Mycat水平分表
项目中一张表的数据量不断的增大,这样到导致了数据查询效率底下,这个时候我们通常可以采用水平分表,将该表进行水平切分保存在不同的数据库中。
分配策略:可以按照id的生成规则区,也可以按照用户存在的地理位置区分等等。
如:
步骤:
1.配置schema.xml
select user()
select user()
2.配置rule.xml
MYCAT常用的分片规则如下:
(1)分片枚举: sharding-by-intfile
(2)主键范围约定: auto-sharding-long 此分片适用于,提前规划好分片字段某个范围属于哪个分片
(3)一致性hash: sharding-by-murmur
(4)字符串hash解析: sharding-by-stringhash
(5)按日期(天)分片:sharding-by-date
(6)按单月小时拆分: sharding-by-hour
(7)自然月分片: sharding-by-month
(8)取模: mod-long 此规则为对分片字段求摸运算
(9)取模范围约束: sharding-by-pattern 此种规则是取模运算与范围约束的结合,主要为了后续数据迁移做准备,即可以自主决定取模后数据的节点分布
id
mod-long
2
测试总共插入四条数据。结果显示。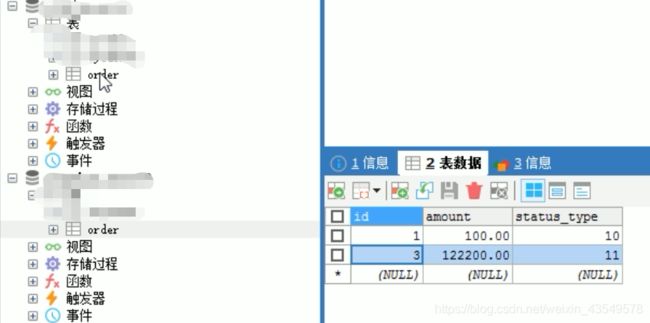
存在问题:通常项目中主键的生成有可能是自增的,但是此处是不同的数据,存在主键序列问题。涉及全局序列与跨库join问题。 所以不同的数据库需要使用同一个序列。
全局序列:
三种方式:
本地文件:mycat内存中文件,其帮助计数,设置计数器,但是如果mycat一旦宕机就出现了问题。
数据库方式: 在数据库中建立一张表进行设置序列,但是存在问题,效率慢
时间戳方式:通过时间创建主键,但是主键特别长,主键长度:18位。官方默认
时间戳配置:
2
数据库方式:
1.官方脚本:
DROP TABLE IF EXISTS MYCAT_SEQUENCE;
CREATE TABLE MYCAT_SEQUENCE (
NAME VARCHAR (50) NOT NULL,
current_value INT NOT NULL,
increment INT NOT NULL DEFAULT 100,
PRIMARY KEY (NAME)
) ENGINE = INNODB ;
DROP FUNCTION IF EXISTS `mycat_seq_currval`;
DELIMITER ;;
CREATE FUNCTION `mycat_seq_currval`(seq_name VARCHAR(50))
RETURNS VARCHAR(64) CHARSET utf8
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR) ) INTO retval
FROM MYCAT_SEQUENCE WHERE NAME = seq_name;
RETURN retval ;
END
;;
DELIMITER ;
DROP FUNCTION IF EXISTS `mycat_seq_nextval`;
DELIMITER ;;
CREATE FUNCTION `mycat_seq_nextval`(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
CHARSET utf8
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END
;;
DELIMITER ;
DROP FUNCTION IF EXISTS `mycat_seq_setval`;
DELIMITER ;;
CREATE FUNCTION `mycat_seq_setval`(seq_name VARCHAR(50), VALUE INTEGER)
RETURNS VARCHAR(64) CHARSET utf8
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = VALUE
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END
;;
DELIMITER ;
2.初始化语句
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('GLOBAL', 100000, 100);3.修改官方默认的主键生成策略
1
0-本地文件方式
1-数据库方式
2-时间戳方式:
4.使用方式
插入语句:
insert into `order`(id,amount,status_type) values( 1304771120184037376,1000,10);项目使用:
数据库配置:
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.url=jdbc:mysql://xxx:8066/DB?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=xxxxx!
spring.datasource.driver-class-name=com.mysql.jdbc.Driver跨库join:
第一种情况:全局表
设定为全局的表,会直接复制给每个数据库一份,所有操作也会同步给多个库。 所以全局表一般不能是大数据表或者更新频繁的表 一般是字典表或者系统表为宜。
配置: schema.xml
select user()
select user()
第二种方式:ER表
为了相关联的表尽量分在一个库下
配置:schema.xml
select user()
select user()
第三种方法:federated引擎 分布式引擎 两库不在同一个机器上的表进行关联
1.开启引擎
修改my.cnf
在[mysqld]下增加一行
federated
然后重启mysql
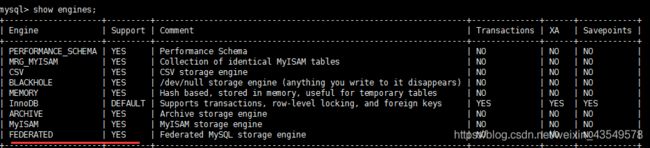
建表:设置引擎
create table test_2(id int,name varchar(200)) engine=federated CONNECTION="mysql://root:[email protected]:3306/数据库A/test_2"使用时的注意事项:
1. 本地的表结构必须与远程的完全一样。
2.远程数据库目前仅限MySQL
3.不支持事务
4.不支持表结构修改
最大的问题:性能