机器学习评估指标AUC与Precision、Recall、F1之间的关系
目录
- 数学推导
- 实验说明
-
- 实验一
- 实验二
- 实验代码
- 实验结果
- 总结
AUC、 Precision、Recall、F1等都是机器学习中常用的模型评估指标,本文通过数学推导和实验结果探讨AUC与Precision、Recall、F1等的关系。
数学推导
假设r为recall,p为precision,预测阈值为0.5,
TP、TN、FP、FN如下图所示:
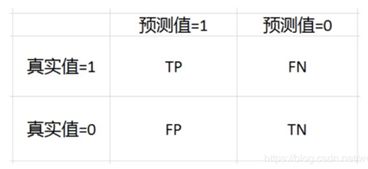
假设一共有N个样本,正负样本各一半,当正负样本比例不是1:1时,下面的推导过程也适用。首先,使用r和p表示TP、TN、FP、FN,公式如下:
T P = N 2 ⋅ r TP = \frac{N}{2}\cdot r TP=2N⋅r
F N = N 2 ⋅ ( 1 − r ) FN = \frac{N}{2}\cdot (1-r) FN=2N⋅(1−r)
F P = N 2 ⋅ r ⋅ ( 1 p − 1 ) FP = \frac{N}{2}\cdot r \cdot (\frac{1}{p}-1) FP=2N⋅r⋅(p1−1)
T P = N 2 − N 2 ⋅ r ⋅ ( 1 p − 1 ) TP = \frac{N}{2} - \frac{N}{2}\cdot r \cdot (\frac{1}{p}-1) TP=2N−2N⋅r⋅(p1−1)
根据AUC的含义,它表示随机分别选取一个正样本和一个负样本,正样本的预测值高于负样本的预测值的概率,我们将这个事件记为A。 我们随机抽取一个正样本和一个负样本,一共有四种可能性。
B1:正样本TP,负样本TN
B2:正样本TP,负样本FP
B3:正样本FN,负样本TN
B4:正样本FN,负样本FP
于是有:
A U C = P ( B 1 ) ⋅ P ( A ∣ B 1 ) + P ( B 2 ) ⋅ P ( A ∣ B 2 ) + P ( B 3 ) ⋅ P ( A ∣ B 3 ) + P ( B 4 ) ⋅ P ( A ∣ B 4 ) AUC=P(B1) \cdot P(A|B1)+ P(B2) \cdot P(A|B2)+ P(B3) \cdot P(A|B3)+ P(B4) \cdot P(A|B4) AUC=P(B1)⋅P(A∣B1)+P(B2)⋅P(A∣B2)+P(B3)⋅P(A∣B3)+P(B4)⋅P(A∣B4),
其中 P ( A ∣ B 1 ) = 1 P(A|B1)=1 P(A∣B1)=1, P ( A ∣ B 4 ) = 0 P(A|B4)=0 P(A∣B4)=0, P ( A ∣ B 2 ) P(A|B2) P(A∣B2) 和 P ( A ∣ B 3 ) P(A|B3) P(A∣B3)皆刻画了模型预测的稳定程度,我们记为t,取值在0和1之间。通常模型性能越好,t也越大。
这样我们就得到了AUC关于r、p的计算公式:
A U C = r + t + r 2 ⋅ ( 1 p − 1 ) ⋅ ( 2 t − 1 ) − r t p AUC=r+t+r^2 \cdot {(\frac{1}{p}-1)}\cdot(2t-1)-\frac{rt}{p} AUC=r+t+r2⋅(p1−1)⋅(2t−1)−prt
实验说明
实验一
1、选取iris的label为0和1的两类,共100条数据,一半作为训练集,一半作为测试集。0和1类的样本比例为1:1
2、对数据进行增广,将训练集扩充为2000条,测试集扩为200条。增广的方式为添加高斯噪声,噪声的均值为0,标准差从1增加至15。这样得到15组实验数据。
3、在每组实验数据上训练感知器模型,评估模型效果,计算AUC、F1、Precision、Recall
等指标。绘图对比指标变化趋势。
实验二
使用实验一得到的15组Precision、Recall估计AUC,并与真实的AUC比较,验证数学推导是否正确。我们假定confidence随着noise的标准差发生指数衰减,即 t = 初 始 值 ∗ ( 衰 减 因 子 ) 噪 声 标 准 差 t=初始值*(衰减因子)^{噪声标准差} t=初始值∗(衰减因子)噪声标准差。
实验代码
## 模型评估指标实验
# 对iris进行数据增广,噪声的标准差作为实验参数,在增广数据上训练感知器模型并评估模型效果。
# 对比不同噪声下AUC、F1、Precision、Recall的变化情况
import sklearn
from sklearn import datasets
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.neural_network import MLPClassifier
#加载iris数据集
#iris数据集为一个用于识别鸢尾花的机器学习数据集
#通过四种特征(花瓣长度,花瓣宽度,花萼长度,花萼宽度)来实现三种鸢尾花的类别划分
iris = datasets.load_iris()
#iris.data大小为150*4,代表4种特征
#这里只提取后两类特征
X = iris.data[0:100]
#标签
y = iris.target[0:100]
#划分训练集和测试集
#random_state = 0表示不设定随机数种子,每一次产生的随机数不一样
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size = 0.5, random_state = 0)
sc = StandardScaler()
sc.fit(X_train) # 估算每个特征的平均值和标准差
X_train_std = sc.transform(X_train)
# 注意:这里我们要用同样的参数来标准化测试集,使得测试集和训练集之间有可比性
X_test_std = sc.transform(X_test)
def augment(X_train_std,y_train,std=1,repeat=1):
X_aug=np.zeros((len(X_train_std)*repeat,len(X_train_std[0])))
y_aug=np.zeros((len(y_train)*repeat,))
for i in range(repeat):
noise=np.random.multivariate_normal(np.zeros((4,)),std*np.eye(4,4),size=len(X_train_std))
X_aug[i*len(X_train_std):(i+1)*len(X_train_std)]=X_train_std+noise
y_aug[i*len(X_train_std):(i+1)*len(X_train_std)]=y_train
return X_aug,y_aug
f1=[]
ps=[]
rc=[]
auc=[]
for i in range(15):
X_aug,y_aug=augment(X_train_std,y_train,std=i+1,repeat=40) #set noise std as i+1
X_train_aug=np.concatenate((X_aug,X_train_std),axis=0)
y_train_aug=np.concatenate((y_aug,y_train))
X_aug2,y_aug2=augment(X_test_std,y_test,std=i+1,repeat=4) #set noise std as i+1
X_test_aug=np.concatenate((X_aug2,X_test_std),axis=0)
y_test_aug=np.concatenate((y_aug2,y_test))
clf = MLPClassifier(random_state=1, max_iter=100).fit(X_train_aug, y_train_aug)
# 分类测试集,这将返回一个测试结果的数组
y_pred=clf.predict_proba(X_test_aug)
y_pred_class=list(map(lambda x: 1 if x>0.5 else 0, y_pred[:,1].tolist()))
auc_value=roc_auc_score(y_test_aug, y_pred[:,1])
f1_value=f1_score(y_test_aug, y_pred_class)
p=precision_score(y_test_aug, y_pred_class)
r=recall_score(y_test_aug, y_pred_class)
auc.append(auc_value)
f1.append(f1_value)
ps.append(p)
rc.append(r)
# 计算模型在测试集上的准确性
print('Iter %d: '%i)
print("AUC: %.4f"%auc_value)
print("Accuracy: %.4f"%accuracy_score(y_test_aug, y_pred_class))
print("Precision: %.4f"%p)
print("Recall: %.4f"%r)
print("F1: %.4f"%f1_value)
# --------- Visualization --------
# plot logloss curve
import matplotlib.pyplot as plt
plt.figure()
plt.title("AUC vs F1")
x=[i+1 for i in range(15)]
plt.plot(x,auc)
plt.plot(x,f1)
plt.plot(x,ps)
plt.plot(x,rc)
plt.legend(['AUC','F1','Precision','Recall'])
plt.xlabel('Noise Std')
plt.xticks(x)
plt.tight_layout()
plt.show()
#estimate AUC
#compare real auc and estimated auc
def cal_auc(x,i,init_cfd=0.9,decay=0.99):
p=x[0]
r=x[1]
t=init_cfd*decay**i
print(t)
return r+t+r**2*(1.0/p-1.0)*(2*t-1)-r*t/p
init_cfd=0.95
decay=0.97
auc_est=[cal_auc(x,i+1,init_cfd,decay) for i,x in enumerate(zip(ps,rc))]
# --------- Visualization --------
# plot logloss curve
import matplotlib.pyplot as plt
plt.figure()
plt.title("AUC Estimation")
x=[i+1 for i in range(15)]
plt.plot(x,auc)
plt.plot(x,auc_est)
plt.legend(['AUC','Estimated AUC'])
plt.xlabel('Noise Std')
plt.xticks(x)
plt.show()实验结果
实验一
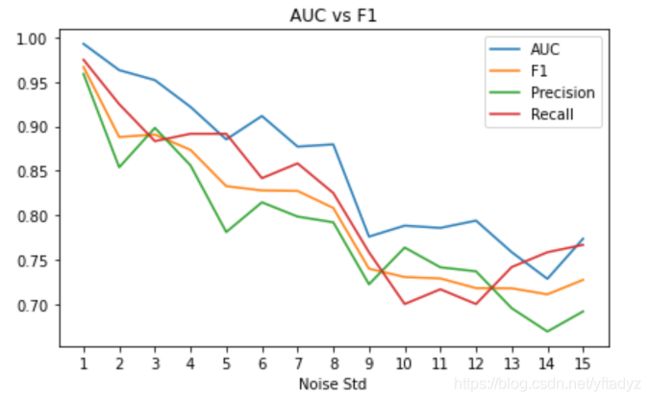
从实验结果可以看到,随着噪声的增大,AUC、F1、Precision、Recall都在下降。F1基本是Precision和Recall的均值,这从F1的定义就可以得知。比较有趣的现象是,AUC一直高于F1,并且一直相差0.05左右。
实验二

从上图可以看到,估计的AUC和真实的AUC非常接近,这证明我们的数学推导是正确的。
总结
本文推导了AUC的计算公式,从推导过程可以看到AUC、TP、TN、FP、FN、Precision、Recall、F1这些评估指标的相互关系。通过iris上的小实验我们验证了推导过程是否正确。