基于Box Supervision的弱监督图像语义分割
简介
为什么要“弱监督”做图像语义分割
让我们来看看论文怎么说的。
ICCV 2015 BoxSup[1], “But pixel-level mask annotations are time-consuming, frustrating, and in the end commercially expensive to obtain.”
ICCV 2015 WSSL[2], “Acquiring such data is an expensive, time-consuming annotation effort.”
CVPR 2017 SDI[3], “Compared to object bounding box annotations, pixel-wise mask annotations are far more expensive, requiring ∼ 15× more time. Cheaper and easier to define, box annotations are more pervasive than pixel-wise annotations.”
CVPR 2019 BCM[4], “Unlike other classic visual tasks such as classification and object detection, labeling semantic seg- mentation is rather expensive.”、“For example, the cost of labeling a pixel-level segmentation annotation is about 15 times larger than labeling a bounding box, and 60 times than labeling an image class.”
核心观点如下:
- 深度学习方法需要大量的标注数据。
- 标注pixel-level(像素级别)的类别标签(即图像语义分割标注)是极其耗时的,成本非常高。
- 标注Bounding Box(边界框)或标注image level(图像级别)类别标签成本要低很多,标注一幅图像的bounding box或一幅图像的类别标签要比语义分割标注快15倍或60倍。
讲一个趣事,某大牛退休时,每天会定时标注一幅图像(像素级别的类别标签,图像语义分割),像绣花一样,标注了几个月,然后每次做PPT时都会和大家说这件事,说我标注的这幅图像已经精确的不能再精确了,没人敢说标注得有我的好。忘了大牛叫啥了。
基于Box Supervision的弱监督图像语义分割
上面的四篇论文均介绍了基于Box Supervision做的弱监督图像语义分割,这些论文的核心思路是基于Bounding box标注信息使用一些算法(如MCG、GrabCut、DenseCRF等)生成Region Proposals来当作Fake Ground Truth,计算loss,反向传播梯度,训练backbone网络(如VGG16、ResNet101等)。
由于这些论文中生成Region Proposals的技术是没有用到数据集中的Ground Truth,因此是弱监督的,
总结几点:
- Fake Ground Truth与Ground Truth存在Gap。
- BoxSup、WSSL、SDI、BCM在全监督的baseline的不同,在Pascal VOC验证集上,BoxSup mIOU=63.8,WSSL=67.6,SDI=69.1,BCM=69.8。前三篇可以说是没区别,第四篇做的很精细,但是均没有解决最大的上面所说的Gap问题。
- WSSL挺solid的,复现与论文基本一致。SDI的M&G+,复现结果与论文一致。WSSL的Bbox-Seg数据集和SDI的M&G+数据集作者release出来,但是没有release出具体的生成算法。
BoxSup[1]
资源链接
- pdf:BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation
- 博客:
- BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation读书笔记
- 论文笔记 | BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentati
框架
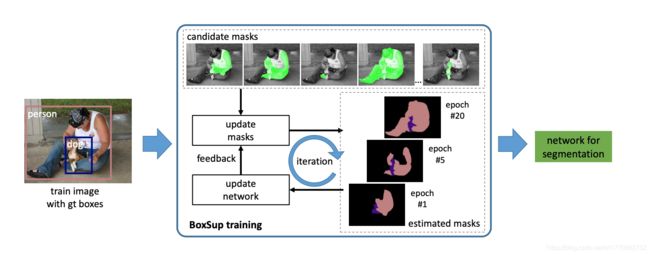
对于一幅图像,首先是用一些技术(如Selective Search、MCG等)生成若干(2k)个candidate masks(候选区域mask,图中上方绿色部分)。接着,在训练过程中,采用一种策略从candidate masks中挑选一个当作Ground Truth(图中update masks),计算pixel-level的分类损失(如softmax交叉熵损失函数),反向传播训练网络(图中update network)。
损失函数
pixel-level的分类损失函数
ε ( θ ) = ∑ p e ( X θ ( p ) , l ( p ) ) \varepsilon(\theta)=\sum_{p}e(X_{\theta}(p),l(p)) ε(θ)=p∑e(Xθ(p),l(p))
p p p 表示像素的下标即该像素属于图像中的 p p p 个, l ( p ) l(p) l(p) 表示ground truth第 p p p 个像素所属的类别, X θ ( p ) X_{\theta}(p) Xθ(p) 表示网络预测的第 p p p 个像素所属的类别, θ \theta θ 表示网络的参数。 ε ( θ ) \varepsilon(\theta) ε(θ) 具体可理解成像素级别的softmax交叉熵损失函数。
衡量candidate masks和bounding box的损失函数
ε o ( θ ) = 1 N ∑ S ( 1 − I o U ( B , S ) ) δ ( l B , l S ) \varepsilon_{o}(\theta)=\frac{1}{N}\sum_{S}(1-IoU(B, S))\delta(l_B,l_S) εo(θ)=N1S∑(1−IoU(B,S))δ(lB,lS)
S S S 表示candidate masks,B表示bounding boxes, I o U ( B , S ) IoU(B, S) IoU(B,S) 表示B和S的交并比。 δ \delta δ等于1,如果B和S的所属类别相同,否则等于0。对于一幅图像的每个bounding box,只有一个S为非背景。当像素被多个bounding box覆盖时,该像素属于面积最小的bounding box所属的类别。
选取condidate masks当Ground Truth的pixel-level分类损失函数
ε r ( θ ) = ∑ p e ( X θ ( p ) , l S ( p ) ) \varepsilon_r(\theta)=\sum_{p}e(X_{\theta}(p),l_S(p)) εr(θ)=p∑e(Xθ(p),lS(p))
这个损失函数即第一个公式,区别就是从candidate masks中选取一个当作ground truth,从而计算这个损失。选取策略使 ε o + λ ε r \varepsilon_{o} + \lambda\varepsilon_{r} εo+λεr 最小,由于一幅图像产生2k个candidate masks S,因此在训练过程中选取 ε o + λ ε r \varepsilon_{o} + \lambda\varepsilon_{r} εo+λεr 最小的5个 S,再从这5个中随机选取1个 S 当作ground truth。
这个函数目的在于从candidate masks当中选取与bounding box最相近的S。
最后的损失函数
m i n ∑ i ( ε o + λ ε r ) min \sum_{i}(\varepsilon_{o} + \lambda\varepsilon_{r}) mini∑(εo+λεr)
i i i 表示训练集中第i个图像, λ = 3 \lambda=3 λ=3。
实验结果

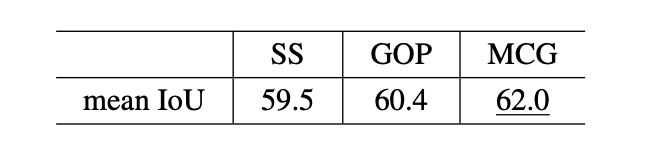
在Pascal VOC12验证集上能使用Multiscale Combinatorial Grouping(MCG)生成candidate masks mIOU达到62.0,使用Selective Search(SS)和Geodesic Object Proposals(GOP)分别为59.5,60.4。
其最高的mIOU=62.0,全监督的mIOU=63.8。
注:最终的结果使用了Dense CRF[6]做post-process,Dense CRF高大上点说可以增强模型预测的分割Mask的空间连续性,通俗点说就是以模型预测的分割Mask以及一些高斯核参数作为输入,输出增强后的分割Mask,详情可见论文。
总结
- 训练速度很慢,因为要对2k个candidate masks计算 ε o + λ ε r \varepsilon_{o} + \lambda\varepsilon_{r} εo+λεr。
- 论文使用的网络为VGG16,其使用ground truth的全监督训练验证集结果才63.8,很低。这样该论文与WSSL(67.6)、SDI(69.1)、BCM(69.8)不能粗暴地做对比,虽然他们都是用的VGG16,但是WSSL、SDI、BCM是DeepLab-LargeFOV的大感受野的VGG16,这篇论文是DeepLab-SmallFOV的小感受野的VGG16。
WSSL[2]
资源链接
- pdf:Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
- 源码:deeplab-v1-caffe-code
- 训练好的模型:DeepLab_Models
- 博客:
- 论文阅读笔记:Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
- 【论文总结】weakly- and semi-supervised learning of a DCNN for semantic Image Segmentation
框架
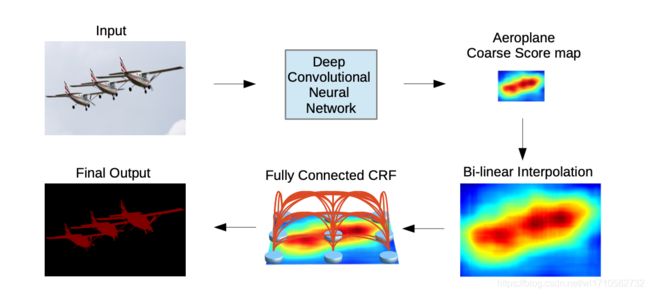
对于一幅图像(图中Input),经过一个网络(Deep Convolution Neural Network,即DCNN),此时会得到相应类别的Score map,再经过双线性插值(Bi-linear Interpolation)恢复成原图像大小,最后经过Dense CRF[6](Fully Connected CRF)做后处理,得到分割后的Mask(图中的Final Output)。
举例详细来说的话,输入一幅RGB图像,大小为 3 ∗ H ∗ W 3*H*W 3∗H∗W,经过VGG16(即DCNN,下采样3次,每次图像缩小2倍),输出大小为 C ∗ H 8 ∗ W 8 C*\frac{H}{8}*\frac{W}{8} C∗8H∗8W的feature maps,对每个channel进行softmax之后,再取每个channel的最大值所在的类别,即可得到最后的大小为 H 8 ∗ W 8 \frac{H}{8}*\frac{W}{8} 8H∗8W的score map,再经过双线性插值(上采样8倍),得到大小为 H ∗ W H*W H∗W的score map,最后Dense CRF做后处理即可得到最后的分割Mask。
对于这篇论文来说,图像输入大小为 3 ∗ 321 ∗ 321 3*321*321 3∗321∗321, C = 21 C=21 C=21,Pascal VOC共20类物体+1类背景。
注:由于WSSL的Box Supervision部分是基于DeepLab-V1[5]这篇论文,因此我把DeepLab-V1的框架拿了过来,易于理解。
损失函数
s p c = exp f ( x p c ) ∑ c = 0 C − 1 exp ( f ( x p c ) ) s_p^c =\frac{\exp f(x_p^c)}{\sum_{c=0}^{C-1}\exp(f(x_p^c))} spc=∑c=0C−1exp(f(xpc))expf(xpc)
J ( θ ) = ∑ p y p c log s p c J(\theta)=\sum_{p}y_p^c \log s_p^c J(θ)=p∑ypclogspc
y p c y_p^c ypc 表示ground truth图像中第 p 个像素属于第 c 个类别, f ( x p c ) f(x_p^c) f(xpc)表示网络输出的feature maps(大小为 H 8 ∗ W 8 \frac{H}{8}*\frac{W}{8} 8H∗8W)第 c 个feature map中第 p 个像素的值。
注:ground truth要下采样8倍,成 H 8 ∗ W 8 \frac{H}{8}*\frac{W}{8} 8H∗8W,用的是最近邻插值。这个公式是我看源码理解写的公式。
Bbox-Rect和Bbox-Seg
由于WSSL的创新点使用EM算法来估计Fake Ground Truth有自相矛盾的地方,因此不介绍其EM算法。
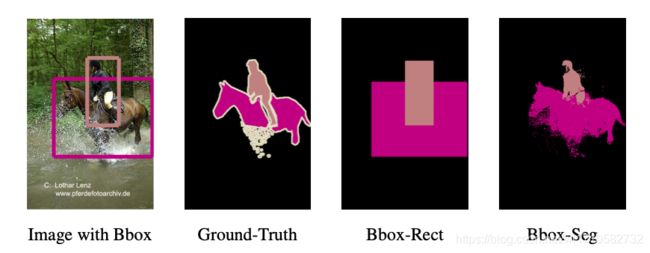
这篇论文用到的弱监督思想很简单,构造了Bbox-Rect和Bbox-Seg两个数据集,然后用上面的全监督的框架训练网络。
- Bbox-Rect数据集:使用标注好的bounding box来当作ground truth,bbox外的像素是属于背景这一类;bbox里的像素和该bbox一个类别,如果一个像素被多个bbox覆盖,则该像素属于面积小的bbox的类别。
- Bbox-Seg数据集:在Bbox-Rect数据集的基础上,使用Dense CRF处理,最终即可得到Bbox-Seg数据集。还有一个处理是bbox中心的20%的像素类别和该bbox一致,bbox外的像素是属于背景这一类。
实验结果
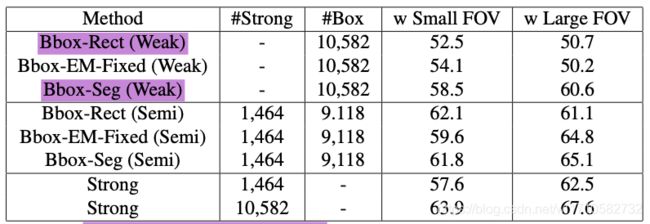
该论文使用了VGG16的Small FOV和Large FOV两个版本,在Large FOV上,Bbox-Rect在Pascal VOC12验证集上mIOU=50.7,Bbox-Seg的mIOU=60.6,全监督(Strong)mIOU=67.6。我复现过,与论文所说一致。
总结
- 该论文创新点是使用了EM算法来估计Fake Ground Truth,进而使用Fake Ground Truth当作Ground Truth全监督地训练网络。但是在Box Supervision中,加了EM,在Small FOV版本的VGG16上有用(52.5-54.1),在Large FOV版本的VGG16上没有用(50.7-50.2)。
- 该论文公开了Bbox-Rect和Bbox-Seg两个数据集,因为这两个数据集是弱监督得到的,因此我直接计算了这两个数据集的验证集和Ground Truth的验证集之间的mIOU,Bbox-Rect为62.2,Bbox-Seg为71.1。论文的实验结果Bbox-Rect才50.7,Bbox-Seg才60.6。
SDI[3]
资源链接
- pdf:Simple Does It: Weakly Supervised Instance and Semantic Segmentation
- 源码:官方release;非官法的tensorflow代码
- 博客:
- 【论文笔记】Simple Does It: Weakly Supervised Instance and Semantic Segmentation
框架
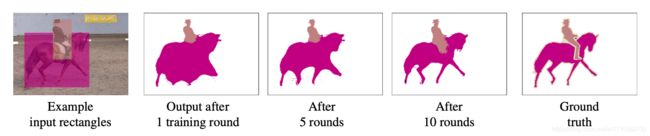
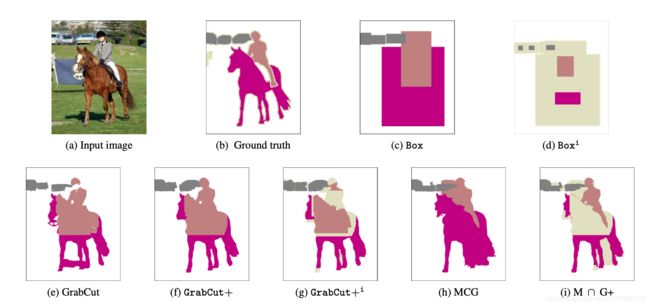
这篇论文的框架和WSSL一致,只是用不同的弱监督算法生成Region Proposals当作Fake Ground Truth,如MCG、GrabCut等。下面简单介绍一下不同的生成Region Proposals的算法:
- Box:其实和WSSL的Bbox-Rect一致,bounding box外的像素全是属于背景类别,bounding box里面的像素和bbox的类别一致。如果一个像素同时被多个bbox覆盖,则该像素类别和面积最小的bbox类别一致。见上图 ( c ) (c) (c)。
- Boxi:在上面Box的基础上,添加忽略区域(Pascal VOC的分割Mask边界也是忽略区域,像素值为255)。Bounding box外的像素类别为背景。Bounding box中心20%的区域像素类别与bbox类别一致,bbox内部其余像素为忽略区域。见上图 ( d ) (d) (d)。
- GrabCut:使用GrabCut算法生成。Bounding box外的像素类别是背景。见上图 ( e ) (e) (e)。
- GrabCut+:使用改进后的GrabCut算法生成。Bounding box外的像素类别是背景。见上图 ( f ) (f) (f)。
- GrabCut+i:使用改进后的GrabCut算法生成,添加忽略区域,方法与Boxi一致。Bounding box外的像素类别是背景。见上图 ( f ) (f) (f)。
- MCG:使用MCG(Multiscale Combinatorial Grouping)算法生成。Bounding box外的像素类别是背景。见上图 ( h ) (h) (h)。
- M ⋂ \bigcap ⋂G+:MCG算法生成的Region Proposals和 GrabCut+算法生成的做交集。见上图 ( i ) (i) (i)。
这篇论文训练方法与WSSL的一致,即把这些算法生成的Region Proposals当作Fake Ground Truth,用全监督的方法训练,和DeepLab-V1一致。Box和Boxi训练了多轮。
每一轮的意思是:
- 首先拿Box或Boxi的数据训练到收敛。
- 如果预测的分割Mask和Fake Ground Truth的IOU小于50%,再将Box或Boxi当作Fake Ground Truth训练。
- 如果预测的分割Mask和Fake Ground Truth的IOU大于等于50%,使用Dense CRF做后处理用增强后的分割Mask当作Fake Ground Truth。
比如,在训练一轮完毕后,会有一些训练集的Bounding box满足和Box或Boxi的IOU大于等于50%,有一些不满足。
注:GrabCut,GrabCut+i,MCG,M ⋂ \bigcap ⋂G+论文中提到训练一轮的性能就很不错,训练方法和WSSL的Bbox-Rect、Bbox-Seg一致,即训练到收敛+Dense CRF后处理。Box和Boxi训练了多轮。
实验结果
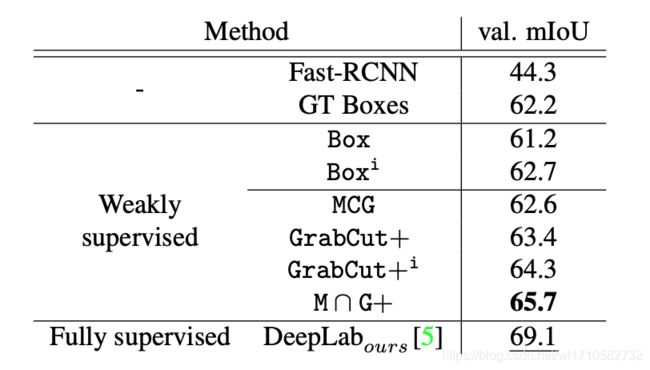
在Pascal VOC12验证集上的mIOU。M ⋂ \bigcap ⋂G+该数据集,论文release了出来,按照WSSL的Bbox-Rect和Bbox-Seg方法训练完毕后,再使用Dense CRF后处理mIOU=65.7,其全监督的mIOU=69.1。
总结
- DeepLabours表示DeepLab-V1的LargeFOV的,论文的Pascal VOC mIOU=69.1比DeepLab-V1论文的67.6高了1.5个点。因此论文的Box和Boxi结果为61.2和62.7,其实和WSSL的Bbox-Rect的60.6应当属于一个level。虽然论文是训练了多轮。
- 论文创新点应该是实验很多,挺充分,例如GrabCut,GrabCut+i,MCG,M ⋂ \bigcap ⋂G+等实验。
BCM[4]
资源链接
- pdf:Box-driven Class-wise Region Masking and Filling Rate Guided Loss for Weakly Supervised Semantic Segmentation
- 博客:
- Box-driven Class-wise Region Masking and Filling Rate Guided Loss for Weakly Supervised Semantic Seg
框架

这篇论文很精细。首先是根据bounding box和Dense CRF生成Region Proposals当作Fake Ground Truth(例如WSSL的Bbox-Seg数据集),见上图 ( b ) (b) (b)。然后根据这些Region Proposals计算各个物体(一个bounding box对应一类物体)在bounding box的填充比例(Filling
Rates即占比) F R i , i 为 各 个 类 别 FR_i,i为各个类别 FRi,i为各个类别,见图 ( c ) (c) (c),狗填充比例为50%,猫的填充比例为62.3%。
下面说一下整体流程:
- 输入图像( 3 ∗ H o r a l ∗ W o r a l 3*H_{oral}*W_{oral} 3∗Horal∗Woral),经过FCN作为backbone),输出feature maps ( C 1 ∗ H ∗ W C1*H*W C1∗H∗W,下采样8倍),见图 ( d ) (d) (d)。
- 对backbone的feature maps接上几层卷积网络,输出 N N N 个分支 F 1 , F 2 , . . , F i , . . . , F N F_1,F_2,..,F_i,...,F_N F1,F2,..,Fi,...,FN, F i F_i Fi 大小为 C 2 ∗ H ∗ W C2*H*W C2∗H∗W,接着分别对每个分支预测一个attention map α i \alpha_i αi,大小为 H ∗ W H*W H∗W,用对应类别的bounding box约束,最后对每个 F i F_i Fi 与相应的 α i \alpha_i αi做一个 spatial-wise masking乘积,得到对应的 ϕ i \phi_i ϕi,大小为 H ∗ W H*W H∗W,见图 ( e ) (e) (e)。
- 如果不使用 F R i FR_i FRi 约束,将 ϕ 1 , . . . , ϕ i , . . . , ϕ N \phi_1, ..., \phi_i, ..., \phi_N ϕ1,...,ϕi,...,ϕN 组合起来即可得到最后的score maps,大小为 N ∗ H ∗ W N*H*W N∗H∗W,再与Fake Ground Truth计算loss,反向传播梯度。
- 使用 F R i FR_i FRi 约束,这时需要考虑每一类的填充比例,很简单,只需要计算每一个score map的值最大的前 F R i FR_i FRi 个像素的score值与对应Fake Ground Truth的loss, 反向传播梯度。
损失函数
BCM损失
即用bounding box约束 α i \alpha_i αi的MSE损失函数:
L b c m ( i ) = ∑ h = 1 H ∑ w = 1 W ∣ ∣ M i ( h , w ) − α i ( h , w ) ∣ ∣ 2 2 L_{bcm(i)}=\sum_{h=1}^{H}\sum_{w=1}^{W}||M_i(h, w)-\alpha_i(h, w)||_2^2 Lbcm(i)=h=1∑Hw=1∑W∣∣Mi(h,w)−αi(h,w)∣∣22
M i ( h , w ) M_i(h, w) Mi(h,w)即图像中第 i i i类在 h , w h, w h,w位置的bounding box mask值,值为0或1,0表示背景,1表示这一类的前景。
FR损失
即用填充比列约束的损失函数:
F R i = 1 N i ∑ i = 1 i = N i P p r o p o s a l ( i ) P b o x ( i ) FR_i=\frac{1}{N_i}\sum_{i=1}^{i=N_i}\frac{P_{proposal(i)}}{P_{box(i)}} FRi=Ni1i=1∑i=NiPbox(i)Pproposal(i)
注:这个 N i N_i Ni表示训练集中第 i i i 类的bounding box的数量,即每一类的平均填充比例。区别与前面的 N N N 表示类别标签数量,论文公式与框架图不一致,统一用 i i i 表示第 i i i 个类。
L f r = ∑ i = 1 N ∑ j = 1 t o p ( F R i ) L i ( j ) L_{fr}=\sum_{i=1}^{N}\sum_{j=1}^{top(FR_i)}L_i(j) Lfr=i=1∑Nj=1∑top(FRi)Li(j)
注:此时的 L i L_i Li 为前面所介绍的基于pixel-level的多分类损失,即softmax交叉熵损失函数。
最后的损失函数
L a l l = L f r + λ ∑ i = 1 N L b c m ( i ) L_{all} = L_{fr} + \lambda \sum_{i=1}^{N}L_{bcm(i)} Lall=Lfr+λi=1∑NLbcm(i)
注:论文更精细的把每一类又划分出各个子类,因为每一类物体由于形状的不同,其填充比例也不同。我这里就不再做叙述,详情可见论文。
实验结果
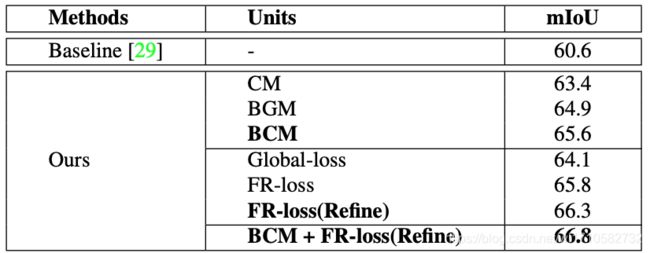
在消去实验中,会发现BCM和FR-loss均起到了作用。
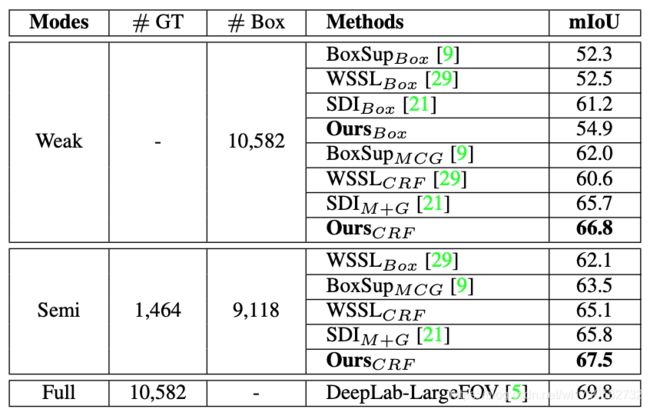
在Pascal VOC12的验证集上,其最后的mIOU=66.8,是现在的SOTA。其依然使用了Dense CRF做后处理,其全监督的mIOU=69.8。

总结
- BCM这篇论文做得很精细,可以说是在WSSL的BBox-Seg数据集上,通过使用attention map预测的每一类的mask更趋向于前景。通过使用每一类的不同填充比例这个先验知识,使得预测的每一类mask更趋向于中间一团的形状。
- 这篇论文最后预测的分割mask趋向于一团的情况,在不加Dense CRF的情况下,其预测的边缘是不如Boxsup、WSSL和SDI的。
- 这篇论文很精细,没有release源码,担心其是否solid,是否能很简单的train出来还是得需要大量的调参数。
参考
[1]Dai, Jifeng, Kaiming He, and Jian Sun. “Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
[2]Papandreou, George, et al. “Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation.” Proceedings of the IEEE international conference on computer vision. 2015.
[3]Khoreva, Anna, et al. “Simple does it: Weakly supervised instance and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[4]Song, Chunfeng, et al. “Box-driven class-wise region masking and filling rate guided loss for weakly supervised semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[5]Chen, Liang-Chieh, et al. “Semantic image segmentation with deep convolutional nets and fully connected crfs.” arXiv preprint arXiv:1412.7062 (2014).
[6]Krähenbühl, Philipp, and Vladlen Koltun. “Efficient inference in fully connected crfs with gaussian edge potentials.” Advances in neural information processing systems. 2011.