ori_data)#stats

2.3 boxcox变换
box-cox变换的详细介绍BOX-COX overview 中提到box-cox变换是保证线性模型的一般假设,在百度上看到说的是用于连续的响应变量不满足正态分布的情况,变换之后,可一定成都上减小不可观测误差和预测相关变量的相关性(好吧,我没完全理解)。具体数学表达如下图:

碎碎念(在评论区看到的一些观点)
1.通过scale和normalization,不但能满足机器学习算法的一些基本假设,保证算法可靠,还有助于提高算法收敛速度,以及达到更高的精度。详见转载博客。
2.XGBoost不需要扩展数据,因为该方法不基于数据点之间距离的度量
3.一般而言,对于参数估计,用normalization 比较多,基于距离的,用scale比较多
4.网上有博客说scale是归一化,是标准化的一种,希望有了解的小伙伴指导。
5.对训练集进行normalization了,那么如何对测试集相同的normalization呢?
可以通过保存标准化训练数据时生成的lambda来实现,然后使用它来转换测试数据
# generate non-normal data
original_data = np.random.exponential(size = 1000)# split into testing & training data
train,test = train_test_split(original_data, shuffle=False)
# transform training data & save lambda valuetrain_data,fitted_lambda = stats.boxcox(train)
# use lambda value to transform test data
test_data = stats.boxcox(test, fitted_lambda)