线程池工作流程及线程复用原理
Java常用的线程池
1.线程池的作用
线程池的作用就是限制运行线程的数量;
创建一个符合需求的线程池,可以有效的提高系统运行的效率;
利用同步队列控制线程的执行与销毁;
为什么使用线程池会提高效率?
1.重用存在的线程,减少对象创建、销毁的开销,性能佳;
2.根据系统的承载能力,调整线程池中的线程数目,避免开启太多线程;
3.提供定时执行、定期执行、单线程、并发数控制等功能;
为了便于跨大量上下文使用,此类提供了很多可调整的参数和扩展钩子 (hook)。但是,强烈建议程序员使用较为方便的 Executors 工厂方法 Executors.newCachedThreadPool()(无界线程池,可以进行自动线程回收)、Executors.newFixedThreadPool(int)(固定大小线程池)Executors.newSingleThreadExecutor()(单个后台线程),它们均为大多数使用场景预定义了设置
需要注意的是:Java里的线程池的顶级接口是Executor,但是严格讲Executor并不是一个线程池,而是一个工具,其类里面都是静态方法且构造器被private。真正的线程池接口是ExecutorService
2.几个重要的线程类
①ExecutorSerivice:线程池的真正接口
②ThreadPoolExecutor:ExcutorService的实现类
③ScheduledExecutorService:解决需要重复执行的任务
④ScheduledThreadPoolExecutor:继承自ThreadPoolExecutor且实现ScheduledExecutorService接口,周期性任务调度的实现;
3.四种常用线程池
3.1——newCachedThreadPool
创建一个带缓存的无界线程池,但会重用以前构造的线程可用(即可自动进行线程回收)。 这些池通常会提高性能,执行许多短期异步任务的程序。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
ThreadPoolExecutor()方法的底层实现为:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
根据源码可以得知传入的每个参数的意义:
corePoolSize:核心线程池中保留的线程数(默认为0)
maximumPoolSize:线程池中允许存放的最大线程数(默认最大)
ThreadPoolExecutor可根据传入的corePoolSize和maximumPoolSize自动调整池的大小。当新任务方法execute(Runnable r)中提交,
Ⅰ:如果运行线程小于corePoolSize,则创建新线程来处理请求,即使其他辅助线程也是空闲的。
Ⅱ:如果运行线程多余corePoolSize但小于maximumPoolSize,则仅当队列满时才创建新线程。
Ⅲ:如果设置corePoolSize=maximumPoolSize,则创建了固定容量的线程池。
Ⅳ:如果将maximumPoolSize设置为最基本的无界值(Integer.MAX_VALUE),则允许线程池适应任意数量的并发数;
keepAliveTime:多余空闲线程的最大存活时间(默认60S)
当线程数有多出corePoolSize的线程,则这些多出来的线程在空闲时间超过keepAliveTime时将会终止。
unit:keepAliveTime的时间单位
workQueue:用于在任务之前保存任务的阻塞队列
defaultThreadFactory():默认的线程工厂
defaultHandler:达到线程边界或队列容量时阻止线程
3.2——newFixThreadPool
创建一个固定数量线程的线程池,在任何时候最多只有n个线程线程存活在线程池中,如果在所有线程都活动之外再提交了其他任务,新的线程将在队列中等待,直到线程可用;
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
3.3——newSingleThreadPool
创建一个使用单个线程工作的线程池(关闭无限队列),所有的任务按照指定的顺序(FIFO、LIFO、优先级)执行;
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
3.4——newScheduledThreadPool
创建一个可以定期执行线程的线程池;
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
通过上述的介绍之后,除过输入参数中的阻塞队列(后续会介绍),其他的东西也都很清晰,对于线程池的实现,如下所示:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CashPool {
static volatile int x=0;
public static void main(String[] args) {
//可缓存线程池
ExecutorService es1=Executors.newCachedThreadPool();
for(int i=0;i<3;i++){
es1.execute(new Runnable() {
@Override
public void run() {
System.out.println("可缓存线程池线程"+Thread.currentThread().getName()+"已运行");
}
});
}
//固定数量线程池
ExecutorService es2=Executors.newFixedThreadPool(3);
for(int i=0;i<3;i++){
es2.execute(new Runnable() {
@Override
public void run() {
System.out.println("固定数量线程池"+Thread.currentThread().getName()+"已运行");
}
});
}
//定期执行线程池
ExecutorService es3=Executors.newScheduledThreadPool(2);
for(int i=0;i<3;i++){
es3.execute(new Runnable() {
@Override
public void run() {
System.out.println("定期执行线程池"+Thread.currentThread().getName()+"已运行");
}
});
}
//单线程线程池
ExecutorService es4=Executors.newSingleThreadExecutor();
for(int i=0;i<3;i++){
es4.submit(new Runnable() {
@Override
public void run() {
System.out.println("单线程池"+Thread.currentThread().getName()+"已运行");
}
});
}
}
}
----------------------------------------------------------------------------------
可缓存线程池线程pool-1-thread-3已运行
可缓存线程池线程pool-1-thread-2已运行
可缓存线程池线程pool-1-thread-1已运行
固定数量线程池pool-2-thread-1已运行
固定数量线程池pool-2-thread-2已运行
固定数量线程池pool-2-thread-3已运行
定期执行线程池pool-3-thread-1已运行
定期执行线程池pool-3-thread-1已运行
定期执行线程池pool-3-thread-1已运行
单线程池pool-4-thread-1已运行
单线程池pool-4-thread-1已运行
单线程池pool-4-thread-1已运行
4.线程池的工作流程
- 线程池刚刚创建之后,里面没有线程。任务队列是作为参数传进来的。不过,就算是有线程线程池也不会立刻执行线程;
- 当调用execute()方法时,线程池会做出以下判断:
a.如果运行的线程数小于corePoolSize,那么马上创建线程运行这个任务;
b.如果当前线程池中的线程数大于或等于corePoolSize,那么会将这个任务放入队列;
c.如果这个时候队列已满,而正在运行的线程数小于maximumPoolSize,那么还是会创建非核心线程来运行这个任务;反之,如果正在运行的线程数大于或等于maximumPoolSize,那么就会抛出异常RejectExcutionException;
d.当一个线程完成后,会在队列头里取得下一个线程执行;
e.当一个线程无事可做,超出一定的时间(keepAliveTime),线程池会判断,如果运行的线程数大于corePoolSize,那么这个线程将会被结束掉。所以线程数的所有任务完成后,它最终会收缩corePoolSize 的大小。
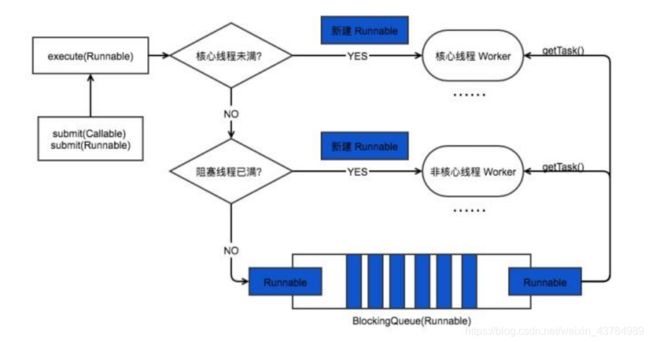
5.线程池的线程复用
在平时使用线程池的时候,都是以excute(Runnable r)的方式进行的,并不能看出线程池如何维持线程运行或者任何重用线程。so,源码带我们走进神秘的世界:
- 先看execute(Runnable r)的实现
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* 线程池加载线程的三个策略:
* 1.当工作线程数少于corePoolSize 立刻创建新线程运行
* 2.如果不能创建新线程运行,那么就将该线程加入到等待workQueue队列等待调用执行、
* 3.如果二次检查recheck线程池停止工作则需要移除线程
* 4.如果无法提交线程,就需要使用拒绝策略reject
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
可以看出来,在execute()方法中,使用到的执行线程的方法是addWorker(command,true),他才是重用线程的重点,所以我们可以跟进去看一下addWorker()方法:
- 首先 ,addWorker()方法属于ThreadPoolExecutor的一个内部类
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable{
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker 线程中断
this.firstTask = firstTask; //初始化任务
this.thread = getThreadFactory().newThread(this); //通过线程工厂生产线程
}
}
作为一个final的类,worker不支持被继承,也就是说在JDK中只有这一个类可以用来处理线程池中的重用线程;
再来看看addWorker()方法的细节:
/*
* 这里省略一部分代码,原因是 这一部分代码是判断型,用来判断线程池状态,其线程是否可以被添加。
* 下面的代码才是重点!!!
*/
private boolean addWorker(Runnable firstTask, boolean core) {
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask); //将要执行的线程封装进worker对象中
final Thread t = w.thread; //拿到worker对象中封装的线程
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
//再次检验锁 线程工厂 的状态是否符合要求
int rs = runStateOf(ctl.get());
//当获取到的状态码显示线程池关闭或者线程阻断 但firstTask还要运行
//那么就抛异常。否则添加worker对象到 HashSet中,将workeradd添
//加状态置为ture表示已经添加线程
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//t.start() => Worker.start()
//所以就将逻辑转换到worker内部执行
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
}
从上面的代码可以看出,将传入的线程添加工作队列后,执行线程是在worker内部中:
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
这里的run是重写Runnable里面的run方法,通过调用run执行线程体
在RunWorker方法中传入Worker对象,进行线程重用:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread(); //拿到线程属性
Runnable task = w.firstTask; //拿到任务
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
//判断线程池是否停止 并执行相应的拒绝策略
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
//好的,这里我们会看见task任务被执行,那么task任务是在何时被拿出来的尼?
//答案是在while循环判断的时候 task=getTask()
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
这个方法分为两部分:
-
一个大的while循环,判断条件是
task!=null || (task=getTask())!=null,task自然就是我们要执行的任务。当task==null && (task.getTask())==null的时候,循环结束;循环体里面会执行task.run(); -
线程池一直在运行其实就是while循环一直没有断,所以当有外部任务进来的时候,就可以取得线程并且执行;
最后来看一下getTask()方法,它是重用线程的关键:
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
除过前面所有的判断,获取任务的操作来到了Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();这一步,工作队列workQueue会一直去请求任务,属于核心线程的会一直卡在workQueue.take()方法,直到拿到Runnable然后返回,非核心线程会poll()。如果超出keepAliveTime还没有拿到线程就会返回null,当判断拿到线程即Runnable!=null,则返回Runnable;
从以上代码可以总结getTask()的作用为:如果当前活动线程数大于核心线程数,当去缓存队列中取任务的时候,如果缓存队列中没有任务,在等待keepAliveTime的时长之后还没有任务则返回null,这就意味着runWorker()方法退出,其对应的线程就会被销毁。只要线程池中的线程数大于corePoolSize,则会一直这样执行下去;
总结来说,线程池中的复用原理如下:
1.线程池执行execute(Runnable r)方法,将需要执行的任务传入该方法中;
2.execute()中判断线程符合要求后,调用addWorker(Runnable r,boolean core);
3.作为内部类Worker利用构造函数可以封装出一个Worker对象包含线程信息;
4.将符合要求的线程加入到HashSet < Workers >中,使用t.start()执行线程;
5.t.start()将逻辑转换到Worker内部类中,重用run()方法,调用runWorker()执行;
6.runWorker()方法中在while循环条件中尝试获取任务;
7.根据任务获取成功或失败来增加或消除线程直到线程数=corePoolSize;
6.线程池中的数量真的是越多越好吗?
答案当然是不行的。当任务需要使用线程池的资源时,比如数据库连接。过多的连接请求线程池执行任务也会导致频繁的上下文切换,CPU消耗大。
-
IO密集型
cpu使用率较低,程序中出现大量的IO操作占据时间导致线程空余而没有利用,但是却被IO占用着,所以通常就需要开两倍的CPU数的线程,当线程进行IO操作时其他线程可以继续使用CPU,提高CPU的可利用率;所以:
最佳线程数目 = ((线程等待时间+线程CPU时间)/ 线程CPU时间)X CPU数目 -
CPU密集型
CPU使用率较高(一些复杂运算,逻辑处理等),所以线程数一般只需要等于CPU的数量即可。
在高并发、任务执行短的情况下,设置线程数 = CPU+1,减少线程上下文的切换
在并发不高、任务执行时间长的情况下:
- 如果是IO密集型,则设置两倍的CPU数量的线程;
- 如果时执行时间长,则设置的线程数应该和CPU数量一致;